

Lær om forskellen mellem statistik og maskinlæring
Maskinindlæring bruges effektivt inden for forskellige områder som fondsopsporing, websøgeresultater, realtidsannoncer på websider og mobile enheder, tekstbaseret følelsesanalyse, kreditvurdering og næste-bedste tilbud, forudsigelse af udstyrsfejl, nye prismodeller, netværksintrusiondetektion, mønster- og billedgenkendelse og spamfiltrering via e-mail blandt andre felter. Statistik defineres som studiet af indsamling, analyse, fortolkning, præsentation og organisering af data. Når statistikker anvendes til et videnskabeligt, industrielt eller samfundsmæssigt problem, begynder processen normalt med at beslutte en statistisk population eller en statistisk modelproces.
Statistik vs maskinlæring -
Data ændrer og udvikler sig konstant. Men det er meget vigtigt at tilpasse sig disse ændringer, fordi data er et kritisk aspekt af væksten i virksomheder over hele kloden.
Data defineres som almindelige fakta og statistikker, der indsamles under den daglige drift af et brand / firma. Mens næsten alle typer virksomheder indsamler data, er det meget vigtigt for mærker at give mening om den mening.
Uden at være i stand til at udlede nogen indsigt og viden fra dataene, bliver de helt ubrugelige. Det er grunden til, selv hvis virksomheder har en masse information og data, taber de nogle gange, fordi de ikke er i stand til at fornemme dem.
Siden etableringen indsamler virksomheder en masse information og data om forskellige ting som kundeinformation, produkthøjdepunkter, partnerproblemer og medarbejderfeedback.
Disse data og oplysninger kan effektivt bruges til at registrere og måle en omfattende vifte af forretningsfunktioner, hvad enten det er eksternt eller internt. På sine egne data er ikke meget informativ, men det er et grundlag, hvorpå virksomheder kan tage fremtidige beslutninger og udvikle vellykkede strategier.
Kunder er det grundlag, hvorpå mærker byggede deres navn og værdi på markedet. Derfor er kundedata ekstremt vigtige, da de giver mærker mulighed for at forbedre og forstå deres kunder på en række forskellige måder.
Data er derfor den eneste måde, hvorpå virksomheder forstår mange aspekter af virksomhedsfunktioner som f.eks. En række forespørgsler, modtagne indtægter, modtagne udgifter blandt andet.
Data er derfor vigtigt for mærker for at forstå kundens tankegang og forventninger. Alt i alt er data et vigtigt element for at sikre enhver virksomheds fortsatte succes og vækst, især i denne konkurrencedygtige alder og tid.
Artiklen om statistik vs maskinlæring er struktureret som nedenfor -
- Statistik vs Machine Learning Infographics
- Hvad er forskellen Statistik kontra maskinlæring?
- Et mere dybtgående kig på statistikker og dens betydning i samfundet
- Et mere dybtgående kig på maskinlæring og dens betydning i samfundet
- Konklusion - Statistik vs maskinlæring
Statistik vs Machine Learning Infographics
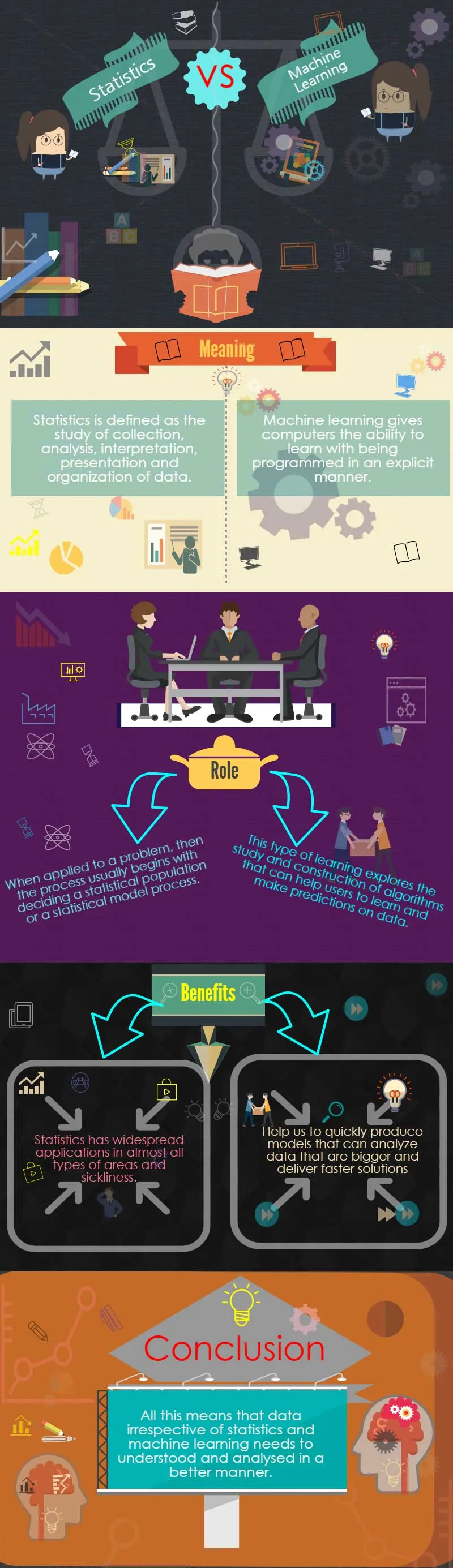
Er data og information den samme? Hvad er forskellen Statistik kontra maskinlæring?
Data og information er to forskellige ting. Mens data er rå fakta og statistikker, er information de samme data, der præsenteres på en nøjagtig og rettidig måde.
Yderligere er information specifik og organiseret, generelt udført med det formål at give kontekst og forståelse til et bestemt aspekt af brandets funktion. En anden måde, hvorpå information adskiller sig fra data, er, at det er gennem informationen, at mærker kan tage rigtige beslutninger og oprette kampagner, der er kreative, effektive og engagerende.
Derfor er information så vigtig, da det giver mærker mulighed for at træffe beslutninger, som ledelsen kan bruge til virkelig at styrke sig selv.
Det er grunden til, at mærker stræber efter at indsamle information om kunder og klienter, så de kan samarbejde med dem på en effektiv måde. Alt dette er det vigtigt at huske, at den sande værdi af information ligger i dens evne til at give retning til virksomheden.
Hvis der for eksempel mangler kundetilfredshed i henhold til kundernes oplysninger, er det kun nyttigt, hvis mærket ændrer denne opfattelse ved at tilbyde en bedre værdi for deres produkter og tjenester.
Kort sagt skal informationsprocessen indgå i en bredere gennemgangsproces inden for virksomhederne, så den kan hjælpe dem med at producere bedre og mere rentable resultater.
Derfor kan information indsamles og analyseres på forskellige måder, der er maskinlæring og statistik.
Fra personer, der bor i et land til atomer indeholdt i en krystal, kan befolkningen være af forskellige typer. At håndtere alle aspekter af data som planlægning af dataindsamling til eksperimenter er statistik et varieret og omfattende felt.
Maskinlæring er på den anden side et underfelt i datalogi, der har udviklet sig fra studiet af computational learning theory i kunstig intelligens og mønstergenkendelse.
Arthur Samuel i 1959 definerede maskinlæring som det studieretning, der giver computere mulighed for at lære med at blive programmeret på en eksplicit måde.
Denne type læring udforsker undersøgelse og konstruktion af algoritmer, der kan hjælpe brugerne med at lære og komme med forudsigelser om data. Sådanne algoritmer fungerer ved en modeloprettelse og bruges til at foretage datadrevet forudsigelse snarere end at følge statiske programinstruktioner.
Anbefalede kurser
- Kursus i IP Routing
- Hacking-træningskurser
- Kursus i RMAN
- Online certificeringskursus i Python

Et mere dybtgående kig på statistik og maskinlæring
Statistik spiller en meget vigtig rolle på næsten alle områder af menneskelig aktivitet. Fra hjælp til at bestemme et lands indbygger til beskæftigelsesfrekvensen til det antal medicinske / skolefaciliteter, der kræves i en region, har statistik og maskinindlæring en meget vigtig rolle i det menneskelige samfunds funktion.
I den aktuelle tid har statistik en meget vigtig og kritisk position inden for en række områder, herunder handel, handel, psykologi, kemi, botanik, astronomi blandt mange andre.
Dette skyldes, at statistik har et bredt anvendelsesområde inden for næsten alle typer områder og sygelighed. Her er nogle vigtige områder, hvor statistik og maskinlæring kan anvendes til at indsamle bedre information og indsigt.
- Erhverv: Statistik har en meget vigtig og kritisk rolle at spille inden for forretningsområdet. Dette skyldes, at mærker og virksomheder er ekstremt konkurrencedygtige, hvilket gør det vanskeligt for mærker at holde sig foran deres kunders forventninger og ønsker. Det er derfor vigtigt, at mærker tager hurtige beslutninger, så de kan træffe bedre beslutninger. Statistik kan hjælpe mærker med at forstå kundens forventninger og derved balansere deres efterspørgsel og udbud på en effektiv måde. Dette betyder, at mange af brandets beslutninger afhænger af gode statistiske beslutninger og indsigter.
- Økonomi: Et andet vigtigt område, hvor statistik spiller en vigtig rolle i økonomien. Dette skyldes, at statistik i vid udstrækning afhænger af statistikker. Dette skyldes, at nationalindkomstkonti er vigtige indikatorer for økonomer og administratorer. Statistiske metoder anvendes til udarbejdelse af disse konti og endda til indsamling og analyse af data. Forholdet mellem udbud og krav studeres gennem statistisk analyse, og næsten alle aspekter af økonomien kræver en stor og indviklet forståelse af statistikker.
- Matematik: Statistik er en integreret del af natur-og samfundsvidenskab. Metoderne for naturvidenskab er pålidelige, men deres konklusioner er undertiden ikke så sandsynligvis fordi de er baseret på ufuldstændige beviser. Statistisk hjælp til at beskrive disse målinger på en præcis måde. En masse statiske metoder som sandsynlighedsgennemsnit, spredning, estimering er en integreret del af matematikken og bruges ofte på dette felt.
- Bankvirksomhed: Et andet område, hvor statistikker spiller en vigtig rolle i bankvirksomheden. Banker kræver statistik af en række grunde og formål. Næsten alle banker arbejder på princippet om, at når en af deres kunder investerer nogle penge i deres bank, vil de opbevare dem i deres bank i nogen tid og ikke trække dem ud. Ved at tjene penge på disse indskud tjener banken overskud, og dette er den vigtigste kilde til deres indtægter. Bankfolk bruger statistiske tilgange baseret på sandsynlighed for at estimere antallet af indskydere og deres krav i en bestemt dag, hvilket giver dem mulighed for at fungere på en glat og effektiv måde.
- Statsledelse: Statistik er et andet område, der er essentielt for vækst og udvikling i ethvert land. Dette skyldes, at statistikker er grundlaget for, hvilke politikker der udarbejdes i landet. Derfor bruges statistiske data i vid udstrækning til at tage administrative beslutninger. For eksempel, hvis regeringen ønsker at hæve lønnskalaen for ansatte for at hjælpe dem med at øge deres levestandard, er det gennem statistikker, at regeringen kan finde en stigning i leveomkostningerne. Derudover afhænger forberedelsen af de føderale og provinsielle regeringsbudgetter også af statistikker, fordi det hjælper embedsmændene med at estimere de forventede udgifter og indtægter fra forskellige kilder. Så statistikker er meget vigtige for at hjælpe regeringerne med at udføre deres opgaver på en glat måde.

Et mere dybtgående kig på maskinlæring og dens betydning i samfundet
Computere og bærbare computere har taget hele verden med storm og har drastisk ændret mange menneskers liv. Lad os visualisere en situation i et minut. Lad os prøve at tænke på en verden uden computere.
Hvis dette skete, ville folk i det medicinske felt ikke have fundet en hel del kur mod sygdomme, fordi computere har spillet en vigtig rolle i processen med at hjælpe medicinske fagfolk med at få bedre indsigt i verdenen af sygdomme og helbred.
Igen ville film som Toy Story og Jurassic Park ikke have været muligt uden computere, fordi disse film har gjort brug af computergrafik og animation.
Apoteker ville have svært ved at holde styr på, hvilke medicin de skal give til deres patienter. At tælle stemmer ville være næsten umuligt uden computere, og endnu vigtigere af rumforskning ville stadig have været en fjern drøm for alle rumentusiaster.
På grund af den voksende betydning af computere har computerteknologier fået en endnu større rolle, og dette har resulteret i maskinernes evne til automatisk at anvende komplekse matematiske beregninger på big data i et hurtigere og hurtigere tempo.
Nogle af de vidt omtalte eksempler på applikationer til maskinlæring, der i dag er ekstremt populære i verden, inkluderer følgende:
- Essensen af maskinlæring er den ekstremt populære Google-selvdrevne bil
- Online anbefalingstilbud, der er tilpasset platforme som Amazon og Netflix, er et resultat af applikationer til maskinlæring, der nu er egnet til at forstå den daglige menneskelige opførsel
- At forstå kundeadfærd på Twitter for mærker og nu maskinlæring med sproglig regelskabelse hjælper mærker med at forstå og styrke deres kunder i det offentlige område
- Svigpåvisning er et vigtigt felt, hvor maskinlæring hjælper mærker med at være sikre og effektive på tværs af alle platforme
I dag er der en voksende interesse for maskinlæring, fordi i dag de voksende mængder og sorter af tilgængelige data, databehandling har resulteret i et behov for billigere og kraftfulde dataanalysemetoder.
Dette betyder, at maskinlæring kan hjælpe os med hurtigt at producere modeller, der kan analysere større data og levere hurtigere løsninger, der er nøjagtige og effektive, selv i stor skala.
Alt dette betyder, at forudsigelser af høj værdi kan hjælpe økonomier og mærker til at træffe bedre og smartere beslutninger, ikke kun uden menneskelig indgriben, men også i realtid.
Mærker har brug for hurtig bevægelige modelleringsstrømme for at følge med markedets krav, og de kan gøre dette på en effektiv måde ved hjælp af maskinlæring.
Mens mennesker generelt kan oprette en eller to gode modeller om ugen, kan maskinlæring skabe tusinder af modeller om ugen, hvilket også gør mærker mere effektive og bedre på lang sigt.
Maskinindlæring adskiller sig derfor meget fra datastatistikker. Enkelt sagt, mens maskinlæring bruger de samme algoritmer og teknikker, er der en stor forskel mellem disse to statistikker vs maskinlæringsteknikker.
Mens dataudvinding opdager tidligere ukendte mønstre og viden, bruges maskinlæring til at gengive kendte mønstre og viden.
Disse mønstre anvendes derefter automatisk på andre data, og derefter bruges de til at hjælpe de berørte mennesker med at træffe bedre beslutninger og handlinger.
Med den øgede brug af computere udvikles datateknikker og maskinlæring også hurtigt for at imødekomme behovene hos mærker og virksomheder på tværs af sektorer.
Neurale netværk er længe blevet brugt i applikationer til data mining, og nu med computerenes magt er det muligt at oprette flere neurale netværk, der har mange lag. I maskinlæring af lingo kaldes disse dybe neurale netværk.
Konklusion - Statistik kontra maskinlæring
Alt dette betyder, at data uanset statistik kontra maskinlæring skal forstå og analyseres på en bedre måde. Dette skyldes, at dataindblik er kritisk for succes og fiasko for mærker på tværs af kategorier, og at investere dem er et af de største krav fra alle typer virksomheder.
Anbefalede artikler
Så her er nogle artikler, der hjælper dig med at få mere detaljeret information om statistik vs maskinlæring og også om statistik og maskinlæring, så bare gå gennem linket, der er givet nedenfor.
- Machine Learning vs Statistics
- Karrierer inden for statistik
- Vigtigt trin til investeringsbankers livsstil
- Spørgsmål om statistikintervaller | Nyttige og mest stillede