
Introduktion til datavarehusarkitektur
- Et datavarehus er et lagersted, der indeholder samlinger af flere forskellige slags data, der er erhvervet fra flere typer kilder.
- Hele processen, hvor eksterne datakilder erhverves, behandles, opbevares og analyseres til brugbar information, finder sted inden for et sæt systemer, der er forenet af et enkelt skema kendt som Data Warehouse Architecture.
Datavarehusarkitektur

Datavarehusarkitekturen består generelt af tre niveauer.
- Top klasse
- Mellemklasse
- Nederste niveau
Top klasse
- Top Tier består af klientsiden forenden af arkitekturen.
- De anvendte transformerede og logiske oplysninger, der er gemt i datavarehuset, vil blive brugt og erhvervet til forretningsformål i dette niveau.
- Flere værktøjer til rapportgenerering og analyse er til stede til generering af ønsket information.
- Data mining, som er blevet en stor tendens i disse dage, gøres her.
- Alt krav til analysedokument, omkostning og alle funktioner, der bestemmer en profitbaseret forretningsaftale, udføres baseret på disse værktøjer, der bruger Data Warehouse-informationen.
Mellemklasse
- Det midterste niveau består af OLAP-servere
- OLAP er online analytisk behandlingsserver
- OLAP bruges til at give information til forretningsanalytikere og ledere
- Da det er placeret i Mellemniveauet, interagerer det med rette med informationerne, der findes i bunden, og videregiver indsigt til Top Tier-værktøjerne, der behandler den tilgængelige information.
- Oftest anvendes Relational eller MultiDimensional OLAP i datalagerarkitektur.
Nederste niveau
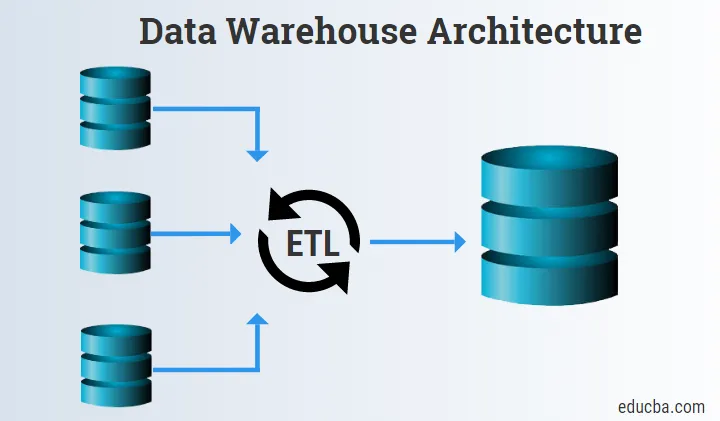
Det nederste niveau består hovedsageligt af datakilderne, ETL-værktøjet og datavarehuset.
1. Datakilder
Datakilderne består af kildedata, der erhverves og leveres til iscenesættelses- og ETL-værktøjerne til videre proces.
2. ETL-værktøjer
- ETL-værktøjer er meget vigtige, fordi de hjælper med at kombinere Logic, Raw Data og Schema til et og indlæser informationen til Data Warehouse eller Data Marts.
- Nogle gange indlæser ETL dataene i datamarkederne, og derefter gemmes oplysninger i datavarehus. Denne tilgang er kendt som Bottom Up-metoden.
- Den tilgang, hvor ETL indlæser information til Data Warehouse direkte, kaldes Top-down Approach.
Forskel mellem top-down-tilgang og bottom-up-tilgang
| Top-Down tilgang | Bund-op-tilgang |
| Tilvejebringer et klart og konsistent billede af information, da information fra datalageret bruges til at oprette datamarkeringer | Rapporter kan nemt genereres, da datamars oprettes først, og det er relativt let at interagere med datamarkter. |
| Stærk model og dermed foretrukket af store virksomheder | Ikke så stærkt, men datavarehus kan udvides, og antallet af datamars kan oprettes |
| Tid, omkostninger og vedligeholdelse er høj | Tid, omkostninger og vedligeholdelse er lav. |
Data Marts
- Data Mart er også en lagringskomponent, der bruges til at gemme data om en bestemt funktion eller del relateret til en virksomhed af en individuel myndighed.
- Datamart samler informationen fra Data Warehouse, og derfor kan vi sige, at datamart gemmer delmængden af information i Data Warehouse.
- Data Marts er fleksible og små i størrelse.
3. Datavarehouse
- Data Warehouse er den centrale komponent i hele Data Warehouse Arkitektur.
- Det fungerer som et lager til at gemme information.
- Store mængder data gemmes i datavarehuset.
- Denne information bruges af flere teknologier som Big Data, som kræver analyse af store undergrupper af information.
- Data Mart er også en model af Data Warehouse.
Forskellige lag af datavarehusarkitektur
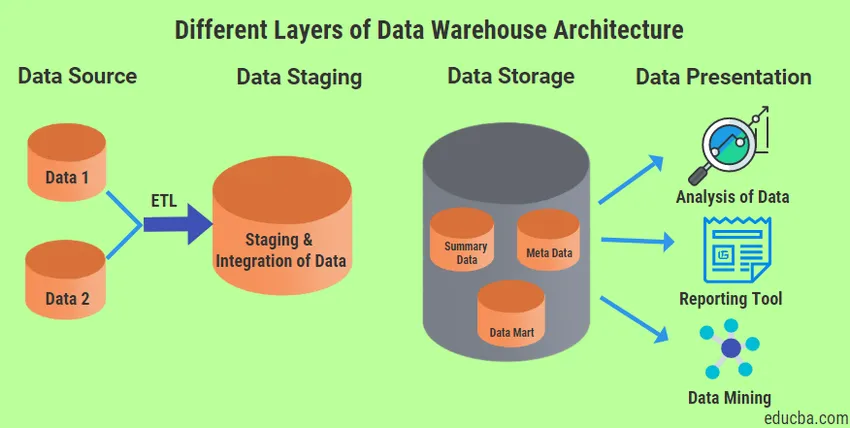
Der er fire forskellige typer lag, som altid vil være til stede i Data Warehouse Architecture.
1. Datakildelag
- Datakildelaget er det lag, hvor dataene fra kilden er stødt på og derefter sendt til de andre lag til ønsket operation.
- Dataene kan være af enhver type.
- Kildedataene kan være en database, et regneark eller enhver anden slags tekstfil.
- Kildedataene kan være af ethvert format. Vi kan ikke forvente at få data med samme format i betragtning af, at kilderne er meget forskellige.
- I det virkelige liv kan nogle eksempler på kildedata være
- Log filer af hver specifik applikation eller job eller indrejse af arbejdsgivere i en virksomhed.
- Undersøgelsesdata, børsdata osv.
- Webbrowser-data og mange flere.
2. Data Staging Layer
Følgende trin finder sted i Data Staging Layer.
1. Dataekstraktion
De data, der er modtaget af kildelaget, føres til iscenesættelseslaget, hvor den første proces, der finder sted med de erhvervede data, er ekstraktion.
2. Landingsdatabase
- De udpakkede data gemmes midlertidigt i en landingsdatabase.
- Det henter dataene, når dataene er trukket ud.
3. Iscenesættelsesområde
- Dataene i landingsdatabasen udtages, og adskillige kvalitetskontrol og iscenesættelsesoperationer udføres i iscenesættelsesområdet.
- Strukturen og skemaet identificeres også, og der foretages justeringer af data, der er uordnet, således at man prøver at få en fælles blandt de data, der er erhvervet.
- At have et sted eller opsætte til dataene lige før transformation og ændringer er en ekstra fordel, der gør iscenesættelsesprocessen meget vigtig.
- Det gør databehandling lettere.
4. ETL
- Det er en ekstraktion, transformation og belastning.
- ETL-værktøjer bruges til integration og behandling af data, hvor logik anvendes til temmelig rå, men noget ordnet data.
- Disse data udvindes i henhold til den analytiske karakter, der kræves og omdannes til data, der anses for at være gemt i datavarehuset.
- Efter transformation bliver dataene eller rettere en information endelig indlæst i datavarehuset.
- Nogle eksempler på ETL-værktøjer er Informatica, SSIS osv.
3. Lagring af data
- De behandlede data gemmes i Data Warehouse.
- Disse data renses, transformeres og udarbejdes med en bestemt struktur og giver således muligheder for arbejdsgivere til at bruge data som krævet af virksomheden.
- Afhængig af arkitekturens tilgang, gemmes dataene i Data Warehouse såvel som Data Marts. Data Marts vil blive diskuteret i de senere faser.
- Nogle inkluderer også en operationel datalager.
4. Lag til datapræsentation
- Dette lag, hvor brugerne kommer til at interagere med de data, der er gemt i datalageret.
- Forespørgsler og flere værktøjer vil blive brugt til at få forskellige typer information baseret på dataene.
- Oplysningerne når brugeren gennem den grafiske repræsentation af data.
- Rapporteringsværktøjer bruges til at få forretningsdata, og forretningslogik bruges også til at indsamle flere slags oplysninger.
- Metadatainformation og systemoperationer og ydeevne opretholdes og ses også i dette lag.
Konklusion
Et vigtigt punkt omkring Data Warehouse er dets effektivitet. For at skabe et effektivt datavarehus konstruerer vi en ramme kendt som forretningsanalyserammen. Der er fire typer visninger med hensyn til design af et datavarehus.
1. Top-Down View: Denne visning tillader kun specifik information, der kræves for at vælge et datavarehus.
2. Datakildevisning: Denne visning viser alle oplysninger fra datakilden til, hvordan de transformeres og gemmes.
3. Datavarehusvisning: Denne visning viser de oplysninger, der findes i datavarehuset gennem faktaborde og dimensionstabeller.
4. Visning af forretningsforespørgsel: Dette er en visning, der viser dataene fra brugerens synspunkt.
Anbefalede artikler
Dette har været en guide til Data Warehouse Architecture. Her diskuterede vi forskellige typer visninger, lag og lag af datavarehusarkitektur. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Karriere inden for datalagring
- Sådan fungerer JavaScript
- Spørgsmål om datalager Interview
- Hvad er Pandas