

Introduktion til funktioner i R
Funktionen er defineret som et sæt udsagn til at udføre og udføre enhver specifik logisk opgave. Funktion tager nogle inputparametre, der er kendt som argumenter for at udføre denne opgave. Funktioner hjælper med at bryde koden i enklere bunker ved at orkestreere den logisk, hvilket er lettere at læse og forstå. I dette emne skal vi lære om funktioner i R.
Hvordan man skriver funktioner i R?
For at skrive funktionen i R er her syntaks:
Fun_name <- function (argument) (
Function body
)
Her kan man se “funktion”, specifikt reserveret ord, der bruges i R, til at definere enhver funktion. Funktionen tager input, som er i form af argumenter. Funktionsorganet er et sæt logiske udsagn, der udføres over argumenter, og derefter returnerer det output. “Fun_name” er det navn, der er givet til funktionen, gennem hvilket det kan kaldes hvor som helst i R-programmet.
Lad os se et eksempel, som vil være mere klar i forståelsen af funktionskonceptet i R.
R-kode
Multi <- function(x, y) (
# function to print x multiply y
result <- x*y
print(paste(x, "Multiply", y, "is", result))
)
produktion:
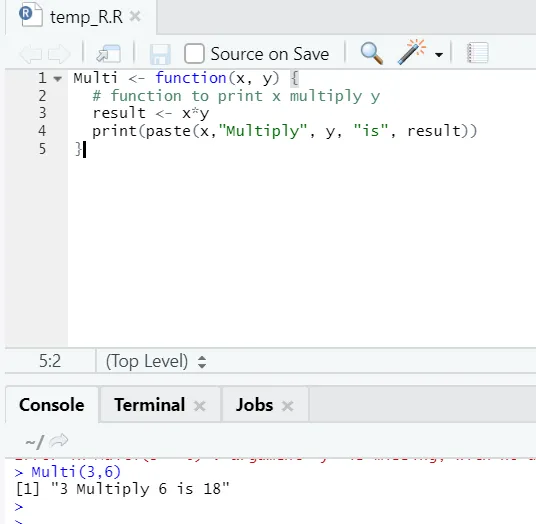
Her oprettede vi funktionsnavnet "Multi", der tager to argumenter som input og giver det multiplicerede output. Det første argument er x, og det andet argument er y. Som du kan se, har vi kaldt funktionen under navnet "Multi". Hvis nogen her ønsker, kan argumenter også indstilles til standardværdien.
Forskellige typer funktioner i R
Forskellige R-funktioner med syntaks og eksempler (indbygget, matematik, statistisk osv.)
1) Indbygget funktion -
Dette er de funktioner, der følger med R til at adressere en bestemt opgave ved at tage et argument som input og give et output baseret på det givne input. Lad os diskutere nogle vigtige generelle funktioner af R her:
a) Sorter: Data kan være af typen til stigende eller faldende rækkefølge. Data kan være, om en vektor af fortsat variabel eller faktor variabel.
Syntaks:

Her er forklaringen på dens parametre:
- x: Dette er en vektor for den kontinuerlige variabel eller faktorvariabel
- faldende: Dette kan indstilles enten sandt / falsk til at styre rækkefølge ved at stige op eller ned. Som standard er det FALSE`.
- sidste: Hvis vektoren har NA-værdier, skal den sættes sidst eller ej
R-kode og output:
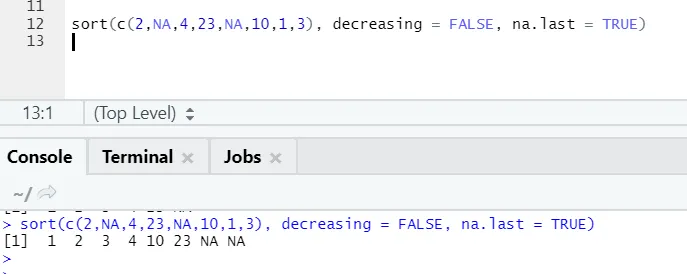
Her kan man bemærke, hvordan “NA” -værdier justeres i slutningen. Som vores parameter na.last = Sandt var sandt.
b) Sekvens: Det genererer en sekvens af antallet mellem to specificerede tal.
Syntaks
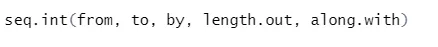
Her er forklaringen på dens parametre:
- fra, til start- og slutværdi af sekvensen.
- af: Forøgelse / mellemrum mellem to på hinanden følgende tal i rækkefølge
- længde.out: den krævede længde af sekvensen.
- Along.with: Henviser til længden fra længden af dette argument
R-kode og output:
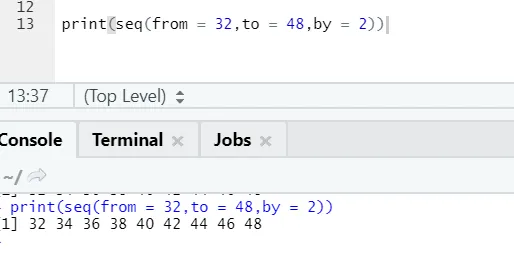
Her kan man bemærke, at den genererede sekvens har inkrementering af 2, fordi by er defineret som 2.
c) Toupper, tolower: De to funktioner: toupper og tolower er funktioner, der anvendes på strengen for at ændre bogstaverne i sætninger.
R-kode og output:
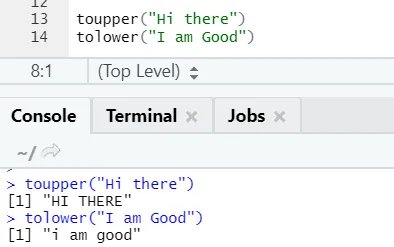
Man kan bemærke, hvordan bogstaverne ændres, når de anvendes til funktionen.
d) Rnorm: Dette er en indbygget funktion, der genererer tilfældige tal.
R-kode og output:
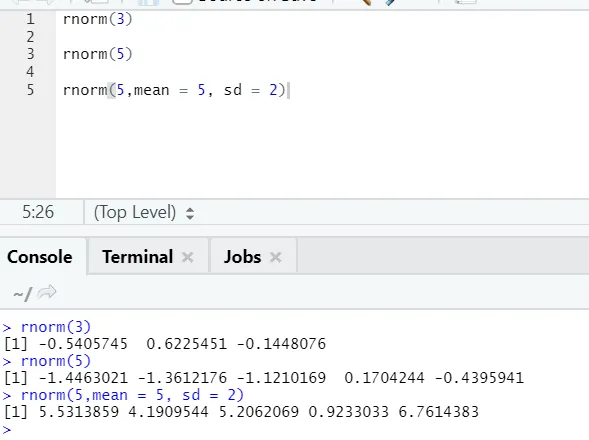
Funktionsnormen tager det første argument, der siger, hvor mange numre der skal genereres.
e) Rep: Denne funktion gentager værdien så mange gange som specificeret.
R-syntaks: rnorm (x, n)
Her repræsenterer x værdien, der skal replikeres, og n repræsenterer det antal gange, det skal replikeres.
R-kode og output:
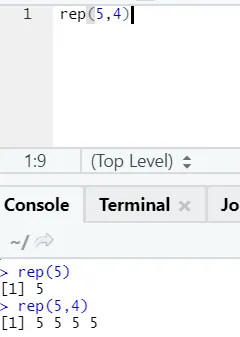
f) Indsæt: Denne funktion er at sammenkæde strenge sammen med en bestemt karakter derimellem.
syntaks
paste(x, sep = “”, collapse = NULL)
R-kode
paste("fish", "water", sep=" - ")
R output:
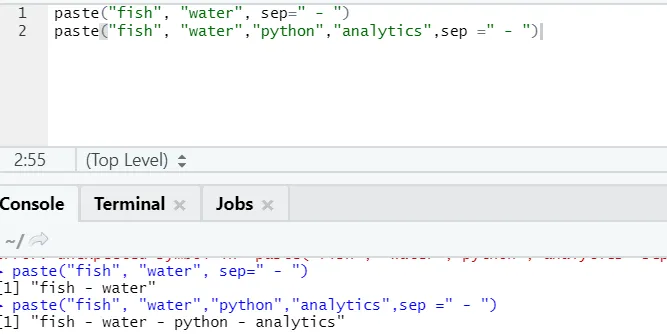
Som du kan se, kan vi også indsætte mere end to strenge. Sep er den specifikke karakter, som vi tilføjede mellem strengene. Som standard er sep plads.
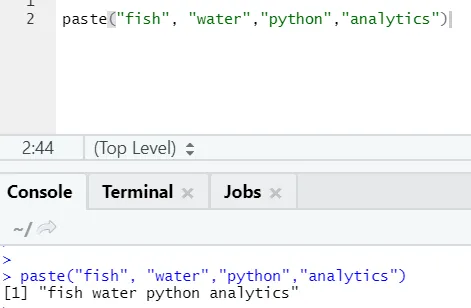
En mere lignende funktion findes som denne, som alle skal være opmærksomme på er paste0.
Funktionspasta0 (x, y, kollaps) fungerer som pasta (x, y, sep = “”, kollaps)
Se eksemplet nedenfor:
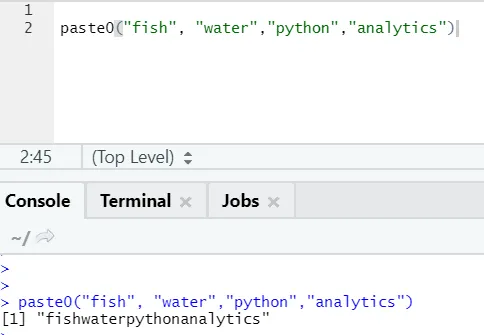
I enkle ord for at opsummere indsæt og sæt ind0:
Indsæt0 er hurtigere end indsæt, når det kommer til sammenkædning af strenge uden nogen separator. Da pasta altid ser efter “sep”, og som som standard er plads i det.
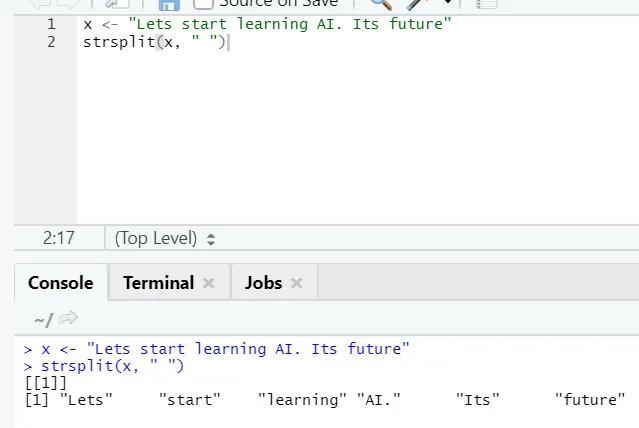
g) Strsplit: Denne funktion er at opdele strengen. Lad os se de enkle sager:
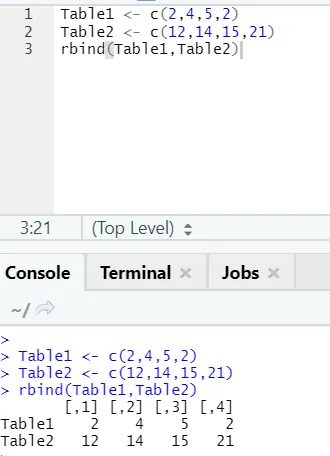
h) Rbind: Funktionen rbind hjælper med at kombinere vektorer med det samme antal kolonner, den ene over den anden.
Eksempel
i) cbind: Dette kombinerer vektorer med det samme antal rækker, side om side.
Eksempel
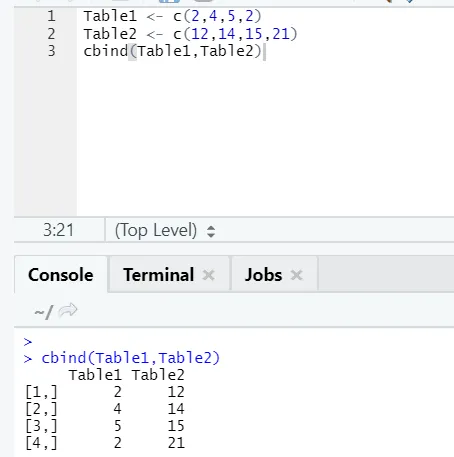
I tilfælde af at antallet af rækker ikke stemmer overens, er nedenunder den fejl, du finder:

Både cbind og rbind hjælper med datamanipulation og omformning.
2) Matematikfunktion -
R leverer en lang række matematiske funktioner. Lad os se et par af dem i detaljer:
a) Sqrt: Denne funktion beregner kvadratroten af et tal eller en numerisk vektor.
R-kode og output:
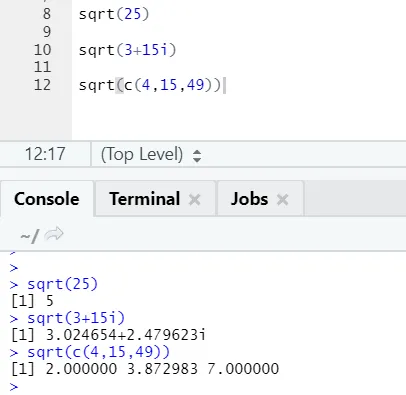
Man kan se, hvordan man kvadratrot af et tal, et komplekst tal og en række af numeriske vektorer er blevet beregnet.
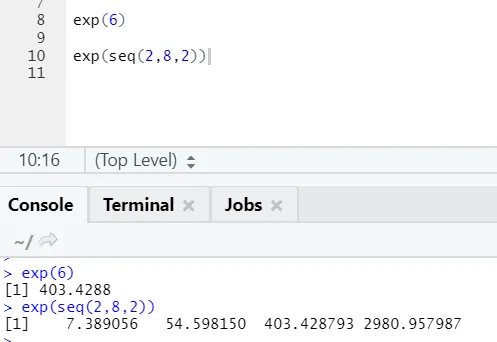
b) Exp: Denne funktion beregner den eksponentielle værdi af et tal eller en numerisk vektor.
R-kode og output:
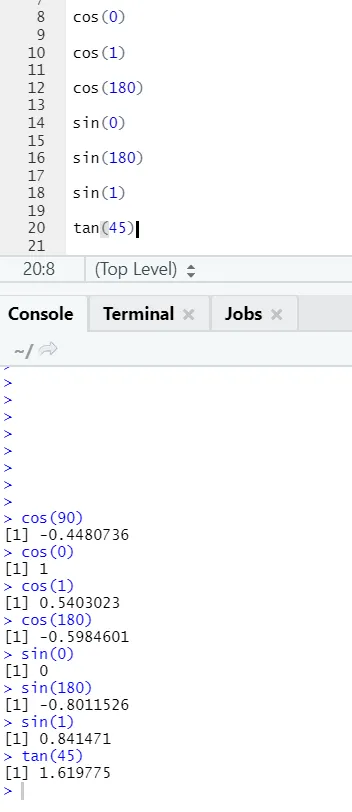
c) Cos, Sin, Tan: Dette er trigonometrifunktioner implementeret i R her.
R-kode og output:
d) Abs: Denne funktion returnerer den absolutte positive værdi af et tal.
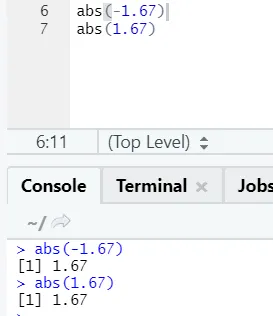
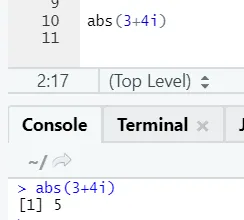
Som du kan se, vil det negative eller positive af et tal returneres i dets absolutte form. Lad os se det for et komplekst tal:
e) Log: Dette er for at finde logaritmen til et tal.
Her er eksemplet, der er vist nedenfor:
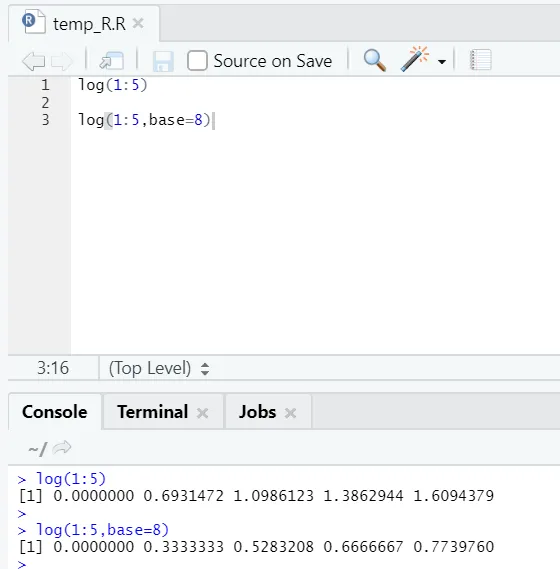
Her får man fleksibiliteten til at ændre basen, som pr. Krav.
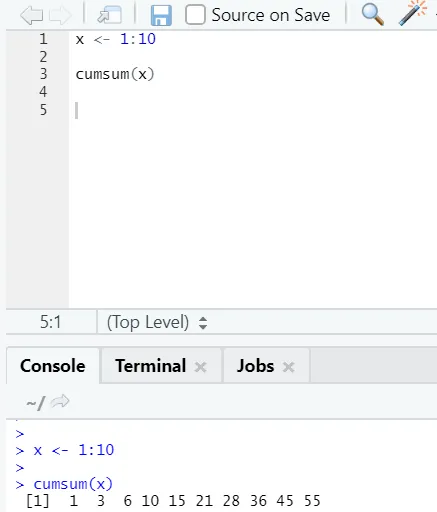
f) Cumsum: Dette er en matematisk funktion, der giver kumulative summer. Her er eksemplet nedenfor:
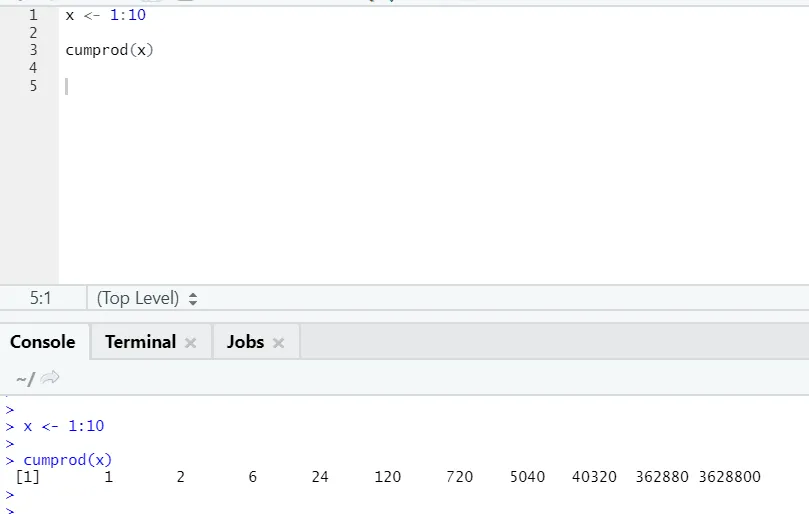
g) Cumprod: Ligesom Cumsum matematisk funktion, har vi cumprod hvor kumulativ multiplikation sker.
Se eksemplet nedenfor:
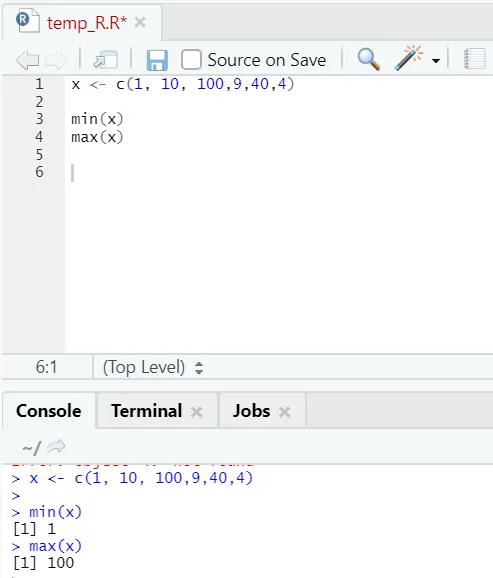
h) Max, Min: Dette hjælper dig med at finde den maksimale / mindste værdi i sæt med numre. Se nedenfor eksemplerne relateret til dette:
i) Loft: Loftet er en matematisk funktion, der returnerer det mindste af heltalet højere end angivet.
Lad se på et eksempel:
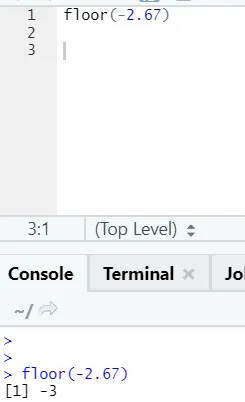
loft (2, 67)
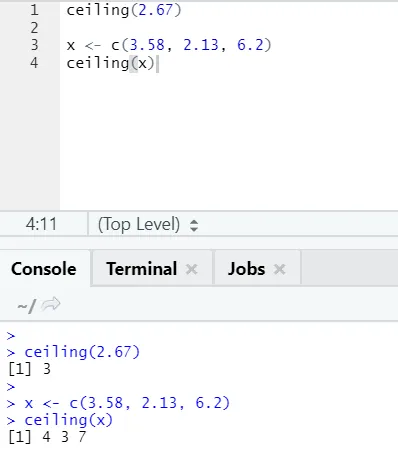
Som du kan bemærke, anvendes loftet over et antal såvel som over en liste, og output, der kom, er det mindste af det næste højere heltal.
j) Gulv: Gulvet er en matematisk funktion, der returnerer det mindste værdi i det tal, der er angivet.
Eksemplet nedenfor vil hjælpe dig med at forstå det bedre:
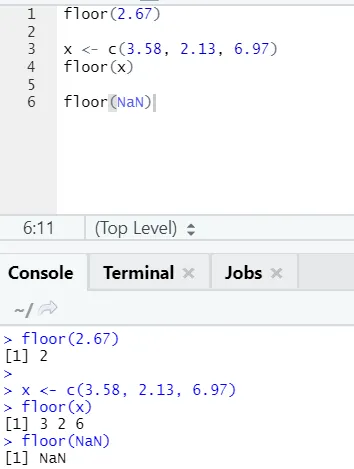
Det fungerer på samme måde for negative værdier. Venligst se her:
3) Statistiske funktioner -
Dette er de funktioner, der beskriver den relaterede sandsynlighedsfordeling.
a) Median: Dette beregnes medianen fra rækkefølgen af tal.
Syntaks
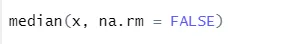
R-kode og output:
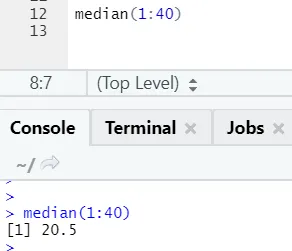
b) Dnorm: Dette refererer til den normale fordeling. Funktionen dnorm returnerer værdien af sandsynlighedsdensitetsfunktionen for den normale fordeling givne parametre for x, μ og σ.
R-kode og output:
c) Cov: Covariance fortæller, om to vektorer er positivt, negativt eller totalt ikke-relateret.
R-kode
x_new = c(1., 5.5, 7.8, 4.2, -2.7, -5.5, 8.9)
y_new = c(0.1, 2.0, 0.8, -4.2, 2.7, -9.4, -1.9)
cov(x_new, y_new)
R output:
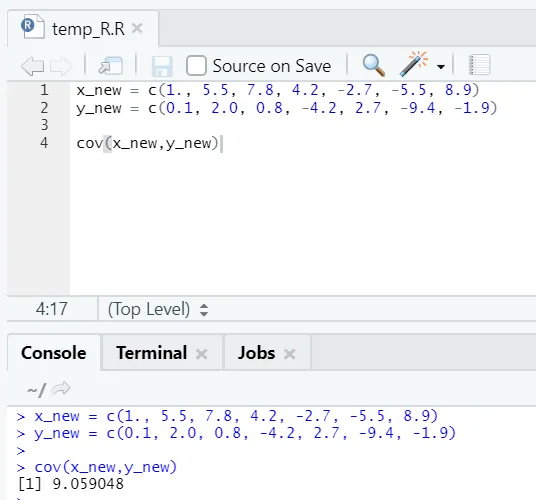
Som du kan se, er to vektorer positivt relaterede, hvilket betyder, at begge vektorer bevæger sig i samme retning. Hvis samvariationen er negativ, betyder det at x og y er omvendt relaterede og bevæger sig derfor i den modsatte retning.
d) Cor: Dette er en funktion til at finde sammenhængen mellem vektorer. Det giver faktisk associeringsfaktoren mellem de to vektorer, der er kendt som "korrelationskoefficient". Korrelation tilføjer en gradfaktor i forhold til samvariation. Hvis to vektorer er positivt korrelerede, fortæller korrelationen dig også, hvor meget forlængelse de er positivt relateret.
Disse tre typer metoder, der kan bruges til at finde en sammenhæng mellem to vektorer:
- Pearson korrelation
- Kendall korrelation
- Spearman-korrelation
I simpelt R-format ser det ud som:
cor(x, y, method = c("pearson", "kendall", "spearman"))
Her er x og y vektorer.
Lad os se det praktiske eksempel på sammenhæng mellem et indbygget datasæt.
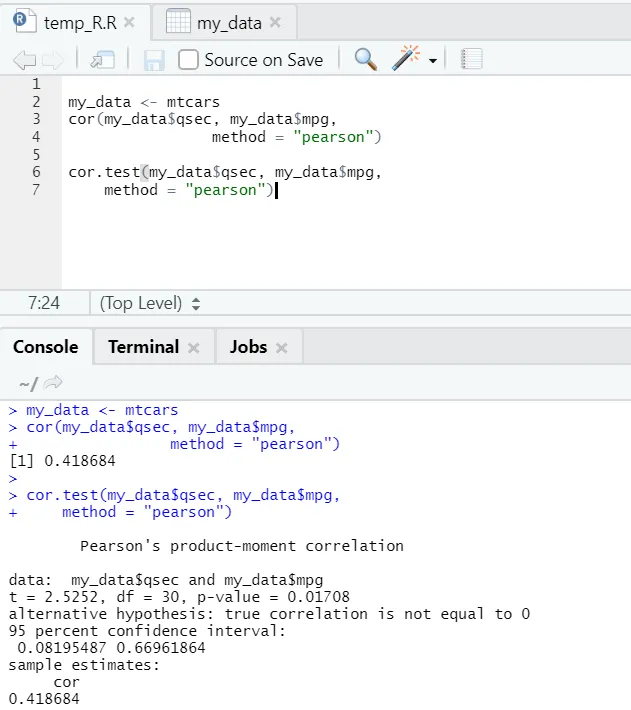
Så her kan du se “cor ()” -funktionen gav korrelationskoefficienten 0, 41 mellem “qsec” og “mpg”. Der er dog også vist en mere funktion, dvs. “cor.test ()”, som ikke kun fortæller korrelationskoefficienten, men også p-værdien og t-værdien relateret til den. Tolkning bliver langt lettere med cor.test-funktion.
Tilsvarende kan gøres med de to andre korrelationsmetoder:
R-kode for Pearson-metoden:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = " pearson ")
cor.test(my_data$qsec, my_data$mpg, method = " pearson")
R-kode for Kendall-metode:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = " kendall")
cor.test(my_data$qsec, my_data$mpg, method = " kendall")
R-kode til Spearman-metoden:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = "spearman")
cor.test(my_data$qsec, my_data$mpg, method = "spearman")
Korrelationskoefficienten varierer mellem -1 og 1.
Hvis korrelationskoefficienten er negativ, betyder det, når x øges, falder y.
Hvis korrelationskoefficienten er nul, betyder det, at der ikke er nogen tilknytning mellem x og y.
Hvis korrelationskoefficienten er positiv, betyder det, at x stiger y, har også en tendens til at stige.
e) T-test: T-testen fortæller dig, om to datasæt kommer fra den samme (forudsat) normale fordeling eller ej.
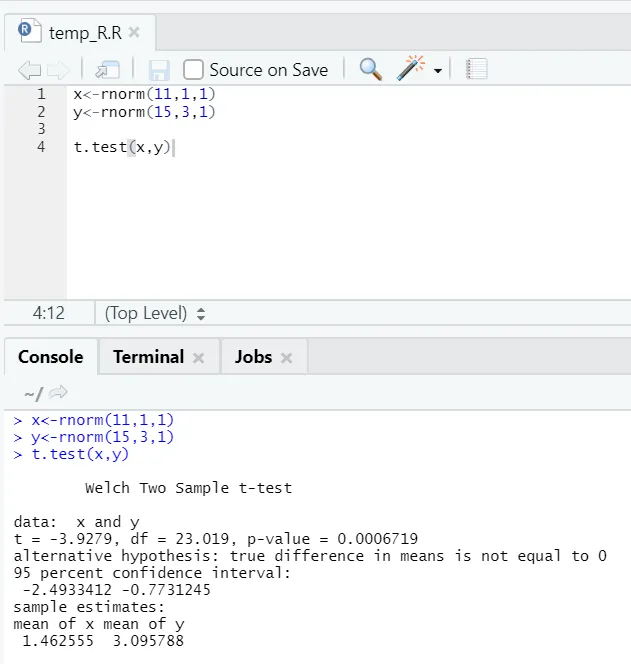
Her skal du afvise nulhypotesen om, at de to midler er ens, fordi p-værdien er mindre end 0, 05.
Denne viste forekomst er af typen: uparmerede datasæt med ulige afvigelser. Tilsvarende kan prøves med det parrede datasæt.
f) Simpel lineær regression: Dette viser forholdet mellem prediktoren / uafhængig og respons / afhængig variabel.
Et simpelt praktisk eksempel kunne være at forudsige en persons vægt, hvis højden er kendt.
R syntaks
lm(formula, data)
Her viser formlen forholdet mellem output dvs. y og inputvariabel iex Data repræsenterer datasættet, hvorpå formlen skal anvendes.
Lad os se et praktisk eksempel, hvor gulvarealet er inputvariablen og leje er outputvariablen.
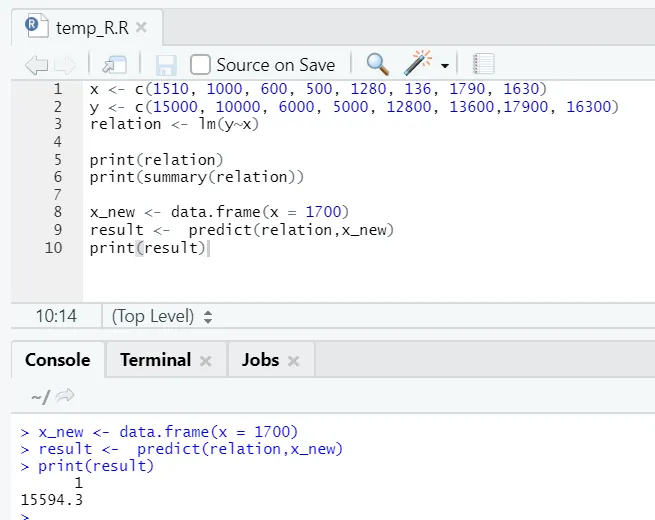
x <- c (1510, 1000, 600, 500, 1280, 136, 1790, 1630)
y <- c (15000, 10000, 6000, 5000, 12800, 13600, 17900, 16300)
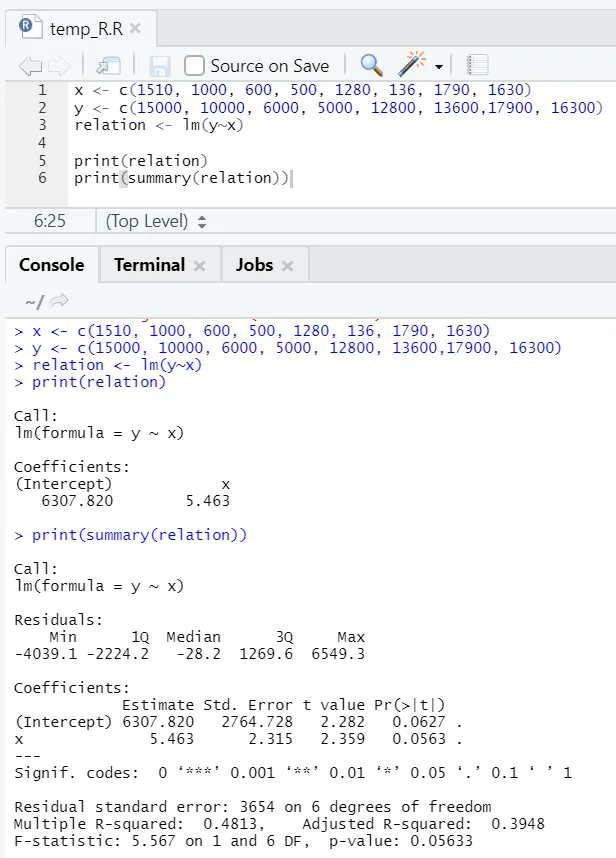
Her er P-værdien ikke mindre end 5%. Derfor kan nulhypotesen ikke afvises. Der er ikke meget betydning for at bevise forholdet mellem gulvareal og leje.
Her er R-kvadratværdien 0, 4813. Det indebærer kun 48% af variansen i outputvariablen kan forklares med inputvariablen.
Lad os sige nu, at vi er nødt til at forudsige en værdi af gulvarealet baseret på den ovennævnte monterede model.
R-kode
x_new <- data.frame(x = 1700)
result <- predict(relation, x_new)
print(result)
R output:
Efter udførelsen af ovennævnte R-kode ser udgangen således ud:
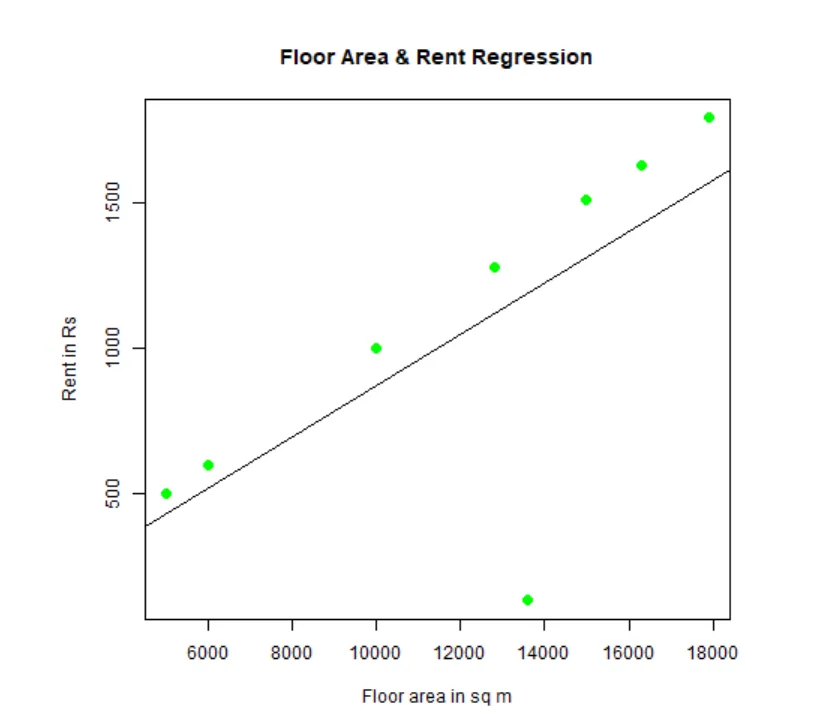
Man kan passe og visualisere regression. Her er R-koden for det:
# Giv png-diagrammappen et navn.
png(file = "LinearRegressionSample.png.webp")
# Plott skemaet.
plot(y, x, col = "green", main = "Floor Area & Rent Regression",
abline(lm(x~y)), cex = 1.3, pch = 16, xlab = "Floor area in sq m", ylab = "Rent in Rs")
# Gem filen.
dev.off()
Denne "LinearRegressionSample.png.webp" graf genereres i din nuværende arbejdsmappe.
g) Chi-Square-test
Dette er en statistisk funktion i R. Denne test har dens betydning for at bevise, om korrelationen findes mellem to kategoriske variabler.
Denne test fungerer også som enhver anden statistisk test var baseret på p-værdi, man kan acceptere eller afvise nulhypotesen.
R syntaks
chisq.test(data), /code>
Lad os se et praktisk eksempel på det.
R-kode
# Indlæs biblioteket.
library(datasets)
data(iris)
# Opret en dataramme fra hoveddatasættet.
iris.data <- data.frame(iris$Sepal.Length, iris$Sepal.Width)
# Opret en tabel med de nødvendige variabler.
iris.data = table(iris$Sepal.Length, iris$Sepal.Width)
print(iris.data)
# Udfør Chi-Square-testen.
print(chisq.test(iris.data))
R output:
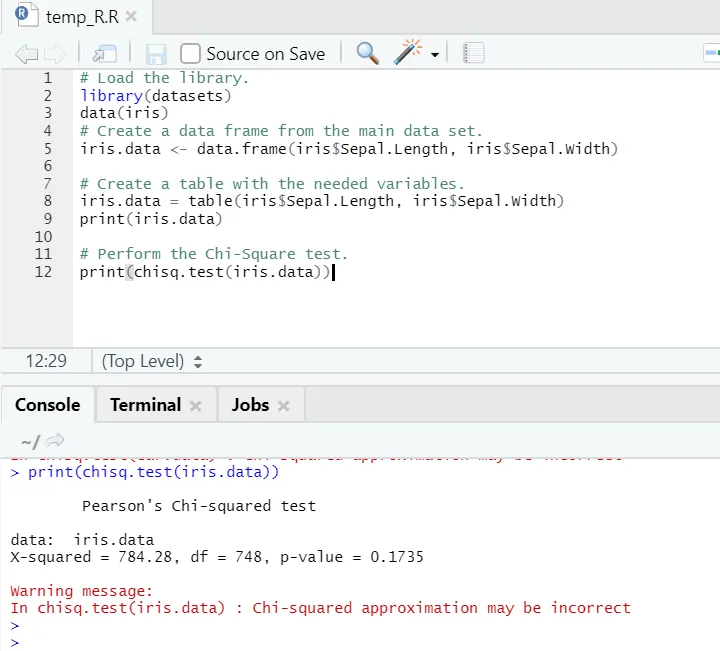
Som man kan se, er chi-square-testen blevet udført over et iris-datasæt i betragtning af dets to variabler “Sepal. Længde ”og“ Sepal.Width ”.
P-værdien er ikke mindre end 0, 05, hvorfor der ikke findes korrelation mellem disse to variabler. Eller vi kan sige, at disse to variabler ikke er afhængige af hinanden.
Konklusion
Funktioner i R er enkle, lette at montere, lette at forstå og alligevel meget kraftfulde. Vi så en række funktioner, der bruges som en del af det grundlæggende i R. Når man bliver fortrolig med disse funktioner, der er omtalt ovenfor, kan man udforske andre varianter af funktioner. Funktioner hjælper dig med at få din kode til at køre på en enkel og kortfattet måde. Funktioner kan være indbyggede eller brugerdefinerede, alt afhænger af behovet, mens der løses et problem. Funktioner giver et program god form.
Anbefalede artikler
Dette er en guide til Funktioner i R. her diskuterer vi, hvordan man skriver Funktioner i R og forskellige typer funktioner i R med syntaks og eksempler. Du kan også se på den følgende artikel for at lære mere -
- R strengfunktioner
- SQL-strengfunktioner
- T-SQL strengfunktioner
- PostgreSQL strengfunktioner