

Forskelle mellem Sqoop og Flume
Sqoop er et produkt fra Apache-software. Sqoop henter nyttig information fra Hadoop og videresendes derefter til de eksterne datalagre. Ved hjælp af Sqoop kan vi importere data fra en RDBMS eller mainframe til HDFS. Flume er også fra Apache-software. Det indsamler og flytter de rekursive data, der genereres. Apache Flume er ikke kun begrænset til loggaggregatsamling, men datakilder kan tilpasses, og Flume kan således bruges til at transportere store mængder data. Den bedste måde at indsamle, aggregere og flytte store mængder data mellem Hadoop Distribueret filsystem og RDBMS er ved hjælp af værktøjer som Sqoop eller Flume.
Lad os diskutere disse to almindeligt anvendte værktøjer til det ovennævnte formål.
Hvad er Sqoop
For at bruge Sqoop skal en bruger specificere det værktøj, brugeren ønsker at bruge, og de argumenter, der styrer det bestemte værktøj. Du kan også derefter eksportere dataene tilbage til en RDBMS vha. Sqoop. Eksportfunktionaliteten af Sqoop bruges til at udtrække nyttige oplysninger fra Hadoop og eksportere dem til de udvendige strukturerede datalagre. Det fungerer med forskellige databaser som Teradata, MySQL, Oracle, HSQLDB.
- Sqoop Arkitektur: -
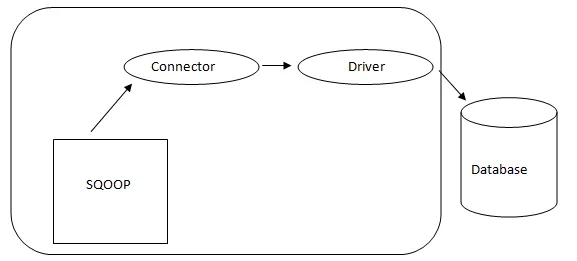
Arkitektur af Sqoop
Stikket i en Sqoop er et plugin til en bestemt databasekilde, så det er grundlæggende, at det er et stykke Sqoop-etablering. På trods af det faktum, at drivere er databasespecifikke stykker og distribueres af forskellige databaseleverandører, leveres Sqoop selv med forskellige typer stik, der bruges til udbredt database- og informationslagersystem. Således sendes Sqoop også med et blandet udvalg af stik. Sqoop giver en pluggbar komponent til et ideelt netværk og eksternt system. Sqoop API giver en nyttig struktur til samling af nye stik, og derfor kan ethvert databasestik slippes i Sqoop installation for at give forbindelse til forskellige datasystemer.
Hvad er Flume
Apache Flume er ikke kun begrænset til logdataindsamling, men datakilder kan tilpasses, og Flume kan således bruges til at transportere enorme mængder data, herunder men ikke begrænset til e-mail-beskeder, social-medie-genererede data, netværkstrafikdata og stort set enhver datakilde mulig.
Flume-arkitektur: - Flume-arkitektur er baseret på mange kernekoncepter:
- Flume-begivenhed - det er repræsenteret som den strømning af enhed, der har en byte-nyttelast og et sæt strenge med valgfri strengoverskrifter. Flume betragter en begivenhed som bare en generisk byte.
- Flume Agent- Det er en JVM-proces, der er vært for komponenterne såsom kanaler, synke og kilder. Det har potentialet til at modtage, gemme og videresende begivenhederne fra en ekstern kilde til det næste niveau.
- Flume Flow - det er det tidspunkt, begivenheden genereres.
- Flume Client - det henviser til grænsefladen, hvor klienten fungerer på begivenhedens oprindelsessted og leverer det til Flume agenten.
- Kilde - En kilde er en, der bruger begivenheder med et specifikt format og leverer dem via en bestemt mekanisme.
- Kanal - Det er en passiv butik, hvor der afholdes begivenheder, indtil vasken fjerner den til yderligere transport.
- Sink - Det fjerner begivenheden fra en kanal og lægger den på et eksternt arkiv som HDFS. Det understøtter i øjeblikket oprettelse af tekst- og sekvensfiler og understøtter komprimering i begge filtyper.
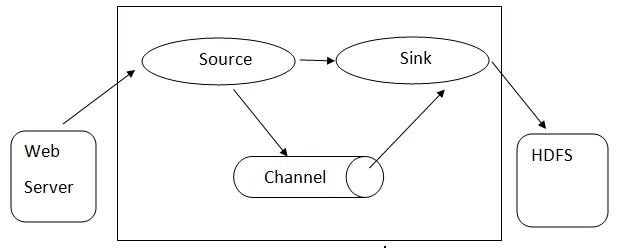
Arkitektur af Flume
Head to Head Sammenligning mellem Sqoop vs Flume (Infographics)
Nedenfor er top 7 sammenligningen mellem Sqoop vs Flume

Vigtige forskelle mellem Sqoop vs Flume
Vi ved nu, at der er mange forskelle mellem Sqoop vs Flume, her er de vigtigste forskelle mellem dem givet nedenfor -
1. Sqoop er designet til at udveksle masseinformation mellem Hadoop og Relational Database.
Der henviser til, at Flume bruges til at indsamle data fra forskellige kilder, der genererer data vedrørende en bestemt brugssag og derefter overføre denne store mængde data fra distribuerede ressourcer til et enkelt centraliseret depot.
2. Sqoop inkluderer også et sæt kommandoer, der giver dig mulighed for at inspicere den database, du arbejder med. Således kan vi betragte Sqoop som en samling af relaterede værktøjer.
Mens indsamling af datoen Flume skalerer dataene vandret, og flere Flume-agenter kan sættes i aktion for at indsamle datoen og samle dem. Derefter flyttes datalogger til et centraliseret datalager, dvs. Hadoop Distribueret filsystem (HDFS).
3. Den centrale faktor for brug af Flume er, at dataene skal genereres kontinuerligt og streaming. På lignende måde er Sqoop bedst egnet i situationer, hvor dine data lever i databasesystemer som MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (sammenligningstabel)
| Grundlag for sammenligning | SQOOP | Flume |
|
Grundlæggende natur | Sqoop fungerer godt med enhver RDBMS, der har JDBC (Java Database Connectivity) som Oracle, MySQL, Teradata osv. | Flume fungerer godt til streaming af datakilde, der kontinuerligt genereres, såsom logs, JMS, bibliotek, crashrapporter osv. |
| Dataflyt | Sqoop specifikt brugt til parallel dataoverførsel. Af denne grund kan output være i flere filer | Flume bruges til at indsamle og aggregere data på grund af deres distribuerede karakter. |
| Drevne begivenheder | Sqoop er ikke drevet af begivenheder. | Flume er fuldstændigt begivenhedsstyret. |
| Arkitektur | Sqoop følger forbindelsesbaseret arkitektur, hvilket betyder stik, ved, hvordan man opretter forbindelse til en anden datakilde. | Flume følger agentbaseret arkitektur, hvor koden der er skrevet i den er kendt som en agent, der er ansvarlig for at hente data. |
| Hvor skal man bruge | Bruges primært til hurtigere kopiering af data og derefter bruges til generering af analytiske resultater. | Generelt brugt til at trække data, når virksomheder ønsker at analysere mønstre, grundårsager eller sentimentanalyse ved hjælp af logs og sociale medier. |
| Ydeevne | Det reducerer overdreven lager- og behandlingsbelastning ved at overføre dem til andre systemer og har hurtig ydelse. | Flume er fejltolerant, robust og har en holdbar pålidelighedsmekanisme til failover og gendannelse. |
| Udgivelseshistorik | Den første version af Apache Sqoop blev lanceret i marts 2012. Den aktuelle stabile udgivelse er 1.4.7 | Den første stabile version 1.2.0 af Apache Flume blev lanceret i juni 2012. Den aktuelle stabile udgivelse er Apache Flume version 1.8.0. |
Konklusion - Sqoop vs Flume
Som du lærte ovenfor Sqoop og Flume, er det primært to dataindtagelsesværktøjer, der bruges, Big Data-verdenen. Hvis du har brug for at indtage tekstlige logdata i Hadoop / HDFS, er Flume det rigtige valg til at gøre det. Hvis dine data ikke genereres regelmæssigt, fungerer Flume stadig, men det vil være en overkill for den situation. Tilsvarende er Sqoop ikke den bedste pasform til begivenhedsstyret datahåndtering.
Anbefalede artikler
Dette har været en guide til forskelle mellem Sqoop vs Flume, deres betydning, sammenligning mellem hoved og hoved, nøgleforskelle, sammenligningstabel og konklusion. denne artikel består af alle nyttige forskelle mellem Sqoop og Flume. Du kan også se på de følgende artikler for at lære mere
- Hadoop vs Teradata - Nyttige forskelle at lære
- 5 Den vigtigste forskel mellem Apache Kafka vs Flume
- Big Data vs Apache Hadoop - Top 4 sammenligning, du skal lære
- 5 Den vigtigste forskel mellem Apache Kafka vs Flume
- Vigtig tekstudvinding kontra naturlig sprogbehandling - Top 5 sammenligninger