

Hvad er datamining?
Før vi forstå, Data Mining Concepts og teknikker først studerer vi data mining. Data mining er en funktion ved konvertering af data til nogle kendte oplysninger. Dette henviser til processen med at få nogle nye oplysninger ved at undersøge en stor mængde tilgængelige data. Ved hjælp af forskellige teknikker og værktøjer kan man forudsige de oplysninger, der kræves fra dataene, kun hvis den fulgte procedure er korrekt. Dette er nyttigt i forskellige brancher til at udtrække nogle nødvendige oplysninger til fremtidig analyse ved at genkende nogle mønstre i de eksisterende data i databaser, datavarehuse osv.
Typer af data i datamining
Følgende er de typer data, hvorpå dataudvinding kan udføres:
- Relationsdatabaser
- Datalager
- Avancerede DB- og informationsdatabaser
- Objektorienterede og objektrelationelle databaser
- Transaktionsdatabaser og rumlige databaser
- Heterogene databaser og arv
- Multimedia og streaming database
- Tekstdatabaser
- Tekst mining og web mining
Data Mining Process
Nedenfor er punkterne for Data mining process:
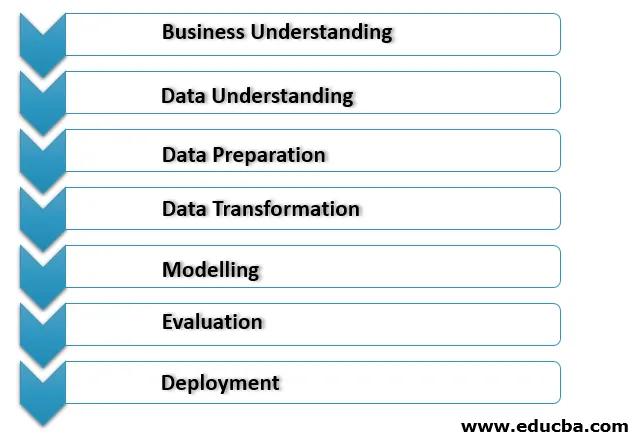
1. Forretningsforståelse
Dette er den første fase af implementeringsprocessen for data mining, hvor alle behov og klientens mål om forretning klart forstås. Korrekte dataindvindingsmål er indstillet for at se det aktuelle scenarie i virksomheden og andre faktorer såsom ressourcer, antagelser, begrænsninger. En ordentlig data mining-plan skal være detaljeret og skal opfylde vores forretnings- og data mining-mål.
2. Forståelse af data
Denne fase fungerer som en sundhedsmæssig kontrol af de data, der er indsamlet fra forskellige ressourcer til dataminingprocesser. Først er alle data fra de forskellige kilder indsamlet relateret til organisationsforretningsscenariet, som kan være i de forskellige databaser, flade filer osv. De indsamlede data kontrolleres, at de matcher korrekt, da de ikke kan relateres.
Nogle gange skal metadata også kontrolleres for at reducere fejlene i data mining processer. Forskellige data mining-forespørgsler bruges til analyse af korrekte data og baseret på resultaterne kan datakvalitet kontrolleres. Det hjælper også med at analysere, om der mangler data eller ej.
3. Forberedelse af data
Denne proces bruger den maksimale tid på projektet. Dette ansigt inkluderer en proces kaldet datarengøring for at rense de data, der er blevet indsamlet under dataforståelsesprocessen. Datarensningsprocessen bruges til at rense dataene for at udelukke forkert støjende data for dataene med manglende værdier.
4. Datatransformation
I den næste tilstand udføres datatransformationsoperationer, der bruges til at ændre dataene for at gøre dem nyttige til implementeringen af data mining. Her transformation såsom aggregering, generaliseringer, normalisering eller attributkonstruktion for at gøre dataene klar til datamodelleringsprocessen.
5. Modellering
Dette er den fase i data mining, hvor den rigtige teknik bruges til at bestemme datamønstrene. De forskellige scenarier skal oprettes for at kontrollere kvaliteten og gyldigheden af denne model og for at afgøre, om de mål, der er defineret i forretningsforståelsesprocessen, nås efter implementering af disse teknikker. Det mønster, der er fundet i denne proces, evalueres yderligere og sendes til implementering til forretningsdriftsteamet, så det kan hjælpe med at forbedre organisationernes erhvervspolitik.
6. Evaluering
I denne fase foretages den korrekte evaluering af opdagelsen af dataindvindingen for at give den et forspring eller ikke gå til implementering i forretningsprocesserne. Der foretages en ordentlig sammenligning med opdagelserne og den eksisterende forretningsdriftsplan for korrekt at evaluere ændringen for de fundne oplysninger skal føjes til den aktuelle forretningsdrift.
7. Implementering
I denne fase transformeres de oplysninger, der er afsluttet ved hjælp af data mining processer, med tog forståelig form for ikke-tekniske interessenter. Til denne proces oprettes en ordentlig implementeringsplan, der inkluderer forsendelse, vedligeholdelse og overvågning af de fundne oplysninger. På denne måde oprettes en korrekt projektrapport sammen med erfaringerne og de erfaringer, der er gjort under processen for at overdrage vores data mining-opdagelser til forretningsdriften.
Derfor hjælper denne proces med at forbedre en virksomheds politik.
Dataminingsteknikker
Nedenstående teknikker og teknologier kan hjælpe med at anvende data mining-funktionen på sin mest effektive måde:
1. Spor mønstre
Genkendelse af mønstre i dit datasæt er en af de grundlæggende teknikker i data mining. Dataene observeres med regelmæssige intervaller til genkendelse af en vis afvigelse. For eksempel kan det ses, hvis en bestemt person rejser rundt i forskellige lande, så vil denne person kræve at booke billetter regelmæssigt, og der kan derfor tilbydes et specielt kreditkort.
2. Klassificering
Det er en af de komplekse teknikker til data mining, hvor vi er nødt til at fremstille forskellige kategorier, der kan skelnes med forskellige attributter i de eksisterende data. Disse kategorier hjælper med at nå forskellige konklusioner til vores fremtidige brug. For eksempel, mens man analyserer dataene for trafik i byen, kan områdets trafik klassificeres under lav, mellem og tung. Dette vil hjælpe rejsende med at forudsige trafikken inden tiden.
3. Forening
Denne teknik svarer til mønstersporingsteknikken, men her er den relateret til de afhængigt forbundne variabler. Det betyder, at mønsteret for de relaterede data findes, som er knyttet til de eksisterende data. Begivenhedsrelateret til den anden begivenhed spores, og de særlige mønstre findes i disse data. For eksempel kan filsporingsdata for trafikken i en bestemt by også spores, de mest besøgte steder i en by. Dette kan også hjælpe med at spore berømte steder, der skal besøges i byen.
4. Opdagelse af tidligere
Denne teknik er relateret til ekstraktion af anomalier i datamønsteret. For eksempel giver salget af et indkøbscenter et godt overskud i årets 11 måneder, men i den sidste måned faldt salget så meget, at det fører til et tab. I disse tilfælde er vi nødt til at finde ud af, hvad der var den faktor, der har reduceret salget, så man kan undgå det næste gang. Teknikken til at finde en sådan distraktion i det regelmæssige mønster er en del af detekteringsmetoden Outlier.
5. Clustering
Denne teknik ligner klassificering, kun forskellen ligger i, at den vælger gruppen af data, der har nogle ligheder, sætter dem i en enkelt gruppe. For eksempel klynge forskellige målgrupper på en biograf på grundlag af hyppigheden, hvor ofte de kommer til shows, hvilken timing de kommer for oftest og hvilken filmgenre de kommer efter.
6. Regression
Denne teknik hjælper med at tegne forholdet mellem de 2 variabler, som en analyse kunne afhænge af. Her prøver vi at finde ud af mønsteret med ændring i variablen ved at fastsætte de andre afhængige variabler. For eksempel, hvis vi har brug for at finde ud af mønsteret ved salg af et produkt i et indkøbscenter afhængigt af dets tilgængelighed, sæson, efterspørgsel osv. Dette kan føre til, at ejeren kan fastsætte prisen for at sælge det.
7. Forudsigelse
Den vigtigste egenskab ved data mining er at reducere fremtidige risici og øge organisationens fortjeneste ved at studere de eksisterende og historiske mønstre for salgs- og kreditrisici. Her hjælper denne type teknologi os med at tage fremtidige beslutninger afhængigt af det mønster, der findes i historiske og nuværende data og ved at huske markedsændringer og risici. Denne teknik er mest nyttig til data mining.
Data Mining værktøjer
Man har ikke brug for de særlige nyeste teknologier til udførelse af data mining. Det kan også gøres ved hjælp af de nyeste databasesystemer og enkle værktøjer, der let er tilgængelige i enhver organisation. Man kan også oprette sit eget værktøj, når det relevante værktøj mangler. Det mest populære værktøj er vidt brugt i branchen er givet nedenfor:
1. R-sprog
Dette er et open source-værktøj, der bruges til statistisk computing og grafik. Dette værktøj hjælper med effektiv datahåndtering og opbevaringsfacilitet, og disse funktioner er på grund af nedenstående teknikker:
- Statistisk
- Klassiske statistiske prøver
- Tidsserie-analyse
- Klassifikation
- Grafiske teknikker
2. Oracle Data Mining
Dette værktøj er populært kendt som ODM, det er en del af Oracle Advanced Analytics-databasen. Dette værktøj hjælper med at analysere data i datalager og genererer detaljerede indsigter, der hjælper yderligere med at komme med forudsigelser. Disse ting hjælper med at studere kundeadfærd, produkter kræver annonce og hjælper således med trin på salgsmuligheder.
Udfordringer, der står overfor i implementeringen af Data mine:
- Der kræves kvalificerede eksperter til at stille komplekse data mining-forespørgsler.
- Nuværende modeller passer muligvis ikke i den fremtidige stats databaser. De kan måske ikke passe til fremtidige tilstande.
- Problemer med at administrere store databaser.
- Der kan være behov for at ændre forretningspraksis for at bruge oplysninger, der er blevet afsløret.
- Heterogene databaser og information, der kommer globalt, kan resultere i kompleks integreret information.
- Data mining er en forudsætning for, at data skal være forskelligartede, ellers kan resultaterne være unøjagtige.
Konklusion-Data Mining koncepter og teknikker
- Data mining er en måde at spore tidligere data og foretage fremtidig analyse ved hjælp af dem.
- Det er det samme som at udtrække de krævede oplysninger til analyse fra aktiver på sidste dato, der allerede findes i databaserne.
- Data mining kan udføres på forskellige typer databaser som f.eks. Geografisk datagrundlag, RDBMS, datavarehuse, flere databaser osv.
- Hele minedriftsprocessen inkluderer forretningsforståelse, dataforståelse, dataforberedelse, modellering, udvikling, implementering.
- Der er forskellige data mining-teknikker til rådighed for at gøre data mining arbejde på en effektiv måde såsom klassificering, regressionsassociation osv. Brug afhænger af scenariet.
- De mest effektive data mining-værktøjer er R-sprog og Oracle Data.
- Den største ulempe ved data mining er, at der er vanskeligheder ved at uddanne eksperter til at betjene analysesoftwaren.
- Der er forskellige industrier, der bruger data mining til deres analyseformål, såsom bank, fremstilling, supermarkeder, detailudbydere osv.
Anbefalede artikler
Dette er en guide til Data Mining-koncepter og teknikker. Her diskuterer vi Minedrift-processen, teknikker og værktøjer i Datamining. Du kan også gennemgå vores andre relaterede artikler for at lære mere-
- Fordele ved Data Mining
- Hvad er datamining?
- Data Mining Process
- Datavidenskabsteknikker
- Klynge i maskinlæring
- Sådan genereres testdata?
- Vejledning til modeller i datamining