

Introduktion til Python Regex
Python er buzzword i tech-industrien i dag. Det er et sprog, der vinder popularitet i hurtigt tempo. Det er et meget dynamisk sprog og kan bruges til at bygge webapplikationer til maskinlæringsalgoritmer. I denne artikel skal vi lære om, hvordan Regex bruges i Python. En regex er en kort form for Regular Expression, og det er dybest set en sekvens af tegn, der kan bruges som et mønster. Den gode ting er, at Python har sin egen indbyggede Regex-pakke kendt som re.
Syntaks:
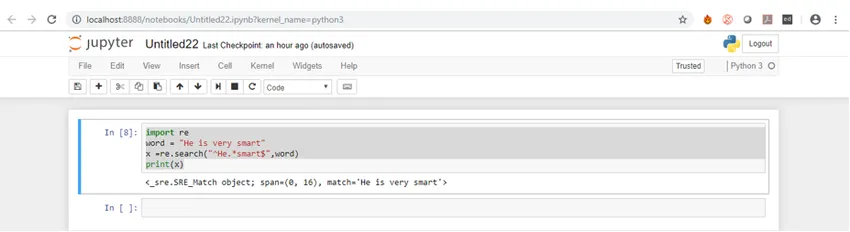
Vi vil forstå syntaks med et eksempel. Eksemplet til dette kan vi søge i en streng for at se, om det starter med “Han” og slutter med “smart”.
import reword = "He is very smart"
x =re.search("^He.*smart$", word)
print(x)
Hvis du ser på syntaks er det meget simpelt, at du først skal importere den regex-pakke, der er re, og derefter bruge nogen af funktionerne i den importerede pakke i henhold til dit krav. Hvis vi kører ovenstående prøvekode i Jupyter, får vi nedenstående resultat.
Regex-funktioner i Python
Der er mange regex-funktioner, der hjælper os med at søge i en streng efter en kamp. Før det lærer vi først de tegn, som vi generelt ser i en regex-funktion.
|
() | Det repræsenterer et sæt tegn. |
|
. | Det repræsenterer enhver karakter undtagen en ny linje. |
|
* | Det repræsenterer nul eller flere forekomster. |
|
+ | Det repræsenterer en eller flere forekomster. |
|
^ | Det repræsenterer startkarakteren |
|
$ | Det repræsenterer det afsluttende tegn. |
|
| |
Det repræsenterer enten-eller. |
|
() |
Det repræsenterer fangst og gruppe. |
| \ |
Det bruges generelt til at undslippe specialtegn |
Regex har også et par specielle sekvenser, som f.eks. Er nyttige at kende:
|
\ w | Det viser et match, hvis strengen har et sæt sæt ordtegn fra (0-9), AZ eller az og understregning. |
|
\ W | Det returnerer et match, hvis strengen ikke har nogen ordtegn til stede. |
|
\ d | Disse returnerer match, når der er cifre i strengen. |
|
\ D | Det er modsat den forrige, da det vender tilbage, hvis der ikke findes cifre i strengen. |
|
\ s | Det bruges til at tjekke for tegn på hvidt rum i en streng. Det vender tilbage, hvis der er hvide mellemrumstegn. |
|
\ S | Det vender tilbage, når der ikke er hvide mellemrum i strengen. |
Funktioner, der bruges til Regex-operationer
Lad os se forskellige funktioner i re-modulet, der kan bruges til regex-operationer i python.
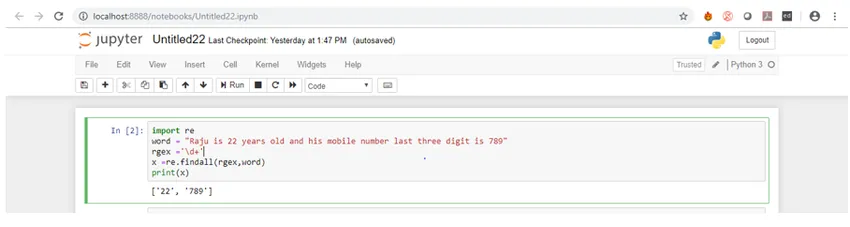
1. findall () -funktion: Denne funktion findes i re-modulet. Det returnerer en liste over alle kampe, der er til stede i strengen. Det itereres fra venstre mod højre på tværs af strengen. Kampene returneres også i nøjagtig samme rækkefølge efter søgning. Vi vil gennemgå et eksempel på dette. Antag, at vi vil finde alle de cifre, der findes i en streng. Til dette bruger vi funktionen findall (), hvor vi finder alle de cifre, der er til stede i strengen. Lad os se koden til dette nu:
Kode:
import re
word = "Raju is 22 years old and his mobile number last three-digit is 789"
rgex ='\d+'
x =re.findall(rgex, word)
print(x)
Hvis vi gennemgår koden, tildeles vi dybest set det variable ord med en streng, der indeholder cifre, og derefter passerer det passende regex-symbol for cifre sammen med det variable ord som argumenter i funktionen findall ()
Lad os nu se output.
Som du kan se, får vi en liste over numre som et resultat.
2. search () -funktion: Søgefunktionen bruges til at søge mønstre i en streng, og hvis der findes en matchning, returnerer den objektet. Her er en ting, vi skal huske, hvis der er mere end én kamp, returnerer det kun den første forekomst. Hvis der ikke findes noget match, returnerer det ingen. Vi ser et eksempel på dette, hvis vi vil finde den streng, der starter med et bestemt ord. Vi tester både positive og negative match-sager. Lad os se koden for den samme.
Kode:
import re
word = "Raju is 22 years old"
rgex ='^Raju'
x =re.search(rgex, word)
print(x)
regex1= '^Mohan'
x1 = re.search(regex1, word)
print(x1)
Her bruges variabel 'regex' i et positivt scenarie og variabel 'regex1' til et negativt scenarie. Se nu output.
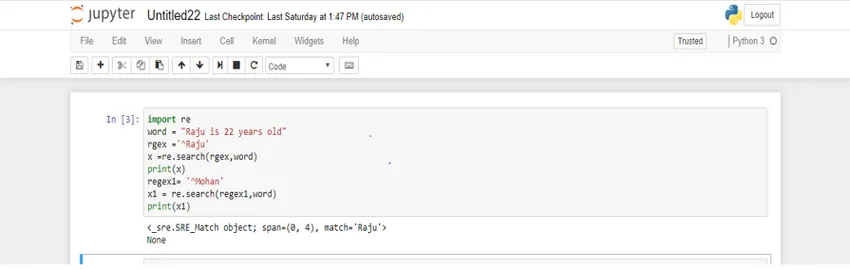
I det første tilfælde får vi matchobjektet tilbage, mens i det andet tilfælde får vi 'Ingen' tilbage.
3. Opdel () -funktion: Denne funktion opdeler strengen efter hver kamp, hvilket betyder, at så snart der er et match i strengen, opdeler denne funktion strengen derfra. Så hvis der er tre kampe, vil der være tre opdelinger. Vi vil se et eksempel. Antag, at vi ønsker at opdele en streng efter hvert mellemrum. Så vi kan bruge denne opdelte funktion til god brug i den situation.
Kode:
import re
word = "Raju is 22 years old"
rgex ='\s'
x =re.split(rgex, word)
print(x)
Her repræsenterer mønstre hvidt rumskarakter. Lad os nu se output.
Som du kan se i output deles strengen efter hver plads.
4. sub () -funktion: Denne funktion erstatter matcherne med strengen eller tegnet efter brugernes valg. Det betyder dybest set, at hvis der er et match i strengen, vil det erstatte den matchede karakter eller streng med din streng eller karakter og returnere den ændrede streng. Det kræver tre argumenter. For eksempel erstatter vi bare det hvide rum med '&' i vores streng.
Kode:
import re
word = "Raju is 22 years old"
rgex ='\s'
x =re.sub(rgex, '&', word)
print(x)
Lad os nu se på output til ovenstående kode.
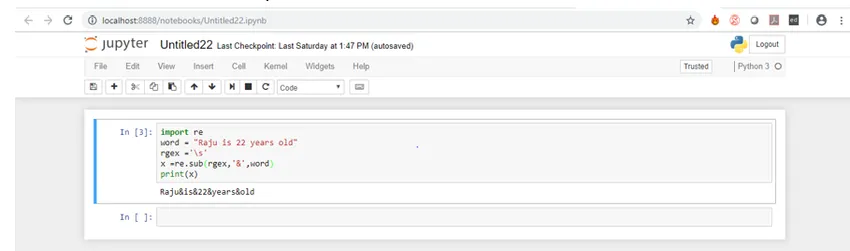
Som du kan se, blev alle mellemrum erstattet af '&'.
Konklusion
I denne artikel diskuterede vi regex-modulet og dets forskellige Python-indbyggede funktioner. Regex er meget vigtig og bruges meget i forskellige programmeringssprog.
Anbefalede artikler
Dette er en guide til Python Regex. Her diskuterer vi introduktionen til Python Regex og nogle vigtige regex-funktioner sammen med et eksempel. Du kan også gennemgå vores andre foreslåede artikler for at lære mere–
- Mens Loop i Python
- Omvendt nummer i Python
- Python-nøgleord
- Python-sæt
- PHP-nøgleord
- C ++ Nøgleord