
Hvad er en bikube?
Før vi først forstå Hive-datatyperne, vil vi studere bikuben. Hive er en datooplagringsteknik fra Hadoop. Hadoop er datalagrings- og behandlingssegmentet til Big data platform. Hive har sin position for efterfølgende databehandlingsteknikker. Ligesom i andre opfølgende miljøer kan man nå hive gennem efterfølgende forespørgsler. De største tilbud ved hive er dataanalyse, ad-hoc forespørgsler og opsummerer de lagrede data fra et latenstidsperspektiv, forespørgslerne går et større beløb.
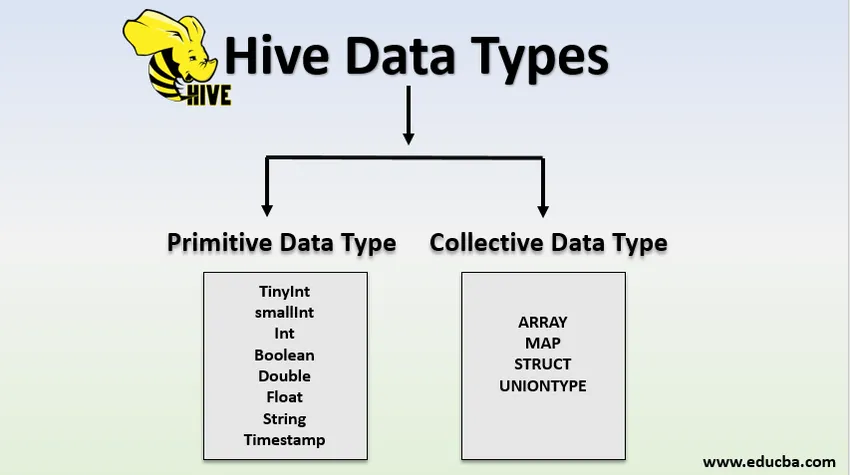
Hive datatyper
Datatyper er klassificeret i to typer:
- Primitive datatyper
- Kollektive datatyper
1. Primitive datatyper
Primitive midler var gamle og gamle. alle datatyper, der er opført som primitive, er ældre. de vigtige primitive datatyperområder anført nedenfor:
| Type | Størrelse (byte) | Eksempel |
| tinyint | 1 | 20 |
| smallint | 2 | 20 |
| Int | 4 | 20 |
| bigint | 8 | 20 |
| Boolean | Boolsk sand / falsk | FALSK |
| Dobbelt | 8 | 10, 2222 |
| Flyde | 4 | 10, 2222 |
| Snor | Sekvens af tegn | ABCD |
| Tidsstempel | Heltal / float / snor | 2/3/2012 12: 34: 56: 1234567 |
| Dato | Heltal / float / snor | 2019/02/03 |
Hive-datatyper implementeres ved hjælp af JAVA
Eks: Java Int bruges til implementering af Int-datatypen her.
- Tegnarrays understøttes ikke i HIVE.
- Hive stoler på afgrænsere for at adskille sine felter, ved at koordinere sig med Hadoop giver det mulighed for at øge skriveydelsen og læseydelsen.
- Specificering af længden på hver kolonne forventes ikke i bikubedatabasen.
- Strenglitterære kan artikuleres inden for enten dobbeltcitater (“) enkeltcitater (').
- I en nyere version af bikuben introduceres Varchar-typer, og de danner en span-specifikation af (midt i 1 og 65535). Så for en karakterstreng fungerer dette som den største værdilængde, som den kan rumme. Når der indsættes en værdi, der overstiger denne længde, bliver de højre elementer til højre for disse værdier trunkeret. Karakterlængde er opløsning med figuren af kodepunkter kontrolleret af tegnsnoren.
- Alle heltaleletter (TINYINT, SMALLINT, BIGINT) betragtes grundlæggende som INT-datatyper, og kun længden overstiger det faktiske int-niveau, det transmitteres til en BIGINT eller enhver anden respektive type.
- Decimallitterære giver definerede værdier og overlegen samling for flydende værdier sammenlignet med DOUBLE-typen. Her gemmes numeriske værdier på deres nøjagtige form, men i tilfælde af dobbelt opbevares de ikke nøjagtigt som numeriske værdier.
Dato værdi støbningsproces
| Casting udført | Resultat |
| rollebesætning (dato som dato) | Samme datoværdi |
| cast (tidsstempel som dato) | En lokal tidszone bruges til at evaluere år / måned / dato værdier her og udskrives i output. |
| cast (streng som dato) | En tilsvarende datoværdi bliver bedt om som et resultat af denne casting, men vi er nødt til at sikre, at strengen er af formatet 'YYYY-MM-DD' Nul returneres, når strengværdien ikke lykkes med en gyldig matchning. |
| cast (dato som tidsstempel) | I henhold til den aktuelle lokale tidszone oprettes en tidsstempelværdi til denne castingproces |
| cast (dato som streng) | ÅÅÅÅ-MM-DD dannes for værdien år / måned / dato, og output er i strengformat. |
2. Indsamling af datatyper
Der er fire indsamlingsdatatyper i bikuben, de kaldes også som komplekse datatyper.
- ARRAY
- KORT
- STRUCT
- UNIONTYPE
1. ARRAY: En række af elementer af en fælles type, der kan indekseres, og indeksværdien starter fra nul.
Kode:
array ('anand', 'balaa', 'praveeen');
2. MAP: Dette er elementer, der deklareres og hentes ved hjælp af nøgleværdipar.
Kode:
'firstvalue' -> 'balakumaran', 'lastvalue' -> 'pradeesh' is represented as map('firstvalue', 'balakumaran', 'last', 'PG'). Now 'balakumaran ' can be retrived with map('first').
3. STRUKT: Som i C er strukturen en datatype, der akkumulerer et sæt felter, der er mærket og kan være af enhver anden datatype.
Kode:
For a column D of type STRUCT (Y INT; Z INT) the Y field can be retrieved by the expression DY
4. UNIONTYPE: Union kan indeholde en hvilken som helst af de specificerede datatyper.
Kode:
CREATE TABLE test(col1 UNIONTYPE ) CREATE TABLE test(col1 UNIONTYPE )
Produktion:

Forskellige afgrænsere brugt i komplekse datatyper er vist nedenfor,
| afgrænsningstegn | Kode | Beskrivelse |
| \ n | \ n | Optag eller række afgrænser |
| A (Ctrl + A) | \ 001 | Feltafgrænser |
| B (Ctrl + B) | \ 002 | STRUCTS og ARRAYS |
| C (Ctrl + C) | \ 003 | Kort |
Kompleks datatyper Eksempel
Nedenfor er eksemplerne på komplekse datatyper:
1. TABELOPRETNING
Kode:
create table store_complex_type (
emp_id int,
name string,
local_address STRUCT,
country_address MAP,
job_history array)
row format delimited fields terminated by ', '
collection items terminated by ':'
map keys terminated by '_';
2. EKSEMPEL TABELDATA
Kode:
100, Shan, 4th : CHN : IND : 600101, CHENNAI_INDIA, SI : CSC
101, Jai, 1th : THA : IND : 600096, THANJAVUR_INDIA, HCL : TM
102, Karthik, 5th : AP : IND : 600089, RENIKUNDA_INDIA, CTS : HCL
3. INDLÆGNING AF DATA
Kode:
load data local inpath '/home/cloudera/Desktop/Hive_New/complex_type.txt' overwrite into table store_complex_type;
4. VISNING AF DATA
Kode:
select emp_id, name, local_address.city, local_address.zipcode, country_address('CHENNAI'), job_history(0) from store_complex_type where emp_id='100';
Konklusion - Hive-datatyper
At være en relationel DB og alligevel en Sequel forbinder HIVE tilbyder alle nøgleegenskaber for sædvanlige SQL-databaser på en meget sofistikeret måde, der gør denne til blandt de mere effektive strukturerede databehandlingsenheder i Hadoop.
Anbefalede artikler
Dette er en guide til Hive Datatype. Her diskuterer vi to typer i dataformer fra kupe med rigtige eksempler. Du kan også gennemgå vores andre relaterede artikler for at lære mere -
- Hvad er en bikube?
- Hive-alternativer
- Hive indbyggede funktioner
- Spørgsmål om Hive-interview
- PL / SQL-datatyper
- Eksempler på Python-indbyggede funktioner
- Forskellige typer af SQL-data med eksempler