

Introduktion til lineær regressionsanalyse
Det er ofte forvirrende at lære noget koncept, der endda er en del af vores daglige liv. Men det er ikke et problem, vi kan hjælpe og udvikle os selv til at lære af vores hverdagslige aktiviteter bare ved at analysere ting og ikke føler os bange for at stille spørgsmål. Hvorfor pris påvirker efterspørgslen efter varerne, hvorfor ændring i rente påvirker pengemængden. Alle disse kan besvares ved en simpel tilgang kaldet lineær regression. Den eneste kompleksitet, man føler, når man beskæftiger sig med lineær regressionsanalyse, er identificeringen af afhængige og uafhængige variabler.
Vi er nødt til at finde ud af, hvad der påvirker hvad, og halvdelen af problemet er løst. Vi må se, om det er pris eller efterspørgsel, der påvirker hinandens adfærd. Når vi først blev klar over, hvilken der er den uafhængige variabel og den afhængige variabel, er vi gode til at gå til vores analyse. Der er flere typer regressionsanalyser tilgængelige. Denne analyse afhænger af de variabler, der er tilgængelige for os.
De 3 typer regressionsanalyse
Disse tre regressionsanalyser har maksimale anvendelsestilfælde i den virkelige verden, ellers er der mere end 15 typer regressionsanalyse. Typer af regressionsanalyse, som vi skal diskutere, er:
- Lineær regressionsanalyse
- Multipel lineær regressionsanalyse
- Logistisk regression
I denne artikel vil vi fokusere på Simple Linear Regression-analyse. Denne analyse hjælper os med at identificere forholdet mellem den uafhængige faktor og den afhængige faktor. Med enklere ord hjælper Regression-modellen os med at finde ud af, hvordan ændringerne i den uafhængige faktor påvirker den afhængige faktor. Denne model hjælper os på flere måder som:
- Det er en enkel og kraftfuld statistisk model
- Det vil hjælpe os med at gøre forudsigelser og forudsigelser
- Det vil hjælpe os med at tage en bedre forretningsbeslutning
- Det vil hjælpe os med at analysere resultaterne og korrigere fejl
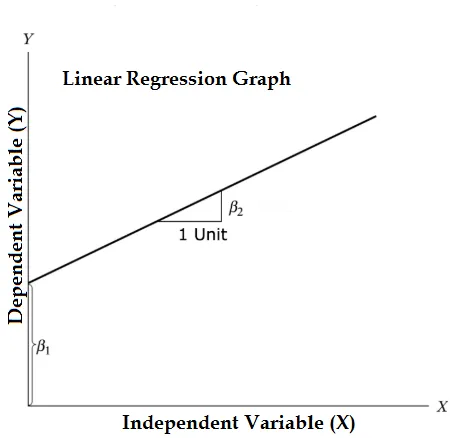
Ligningen af lineær regression og opdele den i relevante dele
Y = ß1 + ß2X + ϵ
- Hvor β1 i den matematiske terminologi kendt som aflytning og β2 i den matematiske terminologi kendt som en hældning. De er også kendt som regressionskoefficienter. ϵ er fejlbetegnelsen, det er den del af Y, som regressionsmodellen ikke er i stand til at forklare.
- Y er en afhængig variabel (andre udtryk, der om hverandre kan bruges til afhængige variabler er responsvariabel, regressand, målt variabel, observeret variabel, responderende variabel, forklaret variabel, udgangsvariabel, eksperimentel variabel og / eller outputvariabel).
- X er en uafhængig variabel (regressorer, kontrolleret variabel, manipuleret en variabel, forklaringsvariabel, eksponeringsvariabel og / eller input variabel).
Problem: For at forstå, hvad der er lineær regressionsanalyse, tager vi "Cars" datasættet, som som standard kommer i R-mapper. I dette datasæt er der 50 observationer (dybest set rækker) og 2 variabler (kolonner). Kolonnenavne er “Dist” og “Speed”. Her skal vi se påvirkningen på afstandsvariabler på grund af ændringshastighedsvariabler. For at se strukturen af dataene kan vi køre en kode Str (datasæt). Denne kode hjælper os med at forstå strukturen i datasættet. Disse funktionaliteter hjælper os med at tage bedre beslutninger, fordi vi har et bedre billede i vores tanker om datastrukturen. Denne kode hjælper os med at identificere typen af datasæt.
Kode:

Tilsvarende for at kontrollere statistikkontrolpunkterne for datasættet kan vi bruge kodeoversigt (biler). Denne kode indeholder gennemsnit, median, rækkevidde af datasættet undervejs, som forskeren kan bruge, når han håndterer problemet.
Produktion:
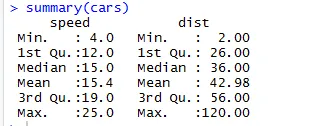
Her kan vi se den statistiske output for hver variabel, vi har i vores datasæt.
Den grafiske repræsentation af datasæt
Typer af grafisk repræsentation, der vil dække her, er, og hvorfor:
- Spredningsdiagram: Ved hjælp af grafen kan vi se, i hvilken retning vores lineære regressionsmodel går, om der er nogen stærke bevis for at bevise vores model eller ej.
- Box Plot: Hjælper os med at finde outliers.
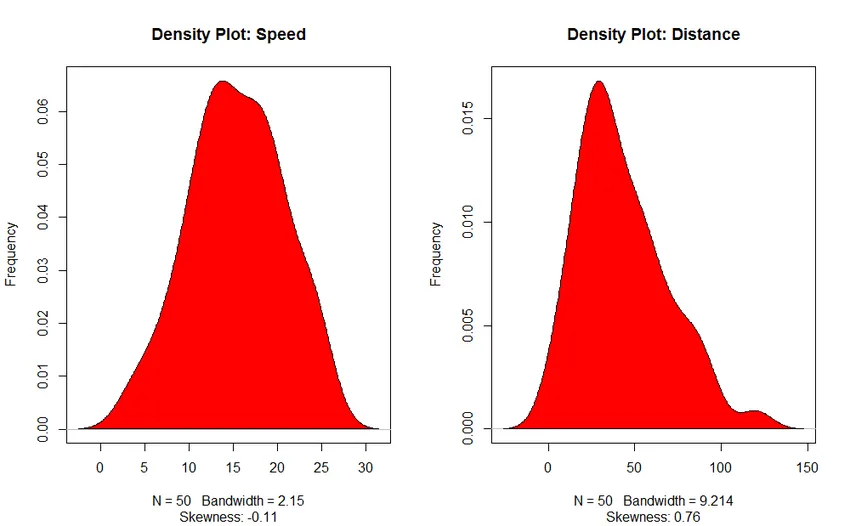
- Density plot: Hjælp os med at forstå fordelingen af den uafhængige variabel, i vores tilfælde er den uafhængige variabel “Speed”.
Fordele ved grafisk repræsentation
Her er følgende fordele som følger:
- Let at forstå
- Hjælper os med at tage hurtig beslutning
- Sammenligningsanalyse
- Mindre indsats og tid
1. Spredningsdiagram: Det hjælper med at visualisere ethvert forhold mellem den uafhængige variabel og den afhængige variabel.
Kode:

Produktion:
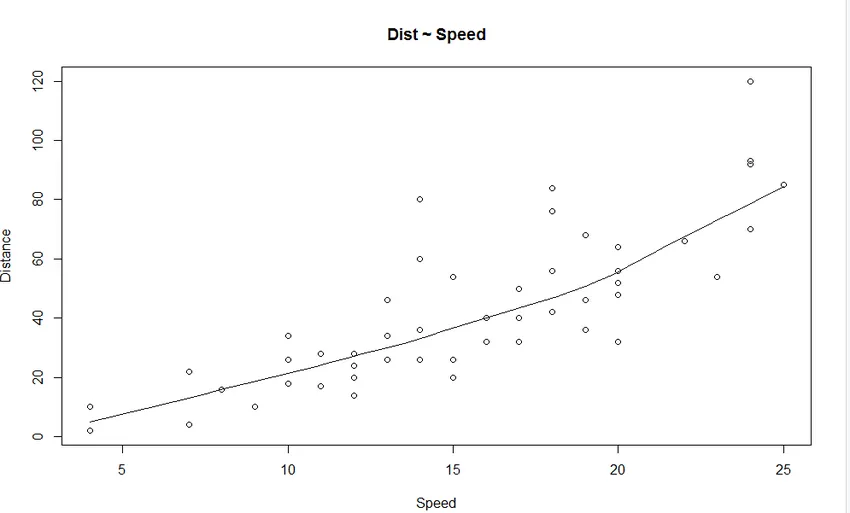
Vi kan fra grafen se et lineært stigende forhold mellem den afhængige variabel (Afstand) og den uafhængige variabel (Hastighed).
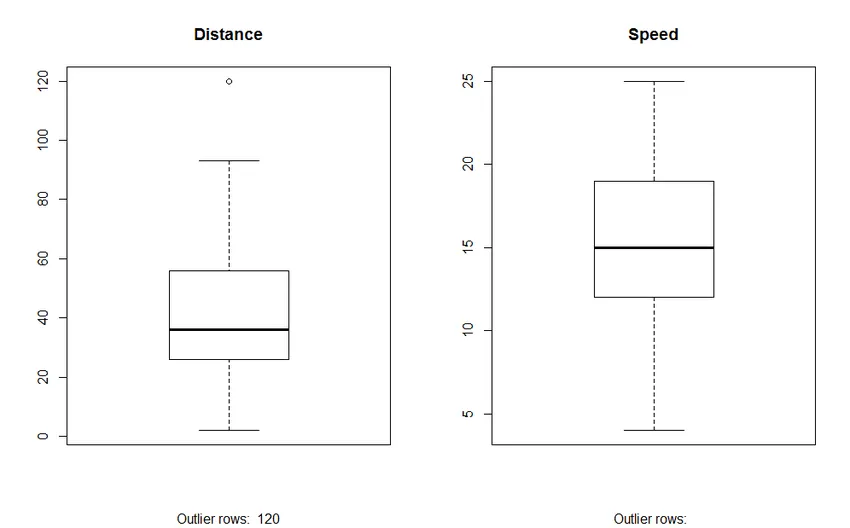
2. Box Plot: Box plot hjælper os med at identificere outliers i datasættene. Fordelene ved at bruge en kasse plot er:
- Grafisk visning af variablernes placering og spredning.
- Det hjælper os med at forstå datas skævhed og symmetri.
Kode:

Produktion:
3. Densitetsplot (for at kontrollere distributionens normalitet)
Kode:
 Produktion:
Produktion:
Korrelationsanalyse
Denne analyse hjælper os med at finde forholdet mellem variablerne. Der er hovedsageligt seks typer af korrelationsanalyser.
- Positiv korrelation (0, 01 til 0, 99)
- Negativ korrelation (-0, 99 til -0, 01)
- Ingen korrelation
- Perfekt korrelation
- Stærk korrelation (en værdi tættere på ± 0, 99)
- Svag korrelation (en værdi tættere på 0)
Scatter-plot hjælper os med at identificere, hvilke typer korrelationsdatasæt der er blandt dem, og koden til at finde korrelationen er

Produktion:
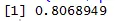
Her har vi en stærk positiv sammenhæng mellem hastighed og afstand, hvilket betyder, at de har et direkte forhold mellem dem.
Lineær regressionsmodel
Dette er kernekomponenten i analysen, tidligere prøvede vi bare at teste ting om det datasæt, vi har, er logisk nok til at køre en sådan analyse eller ikke. Funktionen, vi planlægger at bruge, er lm (). Denne funktion indeholder to elementer, der er formel og data. Før vi tildeler det, hvilken variabel er afhængig eller uafhængig, skal vi være meget sikre på det, fordi hele vores formel afhænger af det.
Formlen ser sådan ud,
Lineær regression <- lm (afhængig variabel ~ uafhængig variabel, data = dato.Frame)
Kode:

Produktion:
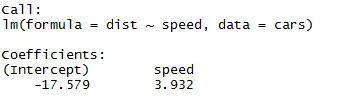
Som vi kan huske fra ovennævnte segment af artiklen, er ligningen for lineær regression:
Y = ß1 + ß2X + ϵ
Nu passer vi ind i de oplysninger, vi har fået fra ovenstående kode i denne ligning.
dist = −17.579 + 3.932 ∗ hastighed
Kun det at finde ligningen af lineær regression er ikke tilstrækkelig, men vi skal også kontrollere dens statistiske signifikante. For dette skal vi videregive en kode “Resume” på vores lineære regressionsmodel.
Kode:

Produktion:

Der er flere måder at kontrollere en statistisk signifikant for en model, her bruger vi P-værdien metoden. Vi kan betragte en model, der er statistisk tilpasset, når P-værdien er mindre end det forudbestemte statistiske signifikante niveau, hvilket ideelt er 0, 05. Vi kan i vores oversigtstabel (lineær_regression) se, at P-værdien er under 0, 05 niveau, så vi kan konkludere, at vores model er statistisk signifikant. Når vi er sikre på vores model, kan vi bruge vores datasæt til at forudsige ting.
Anbefalede artikler
Dette er en guide til Lineær regressionsanalyse. Her diskuterer vi de tre typer lineær regressionsanalyse, den grafiske repræsentation af datasæt med fordele og lineære regressionsmodeller. Du kan også gennemgå vores andre relaterede artikler for at lære mere-
- Regressionsformel
- Regressionstest
- Lineær regression i R
- Typer af dataanalyseteknikker
- Hvad er regressionsanalyse?
- Topforskelle mellem regression vs klassificering
- Top 6 forskelle i lineær regression vs logistisk regression