

Oversigt over Kafka-applikationer
Et af de trendfelter inden for it-branchen er Big Data, hvor virksomheden behandler en stor mængde kundedata og henter nyttig indsigt, der hjælper deres forretning og giver kunderne bedre service. En af udfordringerne er at håndtere og overføre disse store mængder data fra den ene ende til den anden til analyse eller behandling, det er her Kafka (et pålideligt meddelelsessystem) kommer ind i stykket, som hjælper med indsamling og transport af enorme datamængder i realtid. Kafka er designet til distribuerede systemer med høj kapacitet og er godt egnet til storskala meddelelsesbehandlingsapplikationer. Kafka understøtter mange af dagens bedste kommercielle og industrielle applikationer. Der er krav om, at Kafka-fagfolk har stærke færdigheder og praktisk viden.
I denne artikel lærer vi om Kafka, dens funktioner, brug af sager og forstå nogle bemærkelsesværdige applikationer, hvor det bruges.
Hvad er Kafka?
Apache Kafka blev udviklet hos LinkedIn og blev senere et open source Apache-projekt. Apache Kafka er et hurtigt, fejletolerant, skalerbart og distribueret meddelelsessystem, der muliggør kommunikation mellem to enheder, dvs. mellem producenter (generator af meddelelsen) og forbrugere (modtager af beskeden) ved hjælp af meddelelsesbaserede emner og giver en platform til styring af alle datafeeds i realtid.
Funktionerne, der gør Apache Kafka bedre end andre meddelelsessystemer og gælder for realtidssystemer er dens høje tilgængelighed, øjeblikkelig, automatisk gendannelse fra knudepunktfejl og understøtter levering af meddelelser med lav latens. Disse funktioner i Apache Kafka hjælper med at integrere det med store datasystemer og gør det til en ideel komponent til kommunikation. 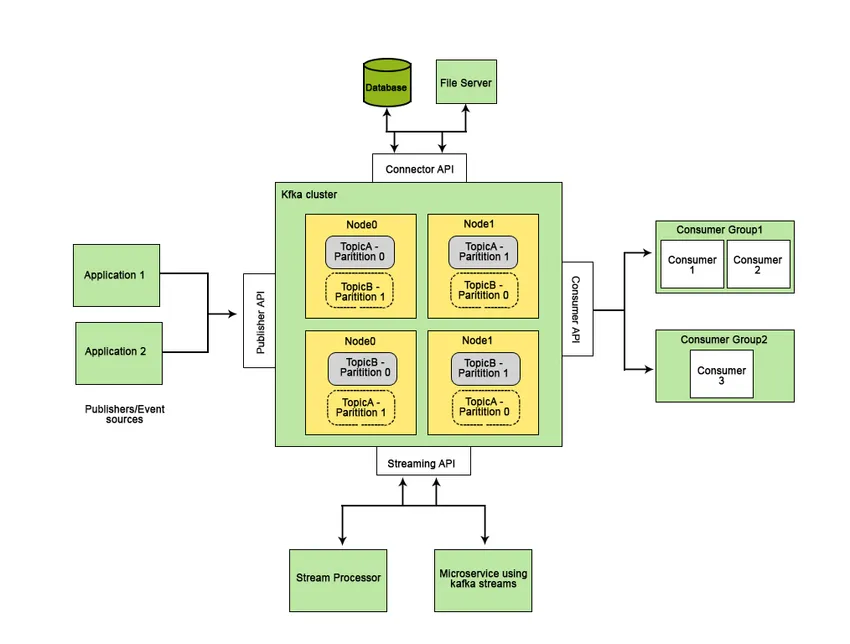
Top Kafka-applikationer
I dette afsnit af artiklen vil vi se nogle populære og vidt udbredte anvendelsessager og se nogle realistiske implementeringer af Kafka.
Virkelige applikationer
1. Twitter: Streambehandlingsaktivitet
Twitter er en platform for socialt netværk, der bruger Storm-Kafka (open source streambehandlingsværktøj) som en del af deres streambehandlingsinfrastruktur, hvor inputdata (tweets) forbruges til aggregering, transformationer og berigelse til yderligere forbrug eller opfølgning forarbejdningsaktiviteter.
2. LinkedIn: Streambehandling & metrics
LinkedIn bruger Kafka til streaming af data og til operationelle målinger. LinkedIn bruger Kafka til sine yderligere funktioner såsom Newsfeed til konsumering af meddelelser og udførelse af analyse af de modtagne data.
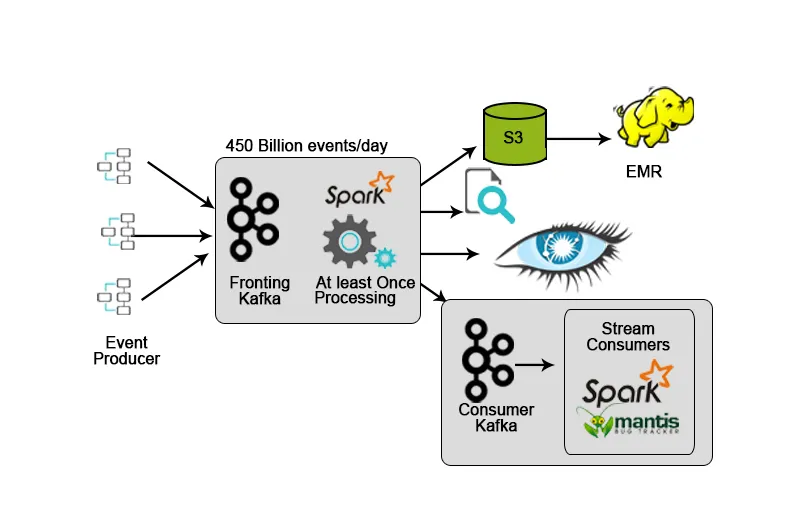
3. Netflix: Overvågning i realtid og strømbehandling
Netflix har sin egen indtagelsesramme, der dumper inputdata i AWS S3 og bruger Hadoop til at køre analyser af videostrømme, UI-aktiviteter, begivenheder til at forbedre brugeroplevelsen og Kafka til realtidsindtagelse af data via API'er.
4. Hotstar: Streambehandling
Hotstar introducerede sin egen datastyringsplatform - Bifrost, hvor Kafka bruges til datastrømning, overvågning og målsporing. På grund af sin skalerbarhed, tilgængelighed og lave latensfunktioner var Kafka et ideelt valg til at håndtere de data, som hotstar-platformen genererer på daglig basis eller ved enhver særlig lejlighed (live streaming af koncerter, eller enhver live sportskamp osv.) Hvor datamængden stiger markant.
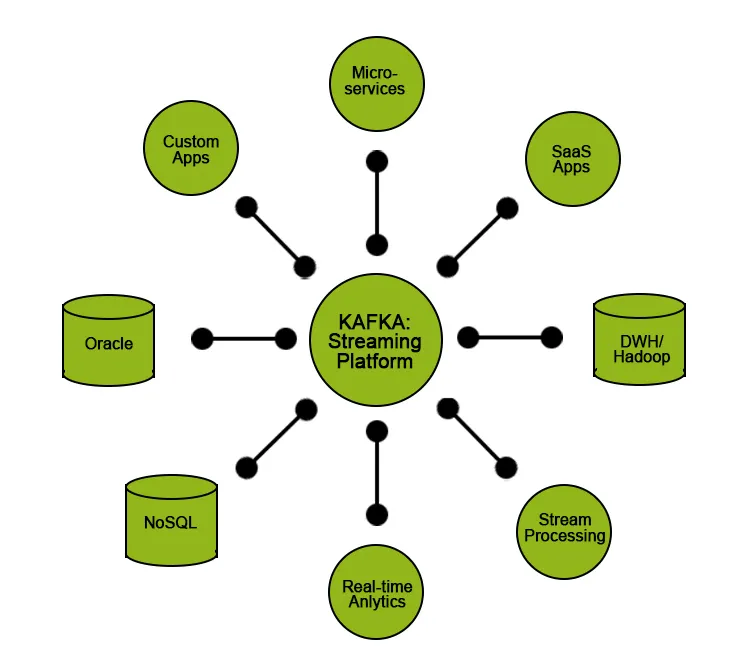
Apache Kafka bruges for det meste som en byggesten til at udvikle streaming-dataarkitektur. Denne type arkitektur bruges i applikationer såsom en samling af produkt- / serverlogfiler, analyse af clickstream og afledning af oplysninger fra maskingenererede data.
Men sammen med Kafka er vi nødt til at bruge yderligere ressourcer eller værktøjer til at konvertere den opnåede datastrøm til meningsfulde data, der hjælper med at få indsigt, der kan bruges i datastyrede beslutninger. F.eks. Er vi muligvis nødt til at generere indsigt fra de rå data, der er opnået fra IoT-enheder, eller data hentet fra sociale medieplatforme i realtid og udføre en vis analyse eller behandling og vise dem for virksomheden for at tage bedre beslutninger eller hjælpe dem med at forbedre ydelsen af deres tjenester.
For disse typer brugssager ønsker vi at streame vores inputdata / rå data til en datasø, hvor vi kan gemme vores data og sikre datakvalitet uden at hindre ydeevnen.
En anden situation, som vi måske læser data direkte fra Kafka, er, når vi har brug for ekstremt lav ende til ende latenstid, som fodring af data til realtidsapplikationer.
Kafka fastlægger visse funktioner til sine brugere:
- Publicer og abonner på data.
- Gem data i den rækkefølge, de blev genereret effektivt.
- Real-time / On-the-fly-behandling af data.
Kafka bruges mest af tiden til:
- Implementering af on-the-fly streaming-datastrørledninger, der pålideligt får data mellem to enheder i systemet.
- Implementering af on-the-fly streaming-applikationer, der transformerer eller manipulerer eller behandler datastrømme.
Brug sager
Nedenfor er nogle vidt anvendte tilfælde af Kafka-anvendelse:
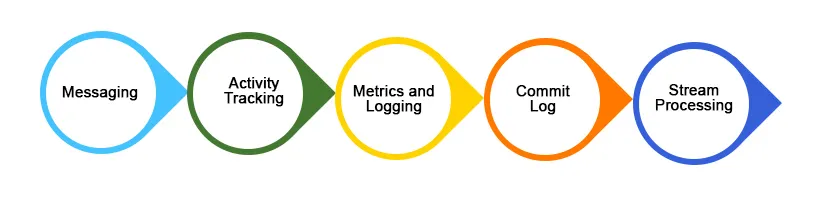
1. Meddelelser
Kafka fungerer bedre end andre traditionelle meddelelsessystemer som ActiveMQ, RabbitMQ osv. Til sammenligning tilbyder Kafka bedre kapacitet, indbygget partitionsfacilitet, replikation og fejltolerance muligheder, hvilket gør det til et bedre messaging-system til storskala behandlingsapplikationer .
2. Webstedsaktivitetssporing
Brugeraktiviteter (sidevisninger, søgninger eller udførte handlinger) kan spores og mates til overvågning eller analyse i realtid via Kafka eller bruge Kafka til at gemme disse slags data i Hadoop eller datavarehus til senere behandling eller manipulation. Aktivitetssporing genererer en enorm mængde data, der skal overføres til det ønskede sted uden nogen form for tab af data.
3. Log Aggregation
Log-aggregering er en proces til at indsamle / flette fysiske logfiler fra forskellige servere i en applikation til et enkelt arkiv (filserver eller HDFS) til behandling. Kafka tilbyder god ydelse, lavere ende til ende latenstid sammenlignet med Flume.

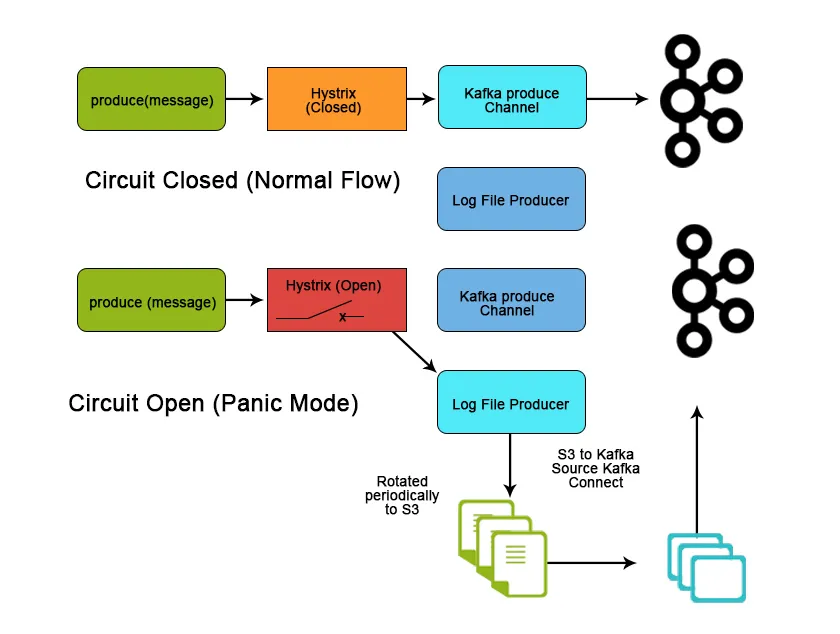
Konklusion
Kafka bruges stærkt i big data-rummet som en måde at indtage og flytte store datamængder meget hurtigt på grund af dets egenskaber og funktioner, der hjælper med at opnå skalerbarhed, pålidelighed og bæredygtighed. I denne artikel diskuterede vi Apache Kafka dens funktioner, brugssager og anvendelse, og hvad der gør det til et bedre værktøj til streaming af data.
Anbefalede artikler
Dette er en guide til Kafka-applikationer. Her diskuterer vi, hvad der er Kafka sammen med de øverste applikationer af Kafka, der inkluderer vidt implementerede brugssager og en vis implementering i virkeligheden. Du kan også se på de følgende artikler for at lære mere-
- Hvad er Kafka?
- Sådan installeres Kafka?
- Kafka Interview Spørgsmål
- Apache Kafka vs Flume
- Top 8 enheder af IoT, du burde vide
- Kafka vs Kinesis | Forskelle med infografik
- Forskellige typer Kafka-værktøjer med komponenter
- Lær de bedste forskelle på ActiveMQ vs Kafka