

Introduktion til ANOVA i R
Den følgende artikel ANOVA i R giver en oversigt til sammenligning af middelværdien af forskellige grupper. En analyse af variation (ANOVA) er en meget almindelig teknik, der bruges til at sammenligne middelværdien af forskellige grupper. ANOVA-model bruges til hypotesetestning, hvor en vis antagelse eller parameter genereres for en population, og den statistiske metode bruges til at bestemme, om hypotesen er sand eller forkert.
Hypotesen er afledt af undersøgerens antagelse og tilgængelige oplysninger om befolkningen. ANOVA kaldes en analyse af variation og bruges til hypotesetestning, hvor det kræves, at middel til en variabel i flere uafhængige grupper måles.
For eksempel vil forskere sammenligne resultatet af eksperimentel og standardbehandling i et laboratorium for at studere eller opfinde en ny medicin mod fedme. I en fedmeundersøgelse kan værdifulde resultater udledes, når befolkningens gennemsnitlige fedmehastighed kan sammenlignes i forskellige aldersgrupper. I dette tilfælde vil man gerne observere den gennemsnitlige fedmehastighed blandt forskellige aldersgrupper, såsom alder (5 til 18), (19, 35) og (36 til 50). ANOVA-metoden anvendes, da der er mere end to grupper, der er uafhængige. ANOVA-metoden bruges til at sammenligne den gennemsnitlige fedme hos de uafhængige grupper. Funktionen aov () bruges, og syntaks er aov (formel, data = dataframe) I denne artikel lærer vi om ANOVA-modellen og diskuterer yderligere envejs og tovejs ANOVA-model sammen med eksempler.
Hvorfor ANOVA?
- Denne teknik bruges til at besvare hypotesen, mens man analyserer flere datagrupper. Der er flere statistiske fremgangsmåder, men ANOVA i R anvendes, når sammenligning skal foretages på mere end to uafhængige grupper, som i vores tidligere eksempel tre forskellige aldersgrupper.
- ANOVA-teknik måler gennemsnittet af de uafhængige grupper for at give forskerne resultatet af hypotesen. For at få nøjagtige resultater skal der tages hensyn til prøvemidler, prøvestørrelse og standardafvigelse fra hver enkelt gruppe.
- Det er muligt at observere gennemsnittet individuelt for hver af de tre grupper til sammenligning. Imidlertid har denne tilgang begrænsninger og kan vise sig forkert, fordi disse tre sammenligninger ikke overvejer samlede data og derfor kan føre til type 1-fejl. R giver os funktionen til at udføre ANOVA-analysen for at undersøge variationen blandt de uafhængige datagrupper. Der er fem faser i udførelsen af ANOVA-analysen. I det første trin er data arrangeret i csv-format, og kolonnen genereres for hver variabel. En af kolonnerne ville være en afhængig variabel, og resterende er den uafhængige variabel. I anden fase læses dataene i R-studio og navngives på passende måde. I tredje fase er et datasæt knyttet til individuelle variabler og læst af hukommelsen. Endelig defineres og analyseres ANOVA i R. I nedenstående afsnit har jeg givet et par eksempler på casestudier, hvor ANOVA-teknikker skal bruges.
- Seks insekticider blev testet på 12 felter hver, og forskerne tællede antallet af fejl, der blev tilbage i hvert felt. Nu skal landmændene vide, om insekticiderne gør nogen forskel, og i bekræftende fald hvilken, de bedst bruger. Du besvarer dette spørgsmål ved hjælp af funktionen aov () til at udføre en ANOVA.
- Halvtreds patienter modtog en af fem kolesterolreducerende medikamentbehandlinger (trt). Tre af behandlingsbetingelserne involverede det samme lægemiddel indgivet som 20 mg en gang om dagen (1 gang) 10 mg to gange om dagen (2 gange) 5 mg fire gange om dagen (4 gange). De to resterende betingelser (drugD og drugE) repræsenterede konkurrerende lægemidler. Hvilken lægemiddelbehandling producerede den største kolesterolreduktion (respons)?
ANOVA envej
- Envejs-metoden er en af ANOVA-basisteknikkerne, hvori variansanalyse anvendes, og middelværdien af flere befolkningsgrupper sammenlignes.
- Envejs ANOVA fik sit navn på grund af tilgængeligheden af envejs klassificerede data. I en envejs ANOVA-enkeltafhængig variabel og en eller flere uafhængige variabler kan være tilgængelig.
- For eksempel udfører vi ANOVA-teknikken på kolesteroldatasæt. Datasættet består af to variabler trt (som er behandlinger på 5 forskellige niveauer) og responsvariabler. Uafhængig variabel - grupper af lægemiddelbehandling, afhængig variabel - middel til 2 eller flere grupper ANOVA. Fra disse resultater kan du bekræfte at tage 5 mg doser 4 gange om dagen var bedre end at tage en tyve mg dosis en gang dagligt. Drug D har bedre effekter sammenlignet med det stof E
Drug D giver bedre resultater, hvis det tages i 20 mg doser sammenlignet med lægemiddel E
Bruger kolesteroldatasæt i multcomp-pakkeninstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
ANOVA F-testen til behandling (trt) er betydelig (p <0, 0001), hvilket giver bevis for, at de fem behandlinger
# er ikke alle lige så effektive.
Resumé (aov_model)
detach (kolesterol)

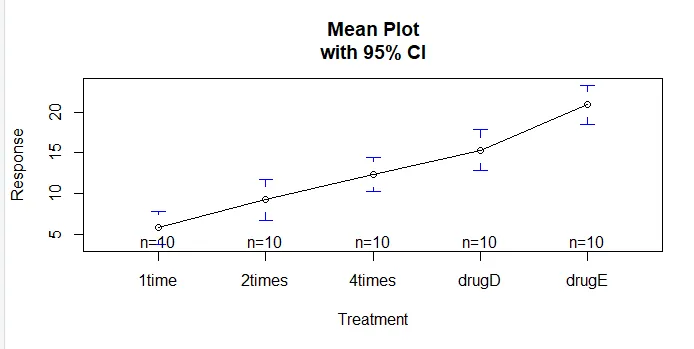
Funktionen plotmeans () i gplots-pakken kan bruges til at fremstille en graf over gruppemedier og deres tillidsintervaller Dette viser tydeligt behandlingsforskelleinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
Lad os undersøge output fra TukeyHSD () for parvise forskelle mellem gruppemetoder
TukeyHSD (aov_model)
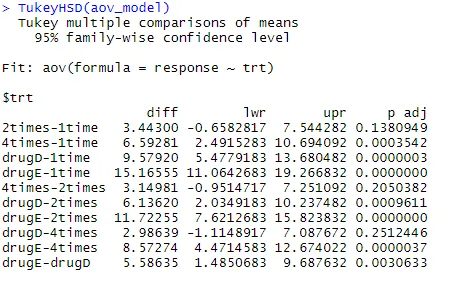
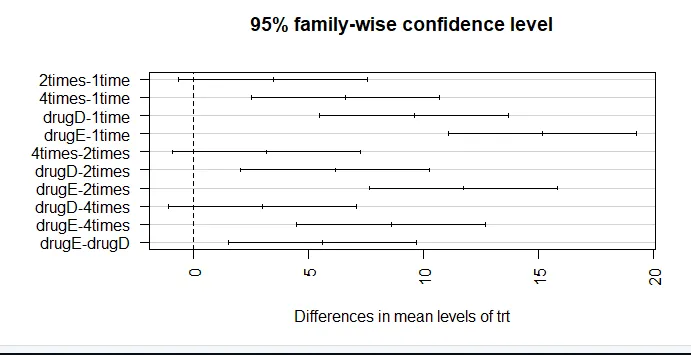
Den gennemsnitlige kolesterolreduktion i 1 gang og 2 gange er ikke signifikant forskellig fra hinanden (p = 0, 118), mens forskellen mellem 1 gang og 4 gange er signifikant forskellige (p <0, 001).
par (mar = c (5, 8, 4, 2)) # stigning i venstre margen plot (TukeyHSD (aov_model), las = 2)
Tillid til resultater afhænger af, i hvilken grad dine data tilfredsstiller antagelserne, der ligger til grund for de statistiske test. I en envejs ANOVA antages den afhængige variabel at være normalt fordelt og have samme varians i hver gruppe. Du kan bruge et QQ-plot til at vurdere biblioteket med normal antagelse (bil).
QQ plot (lm (respons ~ trt, data = kolesterol), simulere = sandt, hoved = ”QQ plot”, etiketter = FALSE)
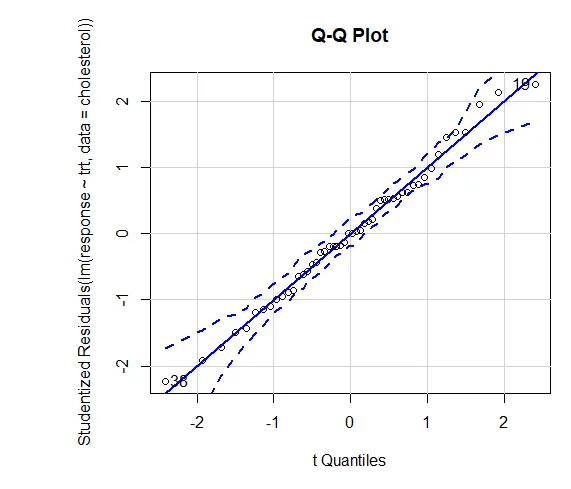
Prikket linje = 95% konfidenshylster, hvilket antyder, at normalitetsforudsætningen er opfyldt forholdsvis godt ANOVA antager, at afvigelser er ens på tværs af grupper eller prøver. Bartlett-testen kan bruges til at verificere den antagelse
bartlett.test (respons ~ trt, data = kolesterol). Bartlett's test indikerer, at afvigelserne i de fem grupper ikke adskiller sig markant (p = 0, 97).
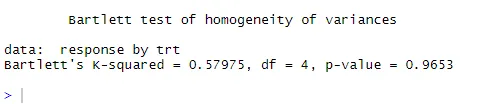
ANOVA er også følsom over for outliers-test for outliers ved hjælp af funktionen outlierTest () i bilpakken. Du har muligvis ikke brug for at køre denne pakke for at opdatere dit bilbibliotek.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
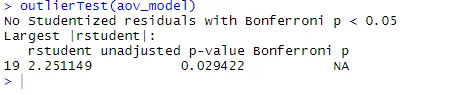
Fra output kan du se, at der ikke er nogen indikation af outliers i kolesteroldataene (NA forekommer, når p> 1). Når man tager QQ-plot, Bartlett's test og outlier-test sammen, ser data ud til at passe til ANOVA-modellen.
To-vejs Anova
En anden variabel tilføjes i tovejs ANOVA-testen. Når der er to uafhængige variabler, bliver vi nødt til at bruge tovejs ANOVA snarere end envejs ANOVA-teknik, som blev brugt i det forrige tilfælde, hvor vi havde en kontinuerlig afhængig variabel og mere end en uafhængig variabel. For at verificere tovejs ANOVA skal flere antagelser være opfyldt.
- Tilgængelighed af uafhængige observationer
- Observationer skal normalt distribueres
- Variationer skal være ens i observationer
- Outliers skal ikke være til stede
- Uafhængige fejl
For at verificere den tovejs ANOVA tilføjes en anden variabel kaldet BP til datasættet. Variablen angiver blodtrykshastigheden hos patienter. Vi vil gerne verificere, om der er nogen statistisk forskel mellem BP og dosering til patienterne.
df <- read.csv (“file.csv”)
df
anova_two_way <- aov (svar ~ trt + BP, data = df)
Resumé (anova_two_way)
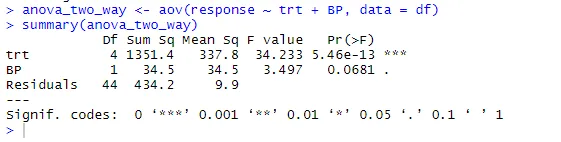
Fra output kan det konkluderes, at både trt og BP er statistisk forskellige fra 0. Derfor kan Null-hypotesen afvises.
Fordele ved ANOVA i R
ANOVA-test bestemmer forskellen i middelværdien mellem to eller flere uafhængige grupper. Denne teknik er meget nyttig til analyse af flere artikler, hvilket er vigtigt for markedsanalyse. Ved hjælp af ANOVA-testen kan man få den nødvendige indsigt fra dataene. For eksempel under en produktundersøgelse, hvor flere oplysninger, såsom indkøbslister, kunde-likes og ikke-lignende, indsamles fra brugerne. ANOVA-testen hjælper os med at sammenligne grupper af befolkningen. Gruppen kan enten være Mand mod Kvinde eller forskellige aldersgrupper. ANOVA-teknik hjælper med at skelne mellem middelværdierne for forskellige grupper af befolkningen, som faktisk er forskellige.
Konklusion - ANOVA i R
ANOVA er en af de mest almindeligt anvendte metoder til hypotesetest. I denne artikel har vi udført en ANOVA-test på datasættet bestående af halvtreds patienter, der modtog kolesterolreducerende medicinbehandling og har yderligere set, hvordan tovejs ANOVA kan udføres, når en yderligere uafhængig variabel er tilgængelig.
Anbefalede artikler
Dette er en guide til ANOVA i R. Her diskuterer vi en-vejs og to-vejs Anova-model sammen med eksempler og fordele ved ANOVA. Du kan også gennemgå vores andre foreslåede artikler -
- Regression vs ANOVA
- Hvad er SPSS?
- Sådan tolkes resultater ved hjælp af ANOVA-test
- Funktioner i R