
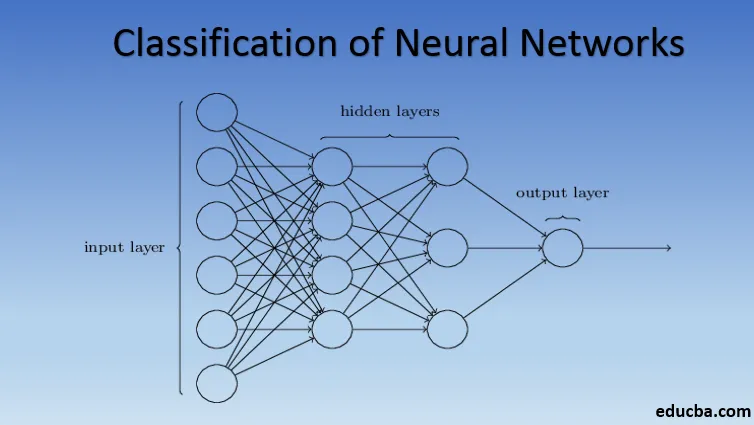
Introduktion til klassificering af neuralt netværk
Neurale netværk er den mest effektive måde (ja, du læser det rigtigt) til at løse reelle problemer i kunstig intelligens. I øjeblikket er det også et af de meget omfattende undersøgelser inden for datalogi, at en ny form for neuralt netværk ville være blevet udviklet, mens du læser denne artikel. Der er hundreder af neurale netværk til at løse problemer, der er specifikke for forskellige domæner. Her vil vi lede dig gennem forskellige typer basale neurale netværk i rækkefølge af stigende kompleksitet.
Forskellige typer af basics i klassificering af neurale netværk
1. Lavt neurale netværk (samarbejdsfiltrering)
Neurale netværk er lavet af grupper af Perceptron for at simulere den menneskelige hjernes neurale struktur. Lavt neurale netværk har et enkelt skjult lag af perceptronet. Et af de almindelige eksempler på lavt neurale netværk er Collaborative Filtering. Det skjulte lag af perceptronen ville blive trænet til at repræsentere lighederne mellem enheder for at generere henstillinger. Anbefalingssystem i Netflix, Amazon, YouTube osv. Bruger en version af Collaborative-filtrering til at anbefale deres produkter i henhold til brugerens interesse.
2. Flerlags perceptron (dybe neurale netværk)
Neurale netværk med mere end et skjult lag kaldes Deep Neural Networks. Spoiler Alert! Alle følgende neurale netværk er en form for dybt neuralt netværk tilpasset / forbedret for at tackle domænespecifikke problemer. Generelt hjælper de os med at opnå universalitet. Givet tilstrækkeligt antal skjulte lag af neuronet, kan et dybt neuralt netværk tilnærmelsesvis dvs løse ethvert komplekst virkelighedens problem.
Universal Approximation Theorem er kernen i dybe neurale netværk til at træne og passe til enhver model. Hver version af det dybe neurale netværk er udviklet af et fuldt tilsluttet lag af maksimalt poolet produkt af matrixmultiplikation, der er optimeret ved hjælp af bagpropagationsalgoritmer. Vi vil fortsætte med at lære de forbedringer, der resulterer i forskellige former for dybe neurale netværk.
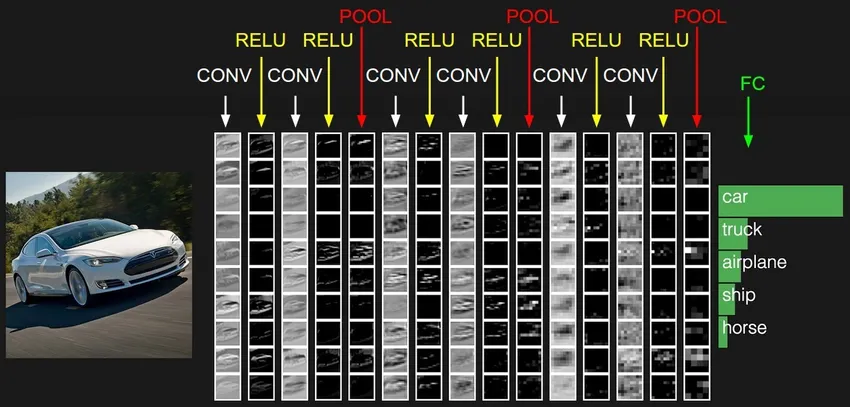
3. Konvolutional Neural Network (CNN)
CNN'er er den mest modne form for dybe neurale netværk til at producere den mest nøjagtige, dvs. bedre end menneskelige resultater i computervision. CNN'er er lavet af lag med vindinger oprettet ved at scanne hver pixel af billeder i et datasæt. Efterhånden som dataene bliver tilnærmet lag for lag, begynder CNN at genkende mønstrene og derved genkende objekterne på billederne. Disse objekter bruges i vid udstrækning i forskellige applikationer til identifikation, klassificering osv. Nyere praksis som overførselslæring i CNN'er har ført til betydelige forbedringer i modellenes unøjagtighed. Google Translator og Google Lens er de mest kendte eksempler på CNN'er.
Anvendelsen af CNN'er er eksponentiel, da de endda bruges til at løse problemer, der primært ikke er relateret til computersyn. En meget enkel, men intuitiv forklaring af CNN'er kan findes her.
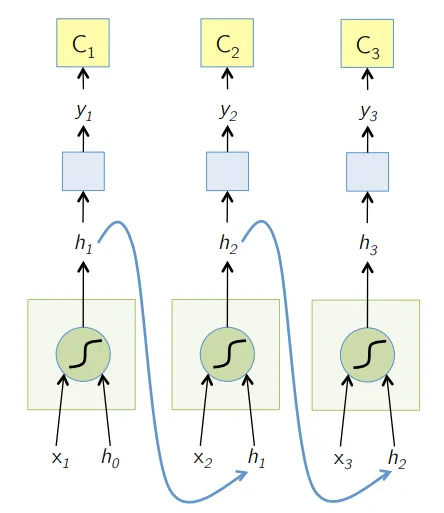
4. Gentagende neuralt netværk (RNN)
RNN'er er den seneste form for dybe neurale netværk til løsning af problemer i NLP. Kort sagt giver RNN'er output fra et par skjulte lag tilbage til inputlaget for at aggregere og videreføre tilnærmelsen til den næste iteration (epoke) af inputdatasættet. Det hjælper også modellen til selvlæring og korrigerer forudsigelser hurtigere i et omfang. Sådanne modeller er meget nyttige til at forstå semantikken i teksten i NLP-operationer. Der er forskellige varianter af RNN'er som Long Short Term Memory (LSTM), Gated Recurrent Unit (GRU) osv. I nedenstående diagram tilføres aktiveringen fra h1 og h2 henholdsvis input x2 og x3.
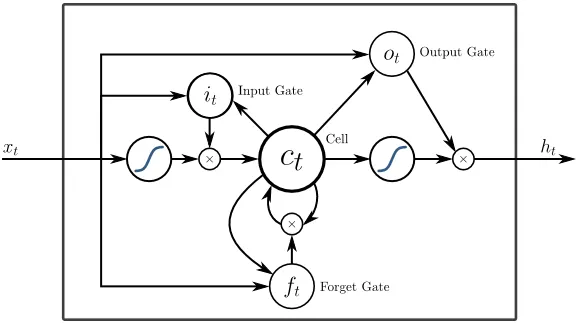
5. Lang kortvarig hukommelse (LSTM)
LSTM'er er specifikt designet til at løse problemet med forsvindingsgradenter med RNN. Forsvindende gradueringer sker med store neurale netværk, hvor gradienterne af tabsfunktionerne har en tendens til at bevæge sig tættere på nul, hvilket sætter pauserne på neurale netværk til at lære. LSTM løser dette problem ved at forhindre aktiveringsfunktioner inden for dets tilbagevendende komponenter og ved at deaktivere de lagrede værdier. Denne lille ændring gav store forbedringer i den endelige model, hvilket resulterede i, at tech-giganter tilpassede LSTM i deres løsninger. Over til den "mest enkle selvforklarende" illustration af LSTM,
6. Opmærksbaserede netværk
Opmærkelsesmodeller overtager langsomt selv de nye RNN'er i praksis. Opmærksomhedsmodellerne er bygget ved at fokusere på en del af en undergruppe af de informationer, de får, og derved eliminere den overvældende mængde baggrundsinformation, som ikke er nødvendig til den aktuelle opgave. Opmærksomhedsmodeller er bygget med en kombination af blød og hård opmærksomhed og montering ved tilbagespredning af blød opmærksomhed. Flere opmærksomhedsmodeller stablet hierarkisk kaldes Transformer. Disse transformatorer er mere effektive til at køre stablerne parallelt, så de producerer avancerede resultater med relativt mindre data og tid til træning af modellen. En opmærksomhedsfordeling bliver meget kraftig, når den bruges med CNN / RNN og kan producere tekstbeskrivelse til et billede som følger.

Tekniske giganter som Google, Facebook osv. Tilpasser hurtigt opmærksomhedsmodeller til opbygning af deres løsninger.
7. Generative Adversarial Network (GAN)
Selvom modeller for dyb læring giver de nyeste resultater, kan de narres af langt mere intelligente menneskelige kolleger ved at tilføje støj til data fra den virkelige verden. GAN'er er den seneste udvikling inden for dyb læring til at tackle sådanne scenarier. GAN'er bruger uovervåget læring, hvor dybe neurale netværk trænes med de data, der genereres af en AI-model sammen med det faktiske datasæt for at forbedre nøjagtigheden og effektiviteten af modellen. Disse modstridende data bruges for det meste til at narre den diskriminerende model for at opbygge en optimal model. Den resulterende model har en tendens til at være en bedre tilnærmelse end der kan overvindes sådan støj. Forskningsinteressen i GAN'er har ført til mere sofistikerede implementeringer som Conditional GAN (CGAN), Laplacian Pyramid GAN (LAPGAN), Super Resolution GAN (SRGAN) osv.
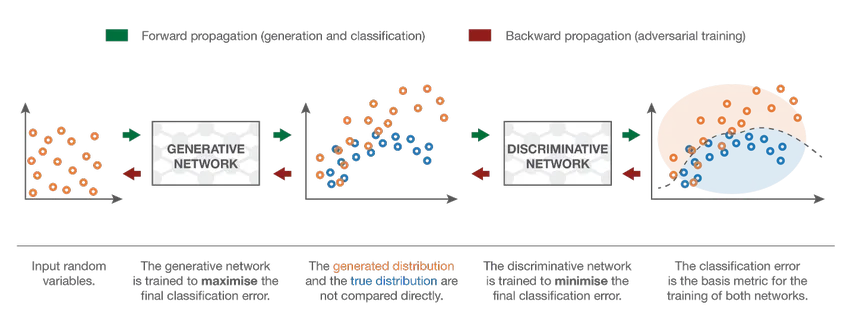
Konklusion - Klassificering af neuralt netværk
De dybe neurale netværk har skubbet grænserne for computere. De er ikke kun begrænset til klassificering (CNN, RNN) eller forudsigelser (Collaborative Filtering), men endda generering af data (GAN). Disse data kan variere fra den smukke kunstform til kontroversielle dybe forfalskninger, men alligevel overgår de mennesker af en opgave hver dag. Derfor bør vi også overveje AI-etik og -påvirkninger, mens vi arbejder hårdt for at opbygge en effektiv neuralt netværksmodel. Tid til en pæn infografik om de neurale netværk.
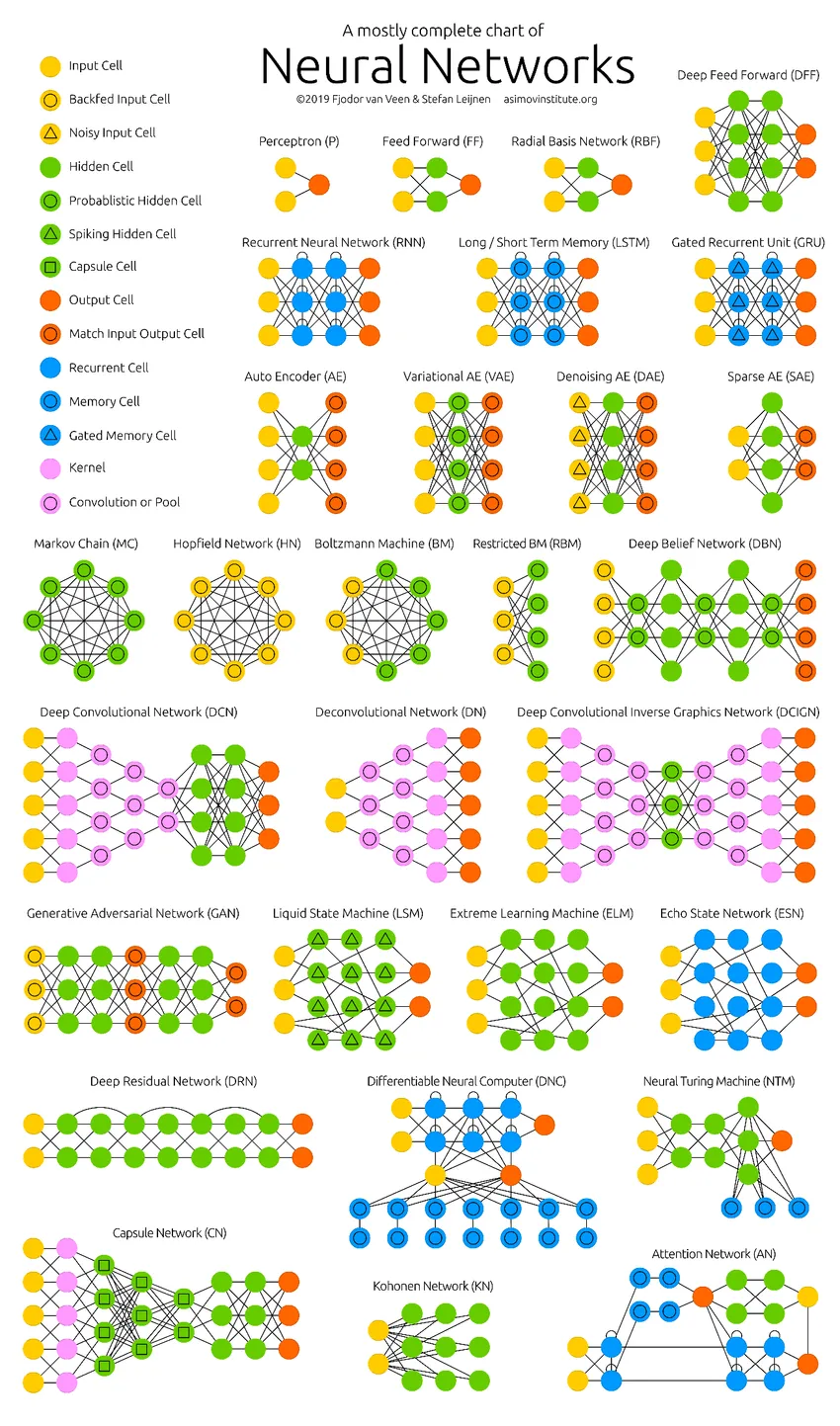
Anbefalede artikler
Dette er en guide til klassificering af neuralt netværk. Her diskuterede vi de forskellige typer basale neurale netværk. Du kan også gennemgå vores givne artikler for at lære mere-
- Hvad er neurale netværk?
- Neurale netværksalgoritmer
- Netværksscanningsværktøjer
- Tilbagevendende neurale netværk (RNN)
- Top 6 sammenligninger mellem CNN vs RNN