
Oversigt over AWS RedShift
AWS leverer mange funktionaliteter, der gør tingene lettere for os. I dette emne skal vi lære mere om, hvad der er AWS Redshift, og nogle af teknologierne i AWS Redshift, der er givet nedenfor: -
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
En af de vigtigste tjenester, der leveres af AWS, og vi vil tackle, er Amazon RedShift. Så hvad er denne RedShift, hvad bruges den til, dette er de grundlæggende spørgsmål, der kommer over vores sind, hver gang vi læser dette. så lad os kontrollere detaljeret, hvad rødskift er, og hvad det bruges til. RedShift er en virksomhedsniveau, petabyte-skala og fuldt styret datalagringstjeneste.
Så hvad er et datavarehus? Svaret for bopæl i sig selv, hvis vi ved, hvad et lager er generelle vilkår, generelt er et lager et sted, hvor råvarer eller fremstillede varer kan opbevares inden deres distribution til salg, det samme gælder for Data, også datavarehus er et sted til indsamling, lagring og styring af data fra forskellige kilder og tilvejebringelse af relevant og meningsfuld forretningsindsigt. Så Amazon leverer et lagerværktøj på virksomhedsniveau, hvor vi kan behandle og administrere data med REDSHIFT. Område for disse datasæt varierer fra 100s gigabyte til en petabyte.
Årsager til brug af AWS RedShift
Så vi støder ofte på et generelt spørgsmål, hvor før dette AWS-værktøj, hvor var dette lager, hvor gjorde vi alle disse databehandling, opbevaring og fremstilling. Så tidligere, da datalasten var ganske normal, brugte vi fysiske servere, databaser, der blev brugt med at holde styr på data og derbehandling, men da der var en eksponentiel stigning i størrelsen på dataforespørgsel og håndtering af data blev en hård opgave, da forespørgsler begyndte at tage lang tid som forventet.
Så her kom vi over behovet for amazon rødskift, der var meget hurtigere med meget høj ydelse og skalerbarhed til lagring og fremstilling af data. Det fulgte med massiv opbevaringskapacitet og gennemsigtig prisfastsættelse og sikres mod forskellige dataovertrædelser. Understøtter SQL-grænseflader og forskellige driver-ODBC / JDBC er det ganske nemt at bruge og godt fusioneret med andre Amazon-tjenester.
Arbejde med AWS RedShift
Lad os nu se arkitekturdiagrammet for Redshift og vil prøve at forstå, hvordan RedShift faktisk fungerer -
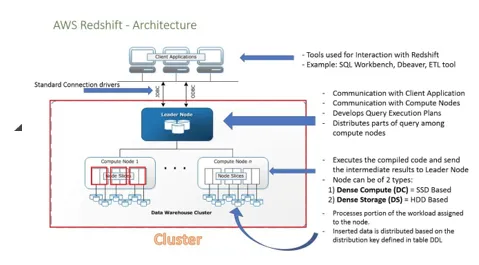
- Følgende diagram viser arbejdet med Amazon RedShift. Lad os kontrollere det over detaljerne:
- For forbindelse til klientapplikationen har vi flere drivere, der opretter forbindelse til Redshift.
- Inden for Redshift kan vi oprette mere end en klynge, og hver klynge kan være vært for flere databaser.
- Knuderne er opdelt i skiver, hver skive har data.
- Fra de tilgængelige noder, hvis vi har mere end en node, er valgt som Leader, der vil være den vigtigste kilde for klienten at kommunikere for. Klientapplikationen taler kun med lederknuden, lederknuden er ansvarlig for at modtage forespørgsler og kommando fra klientprogrammet.
- Når lederknuden begynder at få forespørgsler udført af klienten, begynder den at analysere forespørgslen og opbygge en plan for at få den til at køre på andre computernoder. Når processen er distribueret til de relevante knudepunkter, venter den på det endelige resultat fra knudepunkterne, før den returneres til klienten.
- Vi kan tilføje antallet af noder og også kan øge hukommelsen, når en belastning med data øges.
- Computernoder har et separat netværk, som klienten ikke har adgang til, hvilket også gør det sikkert.
- Der er to typer af noder: Tæt lagringsknudepunkt og Tette computernoder, lagringskapaciteten kan variere fra 160 GB til 16 TB
Så her så vi den grundlæggende arkitektur for, hvordan REDSHIFT fungerer. Lad os nu gå til, hvordan vi bruger til Aws Redshift.
Brug af AWS RedShift -
For at arbejde med AWS Redshift er vi nødt til at udføre nogle grundlæggende trin nævnt nedenfor: -
1) Log ind på AWS og opret en konto derovre. (Hvis ikke)
2) Gå til Amazon Redshift-konsol fra følgende link: -
https://console.aws.amazon.com/redshift/
3) Nu skal vi oprette en jeg AM-rolle, vi har brug for for at navigere til nedenstående link: -
https://console.aws.amazon.com/iam/
- Gå til roller
- Vælg at oprette roller.
- Vælg Redshift i AWS-tjenesten
- Vælg Redshift - Tilpasbar og derefter Næste: Tilladelser under vælg din brugssag.
- Angiv tilladelsesgrænsen
- Skriv et navn til din rolle
- Gennemgå og opret rolle.
4) Nu skal vi oprette en klynge ved at vælge en regionmenu der i konsollen.
- Vælg det område, hvor klyngen oprettes.
- Klik på Start.
- Vi er nødt til at udfylde flere detaljer som databasens navn, adgangskode og tjekke knappen Fortsæt
- Når klyngen er synlig skal du kontrollere det på listen og gennemgå statusoplysningerne.
- Når vi har klyngen med os, er den næste ting, vi skal gøre, at indstille sikkerhedsgruppen, her skal vi indstille indgående regler, protokollens kilde og rækkevidde.
- Kontroller den krævede konfiguration, og forbind til Redshift Cluster.
5) Når vi først er færdige med alle klyngerelaterede konfigurationer, er vi nødt til at oprette forbindelse til vores Redshift nu. Vi kan oprette forbindelse til denne Redshift direkte eller via SSL. For at forbinde det direkte skal vi have JDBC / ODBC-drivere, som vi er nødt til at indstille det over konfigurationssiden for klyngen.
Når disse flere konfigurationer er udført pænt, er vi klar til at bruge Redshift.
Fordele ved AWS RedShift -
Så hvorfor skal nogen bruge AWS Redshift der skal være en vis fordel i forhold til andre tjenester, der gør dette specielt. Så lad os nu tjekke nogle af fordelene ved at bruge Redshift.
- Høj hastighed : - Behandlingstiden for forespørgslen er relativt hurtigere end de andre databehandlingsværktøjer, og datavisualisering har et meget klart billede.
- Masse databehandling : - Bliv større, datastørrelsen rødskift har kapacitet til behandling af enorme datamængder på rigelig tid.
- Minimalt datatab : - Da data distribueres over klyngen og behandles parallelt over netværket, er der en minimal chance for datatab, og nøjagtighedshastigheden for de behandlede data er bedre.
- Omkostningseffektivt : - At være omkostningseffektivt er det billigere end andre tilgængelige alternativer, der gør det stærkt over industriens brug. Da prisfastsættelsen er mindre, kan vi rumme over store datamængder og kan behandle dem inden for budgettet.
- SQL-interface : - Forespørgselsmotoren baseret på Redshift er den samme som for Postgres SQL, der gør det lettere for SQL-udviklere at lege med det.
- Sikkerhed : - Dataene i Redshift er krypteret, der er tilgængelige flere steder i RedShift. Vi kan også definere indgående og udgående regel, der gør dataene meget sikre.
Der er meget flere fordele ved at have rødskift som et bedre valg for datavarehuset.
AWS RedShift-prisfastsættelse -
RedShift leveres med en fantastisk prisliste, der tiltrækker udviklere eller markedet mod det. Da det kommer med en on-demand prisfunktion, kan vi bruge den lidt over en times basis og antallet af noder i vores klynge. Spektrumpriser hjælper os med at køre SQL Queries direkte mod alle vores data.
Vi kan oprette store datalager ved hjælp af HDD til en meget lav pris. For flere detaljer om de nøjagtige prisoplysninger kan du henvise til dokumentet nedenfor af Amazon: -
https://aws.amazon.com/redshift/pricing/
Dokumentet ovenfor har alle detaljer om de forskellige priser for AWS REDSHIFT.
Konklusion
Fra ovennævnte artikel, som vi så for Redshift, skal vi nu have en god idé om, hvad der faktisk er rødskift og dets anvendelse. RedShift er så meget skalerbar og let at bruge vedtages mest af branchen gennem støtte fra forskellige andre teknologier fra Amazon, der gør det mere magtfuldt. Så i verden fuld af data kommer Redshift med en meget god pakke med datalagring og behandling.
Anbefalede artikler
Dette er en guide til Hvad er AWS RedShift. Her diskuterer vi arbejdet, brug og fordele ved AWS RedShift. Du kan også se på den følgende artikel for at lære mere -
- AWS Arkitektur
- Hvad er AWS?
- Hvad er Azure?
- Hvad er AWS Lambda?
- AWS Storage Services