

Hvad er MapReduce-algoritme?
MapReduce algoritme er hovedsageligt inspireret af funktionel programmeringsmodel. Det bruges til behandling og generering af big data. Disse datasæt kan køres samtidigt og distribueres i en klynge. Et MapReduce-program består hovedsageligt af kortprocedure og en reduceringsmetode til at udføre den resumeopgaver, som at tælle eller give nogle resultater. MapReduce-systemet fungerer på distribuerede servere, der kører parallelt og administrerer al kommunikation mellem forskellige systemer. Modellen er en speciel strategi for split-Apply-Combine-strategi, der hjælper i dataanalyse. Kortlægning udføres af Mapper-klassen og reducerer opgaven udføres af Reducer-klassen.
Forståelse af MapReduce Algorithm
MapReduce algoritme fungerer hovedsageligt i tre trin:
- Kortfunktion
- Shuffle-funktion
- Reducer funktion
Lad os diskutere hver funktion og dens ansvar.
1. Kortfunktion
Dette er det første trin i MapReduce-algoritmen. Det tager datasættene og distribuerer det i mindre underopgaver. Dette gøres yderligere i to trin, opdeling og kortlægning. Opdeling tager inputdatasættet og deler datasættet, mens kortlægningen tager disse undergrupper af data og udfører den krævede handling. Output fra denne funktion er et nøgleværdipar.
2. Blandefunktion
Dette er også kendt som mejetærskerfunktion og inkluderer fusion og sortering. Fusion kombinerer alle nøgleværdipar. Alle disse har de samme nøgler. Sortering tager input fra det fusionerende trin og sorterer alle nøgleværdipar ved at bruge tasterne. Dette trin vender også tilbage til nøgleværdipar. Outputet sorteres.
3. Reducer funktion
Dette er det sidste trin i denne algoritme. Det tager nøgleværdiparene fra blandingen og reducerer betjeningen.
Hvordan gør MapReduce-algoritmer det nemt at arbejde?
De relationelle databasesystemer har en centraliseret server, der hjælper med at lagre og behandle dataene. Disse var normalt centraliserede systemer. Når flere filer kommer ind i billedet, er behandlingen kedelig og skaber en flaskehals, mens der behandles flere filer. MapReduce kortlægger datasættet og konverterer datasættet, hvor alle data er opdelt i tuples, og reduktionsopgaven vil tage output fra dette trin og kombinere disse data tuples i de mindre sæt. Det fungerer i forskellige faser og skaber nøgleværdipar, der kan distribueres over forskellige systemer.
Hvad kan du gøre med MapReduce algoritmer?
MapReduce kan bruges til forskellige applikationer. Det kan bruges til distribueret mønsterbaseret søgning, distribueret sortering, weblink-grafvending, statistik over webadgangslog. Det kan også hjælpe med at skabe og arbejde på flere klynger, desktop gitter, frivillige computermiljøer. Man kan også skabe dynamiske skymiljøer, mobile miljøer og også højtydende computermiljøer. Google benyttede sig af MapReduce, der regenererer Google-indekset på World Wide Web. Ved at bruge det opdateres de gamle ad hoc-programmer, og de har kørt forskellige slags analyser. Det integrerede også live-søgeresultaterne uden at genopbygge det komplette indeks. Alle input og output gemmes i det distribuerede filsystem. De kortvarige data gemmes på en lokal disk.
Arbejde med MapReduce algoritme
For at arbejde med MapReduce Algorithm skal du kende den komplette proces for, hvordan den fungerer. De data, der indtages, gennemgår følgende trin:
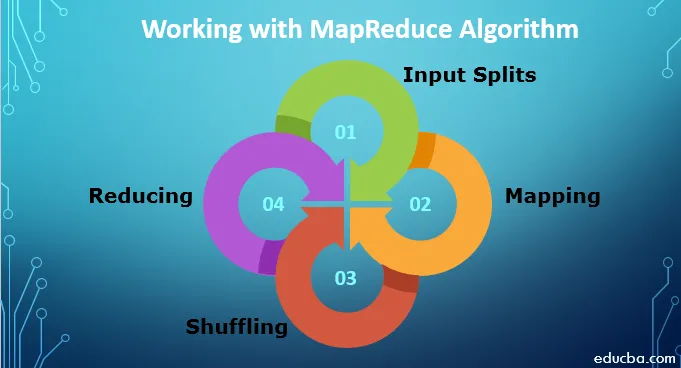
1. Inputopdelinger: Alle inputdata, der kommer til MapReduce-job, er opdelt i lige store stykker, der kaldes input splits. Det er en del af input, der kan forbruges af enhver af kortlæggerne.
2. Kortlægning: Når dataene er opdelt i bidder, går de gennem kortlægningsfasen i kortreduktionsprogrammet. Disse opdelte data overføres til kortlægningsfunktion, der producerer forskellige outputværdier.
3. Blanding: Når kortlægningen er udført, sendes dataene til denne fase. Dets job er at samle de krævede poster fra den forrige fase.
4. Reduktion: I denne fase aggregeres output fra shuffling-fasen. I denne fase blandes alle værdier sammen og samles ved aggregering, så det returnerer en enkelt outputværdi. Det opretter en oversigt over det komplette datasæt.
Fordele ved MapReduce Algorithm
De applikationer, der bruger MapReduce, har følgende fordele:
- De har fået konvergens og god generaliseringsevne.
- Data kan håndteres ved at anvende dataintensive applikationer.
- Det giver høj skalerbarhed.
- Det er let at tælle enhver forekomst af hvert ord og har en massiv dokumentsamling.
- Et generisk værktøj kan bruges til at søge værktøj i mange dataanalyser.
- Det tilbyder belastningsafbalanceringstid i store klynger.
- Det hjælper også i processen med at udtrække kontekster om brugerplacering, situationer osv.
- Det kan hurtigt få adgang til store prøver af respondenter.
Hvorfor skal vi bruge MapReduce algoritme?
MapReduce er et program, der bruges til behandling af enorme datasæt. Disse datasæt kan behandles parallelt. MapReduce kan potentielt oprette store datasæt og et stort antal noder. Disse store datasæt gemmes på HDFS, hvilket gør analysen af data lettere. Det kan behandle enhver form for data som struktureret, ustruktureret eller semistruktureret.
Hvorfor har vi brug for MapReduce-algoritmen?
MapReduce vokser hurtigt og hjælper med parallel computing. Det hjælper med at bestemme prisen for produkter og hjælper med at give den højeste fortjeneste. Det hjælper også med at forudsige og anbefale analyse. Det giver programmerere mulighed for at køre modeller over forskellige datasæt og bruger avancerede statistiske teknikker og maskinindlæringsteknikker, der hjælper med at forudsige data. Det filtrerer og sender dataene til forskellige noder i klyngen og fungerer i henhold til kortlægnings- og reduktionsfunktion.
Hvordan denne teknologi vil hjælpe dig i karrierevækst?
Hadoop er blandt de mest efterspurgte job i disse dage. Det fremskynder hastigheden og muligheden, der vokser meget hurtigt på dette felt. Der vil være endnu en boom i dette område endnu mere. IT-fagfolk, der arbejder i Java, har et pluspoint, da de er de mest efterspurgte mennesker. Desuden kan udviklere, dataarkitekter, datalager og BI-fagfolk fjerne enorme mængder af løn ved at lære denne teknologi.
Konklusion
MapReduce er det grundlæggende i Hadoop-rammen. Ved at lære dette vil du helt sikkert komme ind på markedet for dataanalyse. Du kan lære det grundigt og lære, hvordan store datasæt behandles, og hvordan denne teknologi bringer en ændring med behandling og lagring af data.
Anbefalede artikler
Dette er en guide til MapReduce Algorithms. Her diskuterer vi koncept, forståelse, arbejde, behov, fordele og karrierevækst. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- MapReduce Interview spørgsmål
- Hvad er MapReduce i Hadoop?
- Hvordan MapReduce fungerer?
- Hvad er MapReduce?
- Forskelle mellem Hadoop vs MapReduce
- Forskellige operationer relateret til tuples