

Forskellen mellem MapReduce og Spark
Map Reduce er en open-source ramme til skrivning af data til HDFS og behandling af strukturerede og ustrukturerede data, der findes i HDFS. Kortreduktion er begrænset til batchbehandling, og på andre kan Spark udføre enhver form for behandling. SPARK er en uafhængig behandlingsmotor til realtidsbehandling, der kan installeres på ethvert distribueret filsystem som Hadoop. SPARK giver en ydelse, der er 10 gange hurtigere end Map Reduce på disk og 100 gange hurtigere end Map Reduce på et netværk i hukommelsen.
Behov for SPARK
- Iterativ analyse: Kortreduktion er ikke så effektiv som en SPARK til at løse problemer, der kræver iterativ analyse, som det skal gå til disk for hver iteration.
- Interaktiv analyse: Kortreducering bruges ofte til at køre ad-hoc-forespørgsler, som det er nødvendigt for at komme til on-disk-hukommelse, som igen ikke er så effektiv som SPARK, fordi sidstnævnte henviser til i-hukommelsen, der er hurtigere.
- Ikke egnet til OLTP: Da det fungerer på den batchorienterede ramme, er den ikke egnet til et stort antal af den korte transaktion.
- Ikke egnet til graf: Apache Graph-biblioteket behandler grafen, der tilføjer Map Reduce mere kompleksitet.
- Ikke egnet til trivielle handlinger: Til operationer som et filter og sammenføjning kan det være nødvendigt at omskrive jobene, som bliver mere kompliceret på grund af nøgleværdimønsteret.
Sammenligning af hoved mod hoved mellem MapReduce vs Spark (Infographics)
Nedenfor er de 15 øverste forskelle mellem MapReduce og Spark

Vigtige forskelle mellem MapReduce vs Spark
Nedenfor er lister over punkter, der beskriver de vigtigste forskelle mellem MapReduce og Spark:
- Gnist er egnet til realtid, da den behandler ved hjælp af in-memory, mens MapReduce er begrænset til batchbehandling.
- Spark har RDD (Resilient Distribueret Datasæt), der giver os operatører på højt niveau, men i Map reducering er vi nødt til at kode hver eneste operation, hvilket gør det forholdsvis vanskeligt.
- Spark kan behandle grafer og understøtter maskinindlæringsværktøjet.
- Nedenfor er forskellen mellem MapReduce vs Spark økosystem.
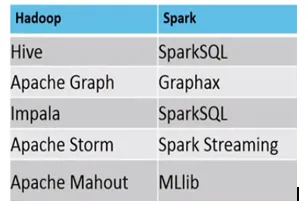
Eksempel, hvor MapReduce vs Spark er egnede, er som følger
Gnist: Registrering af kreditkortsvindel
MapReduce: Udarbejdelse af regelmæssige rapporter, der kræver beslutningstagning.
MapReduce vs gnist-sammenligningstabel
| Grundlag for sammenligning | MapReduce | Gnist |
| Framework | En open source-ramme til skrivning af data til HDFS og behandling af strukturerede og ustrukturerede data, der findes i HDFS. | En open source-ramme til hurtigere og generel databehandling |
| Hastighed | Kort-reducer behandle dataene (læser og skriv) fra disken, så sejpen er langsom sammenlignet med Spark. | Gnist er mindst 10X hurtigere på disken og 100X hurtigere i hukommelsen som Map Reduce. |
| Vanskelighed | Vi er nødt til at kode / håndtere hver proces. | Med tilgængeligheden af RDD (Resilient Distribueret datasæt) er det let at programmere. |
| Realtid | Ikke egnet til OLTP-transaktion kun til batch-tilstand | Det kan håndtere realtidsbehandling. Brug af SPARK Streaming. |
| Reaktionstid | Rammer til computerværdi på højt niveau | Rammer til computing med lavt niveau for latenstid. |
| Fejltolerance | Master-dæmoner kontrollerer slave-dæmons hjerterytme, og i tilfælde af at slavedemoner mislykkes, planlægger master-demoner alle de verserende og igangværende operationer til en anden slave. | RDD'er giver SPARK fejltolerance. De henviser til det datasæt, der findes i eksternt lagerlag (HDFS, HBase) og fungerer parallelt. |
| Scheduler | I Map Reduce bruger vi en ekstern scheduler som Oozie. | Når SPARK arbejder med in-memory computing, fungerer det som sin egen scheduler. |
| Koste | Kortreduktion er relativt billigere sammenlignet med SPARK. | Som det fungerer i hukommelsen, så det kræver en masse RAM, hvilket gør det forholdsvis dyrere. |
| Platform udviklet på | Map Reduce er udviklet ved hjælp af Java. | SPARK er udviklet ved hjælp af Scala. |
| Understøttet sprog | Kort Reducer understøtter dybest set C, C ++, Ruby, Groovy, Perl, Python. | Spark understøtter Scala, Java, Python, R, SQL. |
| SQL Support | Map Reduce kører forespørgsler ved hjælp af Hive Query Language. | Spark har sit eget forespørgselssprog kaldet Spark SQL. |
| Skalerbarhed | I Map Reduce kan vi tilføje op til n antal noder. Den største Hadoop Cluster har 14000 knudepunkter. | I Spark kan vi også tilføje et antal noder. Den største gnistklynge har 8000 knudepunkter. |
| Maskinelæring | Map Reduce understøtter Apache Mahout værktøj til maskinlæring. | Spark understøtter MLlib-værktøj til maskinlæring. |
| Caching | Kortreduktion er ikke i stand til at cache i hukommelsesdata, så de er ikke så hurtige sammenlignet med Spark. | Spark cacher data i hukommelsen til yderligere iterationer, så det er meget hurtigt sammenlignet med Map Reduce. |
| Sikkerhed | Map Reduce understøtter flere sikkerhedsprojekter og funktioner i sammenligning med Spark | Gnistsikkerhed er endnu ikke modnet som Map Reduce |
Konklusion - MapReduce vs Spark
I henhold til ovenstående forskel mellem MapReduce og Spark er det temmelig tydeligt, at SPARK er en meget mere avanceret computermotor sammenlignet med Map Reduce. Spark er kompatibel med enhver filformat og er også ret hurtigere end Map Reduce. Gnisten har desuden også grafikbehandling og maskinlæringsfunktioner.
På den ene side er Map Reduce begrænset til batchbehandling, og på den anden side er Spark i stand til at udføre enhver form for behandling (batch, interaktiv, iterativ, streaming, graf). På grund af stor kompatibilitet er Spark favorit hos Data Scientist og derfor erstatter det Map Reduce og vokser hurtigt. Men stadig er vi nødt til at gemme dataene i HDFS, og vi kan også engang brug for HBase. Så vi er nødt til at køre både Spark og Hadoop for at blive bedst.
Anbefalede artikler:
Dette har været en guide til MapReduce vs Spark, deres betydning, sammenligning mellem hoved og hoved, nøgleforskelle, sammenligningstabel og konklusion. Du kan også se på de følgende artikler for at lære mere -
- 7 vigtige ting ved Apache-gnist (guide)
- Hadoop vs Apache Spark - Interessante ting, du har brug for at vide
- Apache Hadoop vs Apache Spark | Top 10 sammenligninger, du skal vide!
- Hvordan MapReduce fungerer?
- Sammenfald af teknologi og forretningsanalyse