

Introduktion til AWS EMR
AWS EMR leverer mange funktionaliteter, der gør ting lettere for os, nogle af teknologierne er:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
- Amazon Elastic MapReduce (EMR)
En af de største tjenester, der leveres af AWS EMR, og vi vil beskæftige os med, er Amazon EMR.
EMR, der ofte kaldes Elastic Map Reduce, kommer med en let og tilgængelig måde at håndtere behandlingen af større bunker af data på. Forestil dig et big data-scenarie, hvor vi har en enorm mængde data, og vi udfører et sæt operationer over dem, siger et kort-reducere job kører, et af de største problemer, Bigdata-applikationen står overfor, er indstillingen af programmet, vi har ofte svært ved at finjustere vores program på en sådan måde, at al den tildelte ressource forbruges ordentligt. På grund af denne ovenfor indstillingsfaktor øges tiden, der tages for behandling gradvist. Elastisk kort Reducer tjenesten fra Amazon, er en webtjeneste, der giver en ramme, der administrerer alle disse nødvendige funktioner, der er nødvendige til Big databehandling på en omkostningseffektiv, hurtig og sikker måde. Fra oprettelse af klynger til datadistribution over forskellige tilfælde administreres alle disse ting let under Amazon EMR. Tjenesterne her er on-demand betyder, at vi kan kontrollere numrene baseret på de data, vi har, der gør, hvis det er omkostningseffektivt og skalerbart.
Årsager til brug af AWS EMR
Så hvorfor bruge AMR, hvad gør det bedre fra andre. Vi støder ofte på et meget grundlæggende problem, hvor vi ikke er i stand til at allokere alle tilgængelige ressourcer over klyngen til nogen applikation, hvor AMAZON EMR tager sig af disse problemer og baseret på datastørrelsen og efterspørgslen efter anvendelse det tildeler den nødvendige ressource. Når vi er elastiske, kan vi også ændre det i overensstemmelse hermed. EMR har enorm applikationssupport, hvad enten det er Hadoop, Spark, HBase, der gør det lettere for databehandling. Det understøtter forskellige ETL-operationer hurtigt og omkostningseffektivt. Det kan også bruges til MLIB i Spark. Vi kan udføre forskellige maskinlæringsalgoritmer deri. Det være sig Batchdata eller streaming i realtid af data EMR er i stand til at organisere og behandle begge typer data.
Arbejde med AWS EMR
Lad os nu se dette diagram over Amazon EMR-klyngen og vil prøve at forstå, hvordan det faktisk fungerer:
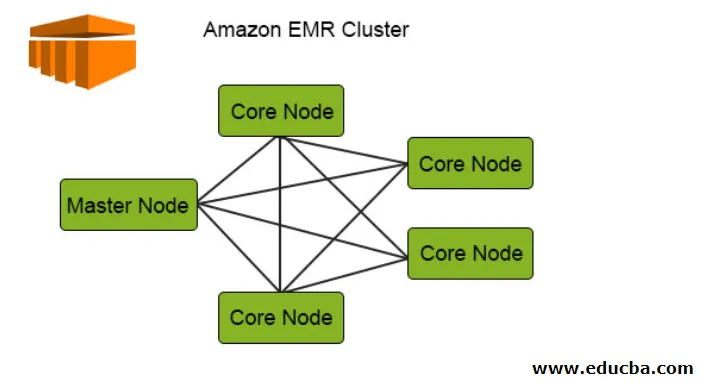
Følgende diagram viser klyngedistributionen af den indre EMR. Lad os tjekke det over detaljerne:
1. Klyngerne er den centrale komponent i Amazon EMR-arkitekturen. De er en samling af EC2-forekomster kaldet noder. Hver knude har deres specifikke roller inden i klyngen betegnet som nodetype, og baseret på deres roller kan vi klassificere dem i 3 typer:
- Master Node
- Kerneknudepunkt
- Opgaven knudepunkt
2. Masternoden, som navnet antyder, er den master, der er ansvarlig for at styre klyngen, køre komponenter og distribution af data over noder til behandling. Det holder bare spor om alt er korrekt styret og kører fint og fungerer i tilfælde af fiasko.
3. Kerneknudepunktet har ansvaret for at køre opgaven og gemme dataene i HDFS i klyngen. Alle behandlingsdele håndteres af kerneknudepunktet, og dataene efter denne behandling bringes til det ønskede HDFS-sted.
4. Opgavenoden, der er valgfri, har kun jobbet til at køre den opgave, dette gemmer ikke dataene i HDFS.
5. Hver gang vi har indsendt et job, har vi flere metoder til at vælge, hvordan værkerne skal udføres. At være det fra opsigelse af klyngen efter afslutning af jobbet til en langvarig klynge ved hjælp af EMR-konsol og CLI til at indsende trin, vi har alle de privilegier at gøre det.
6. Vi kan direkte køre jobbet på EMR ved at forbinde det med masternoden gennem de tilgængelige grænseflader og værktøjer, der kører job direkte på klyngen.
7. Vi kan også køre vores data i forskellige trin ved hjælp af EMR, alt hvad vi skal gøre er at indsende et eller flere bestilte trin i EMR-klyngen. Dataene gemmes som en fil og behandles i rækkefølge. Start af det fra "Venter tilstand til færdiggjort tilstand" kan vi spore behandlingstrinnene og finde fejlene også ved at være fra 'Mislykkedes at blive annulleret'. Alle disse trin kan let spores tilbage til dette.
8. Når alle forekomster er afsluttet, opnås den afsluttede tilstand for klyngen.
Arkitektur for AWS EMR
EMR's arkitektur introducerer sig selv fra lagringsdelen til applikationsdelen.
- Det allerførste lag leveres med lagringslaget, som inkluderer forskellige filsystemer, der bruges i vores klynge. Det være sig fra HDFS til EMRFS til lokalt filsystem, disse alle bruges til datalagring over hele applikationen. Caching af mellemresultaterne under MapReduce-behandling kan opnås ved hjælp af disse teknologier, der følger med EMR.
- Det andet lag kommer med Resource Management til klyngen, dette lag er ansvarligt for ressourcestyring for klyngerne og noder over applikationen. Dette hjælper dybest set som styringsværktøjer, der hjælper med at fordele data jævnt over klynge og korrekt styring. Standardværktøjet til ressourcestyring, som EMR bruger, er YARN, der blev introduceret i Apache Hadoop 2.0. Det administrerer centralt ressourcerne til flere databehandlingsrammer. Det tager sig af al den information, der er nødvendig for, at klyngen kan køre godt, idet den er fra nodesundhed til ressourcefordeling med hukommelsesstyring.
- Det tredje lag leveres med databehandlingsrammen, dette lag er ansvarligt for analysen og behandlingen af data. der er mange rammer understøttet af EMR, der spiller en vigtig rolle i parallel og effektiv databehandling. Nogle af de rammer, den understøtter, og vi er opmærksomme på, er APACHE HADOOP, SPARK, SPARK STREAMING osv.
- Det fjerde lag leveres med applikationen og programmer som HIVE, PIG, streaming-bibliotek, ML-algoritmer, der er nyttige til behandling af og styring af store datasæt.
Fordele ved AWS EMR
Lad os nu tjekke nogle af fordelene ved at bruge EMR:
- Høj hastighed: Da alle ressourcer udnyttes korrekt, er behandlingstiden for forespørgslen relativt hurtigere end de andre databehandlingsværktøjer har et meget klart billede.
- Bulkdatabehandling: Bliv større datastørrelsen EMR har kapacitet til behandling af enorme datamængder på rigelig tid.
- Minimalt datatab: Da data distribueres over klyngen og behandles parallelt over netværket, er der en minimal chance for datatab og godt, nøjagtighedsgraden for de behandlede data er bedre.
- Omkostningseffektivt: At være omkostningseffektivt er det billigere end noget andet tilgængeligt alternativ, der gør det stærkt over industriens brug. Da prisfastsættelsen er mindre, kan vi rumme over store datamængder og kan behandle dem inden for budgettet.
- AWS Integreret: Det er integreret med alle AWS-tjenester, der gør det let tilgængeligt under et tag, så alt hvad sikkerhed, opbevaring og netværk er integreret på ét sted.
- Sikkerhed: Det leveres med en forbløffende sikkerhedsgruppe til at kontrollere indgående og udgående trafik, og brugen af IAM-roller gør det mere sikkert, da det kommer med forskellige tilladelser, der gør dataene sikre.
- Overvågning og implementering: vi har passende overvågningsværktøjer til al den applikation, der kører over EMR-klynger, der gør det gennemsigtigt og nemt at analysere, og det kommer også med en automatisk implementeringsfunktion, hvor applikationen konfigureres og distribueres automatisk.
Der er meget flere fordele ved at have EMR som en bedre valg af anden klyngeberegningsmetode.
AWS EMR-prissætning
EMR kommer med en fantastisk prisliste, der tiltrækker udviklere eller markedet mod det. Da det kommer med en on-demand prisfunktion, kan vi bruge den lidt over en times basis og antallet af noder i vores klynge. Vi kan betale for en sats pr. Sekund for hvert sekund, vi bruger, med et minut som minimum. Vi kan også vælge vores tilfælde, der skal bruges som reserverede tilfælde eller spotinstanser, hvor stedet er meget omkostningsbesparende.
Vi kan beregne den samlede regning via en simpel månedlig lommeregner fra nedenstående link: -
https://calculator.s3.amazonaws.com/index.html#s=EMR
For flere detaljer om de nøjagtige prisoplysninger kan du henvise til dokumentet nedenfor af Amazon: -
https://aws.amazon.com/emr/pricing/
Konklusion
Fra ovenstående artikel så vi, hvordan EMR kan bruges til fair behandling af big data med alle ressourcer, der konventionelt anvendes.
At have EMR løser vores grundlæggende problem med databehandling og reducerer meget behandlingstiden med et godt antal, da det er omkostningseffektivt er det let og praktisk at bruge.
Anbefalet artikel
Dette har været en guide til AWS EMR. Her diskuterer vi en introduktion til AWS EMR langs dens Working and the Architecture såvel som fordelene. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- AWS Alternativer
- AWS-kommandoer
- AWS Services
- AWS Interview Spørgsmål
- AWS Storage Services
- Top 7 konkurrenter af AWS
- Liste over Amazon Web Services-funktioner