
Introduktion til Hive Arkitektur
Hive Architecture er bygget oven på Hadoop-økosystemet. Hive har ofte interaktioner med Hadoop. Apache Hive klarer sig både med SQL-databasesystemets domæne og Map-reducering. Hive-applikationer kan skrives på forskellige sprog som Java, python. Hive-arkitektur viser, hvordan man skriver hive Query-sprog, og hvordan interaktionerne mellem programmereren udføres ved hjælp af kommandolinjegrænsefladen. Hive-forespørgselssprog gør jobbet med at konvertere alle Hadoop-klyngeopgaver gennem kortreducering. Som vi alle vidste Hadoop at behandle big data i et distribueret miljø og danner en open source ramme. Med hive er det fleksibelt at administrere og udføre forespørgslen og en god tilhænger til at udføre funktioner som indkapsling, ad-hoc forespørgsler. Denne artikel giver en kort introduktion til hive-arkitektur, som findes på Hadoop-laget for at udføre opsummering i big data.
Hive Arkitektur med dets komponenter
Hive spiller en stor rolle i dataanalyse og integration af business intelligence og det understøtter filformater som tekstfil, rc-fil. Hive bruger et distribueret system til at behandle og udføre forespørgsler, og lagringen udføres til sidst på disken og behandles til sidst ved hjælp af en kortreducerende ramme. Det løser optimeringsproblemet, der findes under kortreducerende og hive udføre batchjob, som er tydeligt forklaret i arbejdsgangen. Her gemmer en metabutik skemaoplysninger. En ramme kaldet Apache Tez er designet til realtidsforespørgsler.
De vigtigste komponenter i Hive er vist nedenfor:
- Hive klienter
- Hive-tjenester
- Hive-opbevaring (Meta-opbevaring)
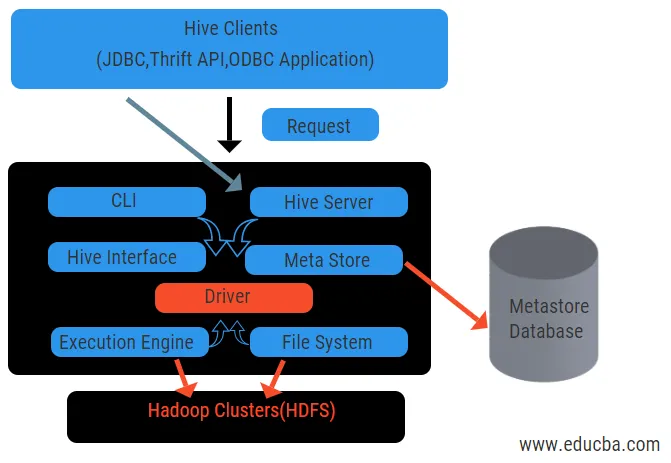
Ovenstående diagram viser strukturen i Hive og dens komponentelementer.
Hive-klienter:
De inkluderer Thrift-applikation til at udføre lette bikub-kommandoer, der er tilgængelige for python, rubin, C ++ og drivere. Disse klientapplikationsfordele ved eksekvering af forespørgsler på bikuben. Hive har tre typer af klientkategorisering: sparsomme klienter, JDBC og ODBC klienter.
Hive-tjenester:
At behandle alle forespørgsler bikub har forskellige tjenester. Alle funktioner defineres let af brugeren i bikuben. Lad os se alle disse tjenester kort:
- Kommandolinjegrænseflade (brugergrænseflade): Det muliggør interaktion mellem brugeren og bikuben, en standardskal. Det giver en GUI til udførelse af hive-kommandolinje og bikub-indsigt. Vi kan også bruge webgrænseflader (HWI) til at indsende forespørgsler og interaktioner med en webbrowser.
- Hive Driver: Den modtager forespørgsler fra forskellige kilder og klienter som sparselsserver og gemmer og henter på ODBC og JDBC driver, der automatisk er tilsluttet hive. Denne komponent foretager semantisk analyse for at se tabellerne fra metastoren, der analyserer en forespørgsel. Driveren tager hjælp af compiler og udfører funktioner som en parser, Planner, udførelse af MapReduce-job og optimizer.
- Compiler: Parring og semantisk proces for forespørgslen udføres af compileren. Det konverterer forespørgslen til et abstrakt syntaks-træ og igen tilbage til DAG for kompatibilitet. Optimisatoren opdeler på sin side de tilgængelige opgaver. Eksekutorens opgave er at køre opgaverne og overvåge pipelineplanen for opgaverne.
- Udførelsesmotor: Alle forespørgsler behandles af en udførelsesmotor. En DAG-sceneplaner udføres af motoren og hjælper med at styre afhængighederne mellem de tilgængelige trin og udføre dem på en korrekt komponent.
- Metastore: Det fungerer som et centralt arkiv til at gemme alle strukturerede oplysninger om metadata, også er det en vigtig del af bikuben, da den har oplysninger som tabeller og opdelingsdetaljer og opbevaring af HDFS-filer. Med andre ord skal vi sige, at metastore fungerer som et navneområde for tabeller. Metastore betragtes som en separat database, der også deles af andre komponenter. Metastore har to stykker, der kaldes service og backlog-opbevaring.
Hive-datamodellen er struktureret i Partitioner, spande, borde. Alle disse kan filtreres, have partitionstaster og for at evaluere forespørgslen. Hiveforespørgsel fungerer på Hadoop-rammen, ikke på den traditionelle database. Hive-server er en grænseflade mellem en ekstern klientforespørgsler til bikuben. Udførelsesmotoren er fuldstændigt indlejret i en hive-server. Du kan finde hive-applikationer i maskinlæring, forretningsinformation i detekteringsprocessen.
Work Flow of Hive:
Hive fungerer i to typer tilstande: interaktiv tilstand og ikke-interaktiv tilstand. Tidligere tilstand gør det muligt for alle bikubekommandoer at gå direkte til bikube, mens den senere type udfører kode i konsoltilstand. Data er opdelt i partitioner, som yderligere opdeles i spande. Udførelsesplaner er baseret på aggregering og dataskævhed. En ekstra fordel ved at bruge bikube er det let at behandle stor skala af information og har flere brugergrænseflader.
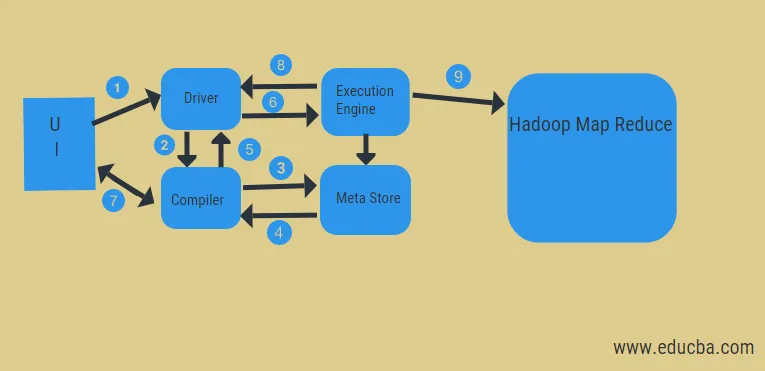
Fra ovenstående diagram kan vi få et glimt af datastrømmen i bikuben med Hadoop-systemet.
Trinene inkluderer:
- udfør forespørgslen fra brugergrænsefladen
- få en plan fra driveropgavens DAG-stadier
- få anmodning om metadata fra meta-butikken
- send metadata fra kompilatoren
- sender planen tilbage til chaufføren
- Udfør plan i udførelsesmotoren
- henter resultater for den relevante brugerforespørgsel
- sende resultater i to retninger
- udførelse af motorbehandling i HDFS med kortreduktion og hentning af resultater fra dataknudder oprettet af job tracker. det fungerer som et stik mellem Hive og Hadoop.
Udførelsesmotorens opgave er at kommunikere med knudepunkter for at få oplysningerne gemt i tabellen. Her udføres SQL-operationer som oprette, slippe, ændre for at få adgang til tabellen.
Konklusion:
Vi har gennemgået Hive Architecture og deres arbejdsgennemstrømning, hive udfører grundlæggende petabyte mængde data, og det er derfor et datalagerpakke på Hadoop-platformen. Da hive er et godt valg af håndtering af høj datavolumen, hjælper det med dataforberedelse med guide til SQL-interface til at løse MapReduce-problemer. Apache hive er et ETL-værktøj til at behandle strukturerede data. At kende brugen af bikivearkitektur hjælper forretningsfolk med at forstå det princip, der fungerer i bikuben, og har en god start med bikubeprogrammering.
Anbefalede artikler:
Dette har været en guide til Hive Architecture. Her diskuterer vi bikubens arkitektur, forskellige komponenter og arbejdsgangen i bikuben. kan du også se på de følgende artikler for at lære mere-
- Hadoop Arkitektur
- Brug af Ruby
- Hvad er C ++
- Hvad er MySQL-database
- Hive ordre af