

Introduktion til Data Mining
Her i denne artikel skal vi lære om introduktionen til Data mining, da mennesker har været minedrift fra jorden fra århundreder for at få alle mulige værdifulde materialer. Under minedrift opdages nogle gange tingene fra jorden, som ingen forventede at finde i første omgang. For eksempel i 1898, under udgravningen af en grav for at finde mumier i Saqqara, Egypten, blev der fundet en treartefakt, der nøjagtigt lignede et fly. Det blev dateret tilbage til 200 f.Kr., for omkring 2200 år siden! Men hvilke mulige oplysninger kunne vi få fra et stort sæt data? Og selv hvis vi begynder at udvinde det, er der nogen chancer for at få uventede resultater fra datasættet? Før det lad os undersøge, hvad der præcist er Data Mining.
Hvad er datamining?
- Det er dybest set udtrækningen af vital information / viden fra et stort datasæt.
- Tænk på data som en stor jorden / klippeflade. Vi ved ikke, hvad der er inde i det, vi ved ikke, om der er noget nyttigt under klipperne.
- I denne introduktion til Data mining er vi på udkig efter skjult information, men uden nogen idé om, hvilken type information vi ønsker at finde, og hvad vi planlægger at bruge dem til én gang, finder vi dem.
- Ligesom i Concept traditionel minedrift, er der også i Data mining en række teknikker og værktøjer, der varierer afhængigt af den type data, vi udvindes, så vi har klaret, at hvad der er data mining gennem dette emne med introduktion til Data mining.
Eksempel på Data Mining
Vi har lært om introduktionen til data mining i afsnittet ovenfor og fortsætter nu med eksemplerne på data mining, som er vist nedenfor:
- Så der er en mobilnetværksoperatør. De konsulterer en dataværker for at grave i operatørens opkaldsposter. Data Miner gives ingen specifikke mål.
- Der gives et kvantitativt mål for at finde mindst 2 nye mønstre i en måned.
- Når datominneren begynder at grave i dataene, finder han et mønster, at der er mindre internationale opkald på onsdag sammenlignet med andre dage.
- Disse oplysninger deles med ledelsen, og de har planen om at reducere de internationale opkaldspriser på onsdage og starte en kampagne.
- Opkaldspriser stiger, kunder er tilfredse med lav opkaldspris, flere kunder tilmelder sig, og virksomheden tjener flere penge! Win-win situation!
Med ovenstående eksempel i tankerne, lad os nu undersøge de forskellige trin, der er involveret i data mining.
Trin involveret i Data Mining
Vi har lært om introduktionen til data mining i ovenstående afsnit og går nu videre med trinene involveret i data mining, som er vist nedenfor: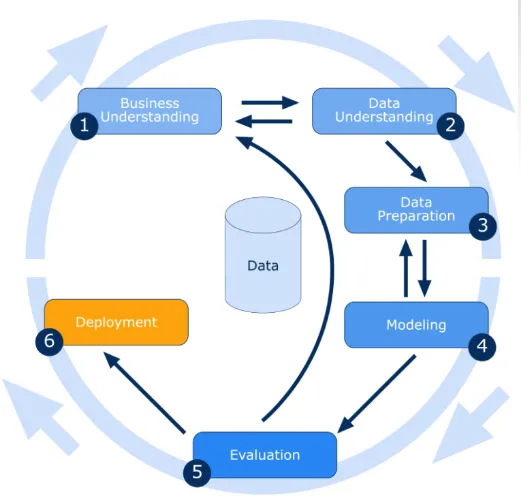
-
Forretningsforståelse
I denne introduktion til data mining vil vi forstå alle aspekter af forretningsmæssige mål og behov. Den aktuelle situation vurderes ved at finde ressourcer, antagelser og andre vigtige faktorer. Derfor etablere en god introduktion til data mining plan for at nå både forretnings- og data mining mål.
-
Dataforståelse
Oprindeligt indsamles dataene fra alle de tilgængelige kilder. Derefter vælger vi det bedste datasæt, hvorfra vi kan udtrække de data, der kunne være mere fordelagtige.
-
Dataforberedelse
Når datasættet er identificeret, vælges det, renses, konstrueres og formateres i den ønskede form.
-
Datamodellering
Det er en proces med ombygning af de givne data i henhold til brugerens krav. en eller flere modeller kunne oprettes i det forberedte datasæt, og til sidst skal modellerne vurderes omhyggeligt med involvering af interessenter for at sikre, at oprettede modeller opfylder forretningsinitiativer.
-
Evaluering
Dette er en af de mest nødvendige processer inden for data mining. Det inkluderer at gennemgå alle aspekter af processen for at kontrollere for eventuel fejl eller datalækage i processen. Der kunne også stilles nye forretningskrav på grund af de nye mønstre, der blev opdaget.
-
Deployment
Det betyder blot at præsentere viden på en sådan måde, at interessenterne kan bruge den, når de ønsker det. I vores ovenstående eksempel viste det sig, at internationale opkald var mindre på onsdage, så disse oplysninger blev præsenteret for interessenterne, som igen brugte denne information til deres fordel og øgede deres fortjeneste.
Teknikker, der bruges i datamining
I ovenstående afsnit har vi lært om introduktionen til data mining, nu går vi videre med de teknikker, der anvendes i data mining, som er anført nedenfor:
-
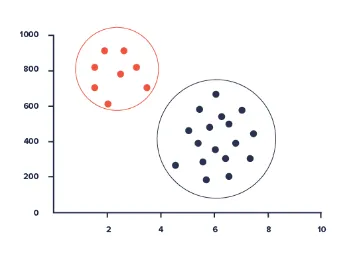
Cluster Analyse
Cluster Analysis giver mulighed for at identificere en given brugergruppe i henhold til almindelige funktioner i en database. Disse funktioner kan omfatte alder, geografisk placering, uddannelsesniveau og så videre.
-
Anomali-detektion
Det bruges til at bestemme, hvornår noget er mærkbart anderledes end det almindelige mønster. Det bruges til at eliminere enhver database uoverensstemmelser eller uregelmæssigheder ved kilden.

-
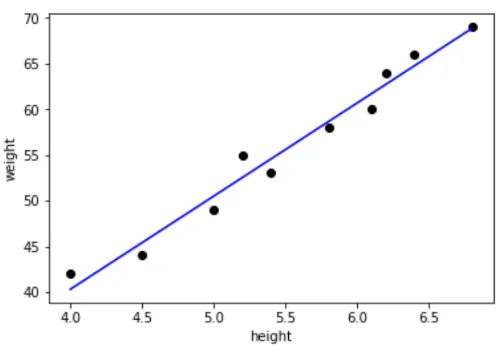
Regressions analyse
Denne teknik bruges til at foretage forudsigelser baseret på relationer inden for datasættet. For eksempel kan man forudsige lagersatsen for et bestemt produkt ved at analysere fortidskursen og også ved at tage hensyn til de forskellige faktorer, der bestemmer lagerraten. Eller som vist nedenfor, hvis vi har dataene om forskellige personers højde og vægt, så hvis vi har en hvilken som helst højde eller vægt, kunne vi bestemme den anden værdi.
-
Klassifikation
Dette omhandler de ting, der har etiketter på det. Bemærk ved klyngedetektion, tingene havde ikke en mærkning i det, og ved at bruge data mining var vi nødt til at mærke og forme i klynger, men i klassificering er der eksisterende oplysninger, der let kan klassificeres ved hjælp af en algoritme. Et eksempel er e-mail-spamfiltre. Spamfilteret leveres med både relevante og spam-meddelelser (Træningsdata). Forskellene mellem dem begge identificeres, hvilket gør det muligt for dem at klassificere fremtidige e-mails korrekt.

- Associativ læring
Det bruges til at analysere, hvilke ting der har tendens til at forekomme sammen enten i par eller større grupper. For eksempel folk, der har tendens til at købe citroner, købe appelsiner også, folk, der har tendens til at købe brød, købe mælk også osv. Så de indkøb, der foretages af alle kunder, analyseres, og de ting, der forekommer sammen, placeres tæt ved for at øge salget. Så mælk placeres tæt på brød, citroner placeres ved siden af appelsiner og så videre.

Er dataminering etisk?
Så jeg planlægger en weekendtur til Goa med en ven, jeg søger på internettet efter gode steder at besøge i Goa. Næste gang jeg åbner internettet, finder jeg annoncer om forskellige hoteller i Goa til ophold.
-
God ting?
Ja, internettet har hjulpet mig med at forenkle min rejse. Når alt kommer til alt, hvis jeg beslutter at besøge Goa, bliver jeg nødt til at sove et sted, og en annonce, der viser mig et hotel, er meget mere nyttig end en annonce, der viser mig tilfældigt tøj at købe.
-
Dårlig ting?
Ja! Hvorfor skulle et dataminingfirma, som jeg aldrig har hørt før, vide, hvor jeg skal på ferie. Hvad hvis jeg ikke har fortalt nogen om denne rejse, men her ved Internettet pludselig, at jeg skal der. Sandheden er, at forretningsmodellen for dataminingvirksomheden afhænger af dette. De indsamler disse data via cookies og scripts, så sælger de dem til annoncører, som igen forsøger at sælge mig noget andet (i dette tilfælde et hotelværelse).
Så det kan være godt eller dårligt afhængigt af den måde, vi ser på det. Vi kunne også altid slukke for cookies eller gå i inkognito i ovenstående tilfælde. Uanset hvad der er tilfældet, er en ting helt sikkert. Data mining er her for at blive.
Anbefalede artikler
Dette har været en guide til Introduktion til data mining. Her drøfter vi dens betydning, teknikker og trin involveret i introduktionen til data mining med et eksempel for bedre at forstå. Du kan også se på følgende artikler for at lære mere -
- Spørgsmål om dataindvindingsintervaller
- Predictive Analytics vs Data Mining
- Introduktion til datavidenskab
- Hvad er regressionsanalyse?