

Forskellen mellem Big Data og Apache Hadoop
Alt er på Internettet. Internettet har en masse data. Derfor er alt Big Data. Ved du, at 2, 5 Quintillion Bytes-data oprettes hver dag og hældes op som Big Data? Vores daglige aktiviteter som kommentarer, likes, poster osv. På sociale medier som Facebook, LinkedIn, Twitter og Instagram tilføjes som en Big Data. Det antages, at i 2020 vil der oprettes næsten 1, 7 megabyte data hvert sekund for hver person på jorden. Du kan forestille dig og overveje, hvor meget data der genereres, hvis hver enkelt person på jorden antager. I dag er vi forbundet og deler vores liv online. De fleste af os er tilsluttet online. Vi bor i et smart hjem og bruger smarte køretøjer og alle er forbundet til vores smarte telefoner. Forestil dig nogensinde, hvordan disse enheder bliver smart? Jeg vil gerne give dig et meget enkelt svar, det er på grund af at analysere den meget store datamængde, dvs. Big Data. Inden for fem år vil der være over 50 milliarder smarte tilsluttede enheder i verden, alle udviklet til at indsamle, analysere og dele data for at gøre vores liv mere behageligt.
Følgende er introduktionerne af Big Data vs Apache Hadoop
Introduktion af Term Big Data
Hvad er Big Data? Hvilken størrelse af data anses for at være stor og vil blive betegnet som Big Data? Vi har mange relative antagelser for udtrykket Big Data. Det er muligt, at datamængden siger, at 50 terabyte kan betragtes som big data for opstart, men det er muligvis ikke Big Data for virksomheder som Google og Facebook. Det er fordi de har infrastrukturen til at gemme og behandle den mængde data. Jeg vil gerne definere udtrykket Big Data som:
- Big Data er mængden af data lige ud over teknologiens evne til at gemme, administrere og behandle effektivt.
- Big Data er data, hvis skala, mangfoldighed og kompleksitet kræver ny arkitektur, teknikker, algoritmer og analyser for at styre dem og udtrække værdi og skjult viden fra den.
- Big data er højvolumen og høj hastighed og informationsaktiver af høj variation, der kræver omkostningseffektive, innovative former for informationsbehandling, der muliggør forbedret indsigt, beslutningstagning og procesautomation.
- Big Data henviser til teknologier og initiativer, der involverer data, der er for forskellige, hurtigt skiftende eller massive til, at konventionelle teknologier, færdigheder og infrastruktur kan adresseres effektivt. Sagt anderledes er volumen, hastighed eller variation af data for stor.
3 V's Big Data
- Volumen: Volumen refererer til det beløb / antal, hvormed data oprettes, som hver time Wal-Mart-kundernes transaktioner giver virksomheden omkring 2, 5 petabyte med data.
- Hastighed: Hastighed refererer til den hastighed, hvormed data bevæger sig, ligesom Facebook-brugere i gennemsnit sender 31, 25 millioner beskeder og se 2.77 millioner videoer hvert minut på hver eneste dag over internettet.
- Variation: Variety refererer til forskellige formater af data, der oprettes som strukturerede, semistrukturerede og ustrukturerede data. Ligesom at sende e-mails med vedhæftningen på Gmail er ustrukturerede data, mens udstationering af kommentarer med nogle eksterne links også betegnes som ustrukturerede data. Deling af billeder, lydklip, videoklip er en ustruktureret form for data.
At gemme og behandle denne enorme mængde, hastighed og mangfoldighed af data er et stort problem. Vi er nødt til at tænke på anden teknologi end RDBMS til Big Data. Det skyldes, at RDBMS kun er i stand til at gemme og behandle strukturerede data. Så her kommer Apache Hadoop som en redning.
Introduktion af Term Apache Hadoop
Apache Hadoop er en open source-software-ramme til lagring af data og kørsel af applikationer på klynger med råvaremateriale. Apache Hadoop er en softwareramme, der giver mulighed for distribueret behandling af store datasæt på tværs af computerklynger ved hjælp af enkle programmeringsmodeller. Det er designet til at skalere fra enkelt-servere til tusinder af maskiner, der hver tilbyder lokal beregning og opbevaring. Apache Hadoop er en ramme til lagring og behandling af Big Data. Apache Hadoop er i stand til at lagre og behandle alle formater af data som strukturerede, semistrukturerede og ustrukturerede data. Apache Hadoop er open source og råvareshardware bragt revolution til IT-industrien. Det er let tilgængeligt for alle niveauer af virksomheder. De behøver ikke at investere mere for at oprette Hadoop-klyngen og på forskellige infrastrukturer. Så lad os se den nyttige forskel mellem Big Data og Apache Hadoop i detaljer i dette indlæg.
Apache Hadoop-rammer
Apache Hadoop rammer er opdelt i to dele:
- Hadoop Distribueret filsystem (HDFS): Dette lag er ansvarligt for lagring af data.
- MapReduce: Dette lag er ansvarligt for behandling af data på Hadoop Cluster.
Hadoop Framework er opdelt i master- og slavearkitektur. Hadoop Distribueret filsystem (HDFS) lag Navn Node er masterkomponent, mens dataknudepunkt er slavekomponent, mens i MapReduce-lag er Job Tracker masterkomponent, mens task tracker er slavekomponent. Nedenfor er diagrammet for Apache Hadoop rammer.
Hvorfor er Apache Hadoop vigtig?
- Evne til hurtigt at gemme og behandle enorme mængder af enhver form for data
- Computing power: Hadoops distribuerede computermodel behandler big data hurtigt. Jo flere computernoder, du bruger, jo mere behandlingskraft har du.
- Fejltolerance: Data- og applikationsbehandling er beskyttet mod hardwarefejl. Hvis en knude falder, omdirigeres job automatisk til andre knudepunkter for at sikre, at den distribuerede computing ikke mislykkes. Flere kopier af alle data gemmes automatisk.
- Fleksibilitet: Du kan gemme så meget data, som du vil, og beslutte, hvordan du skal bruge dem senere. Det inkluderer ustrukturerede data som tekst, billeder og videoer.
- Lav pris: Open-source-rammen er gratis og bruger råvaremateriale til at gemme store mængder data.
- Skalerbarhed: Du kan nemt udvide dit system til at håndtere flere data ved blot at tilføje noder. Lille administration er påkrævet
Sammenligning fra hoved til hoved mellem Big Data vs Apache Hadoop (Infographics)
Nedenfor er Top 4 sammenligningen mellem Big Data vs Apache Hadoop
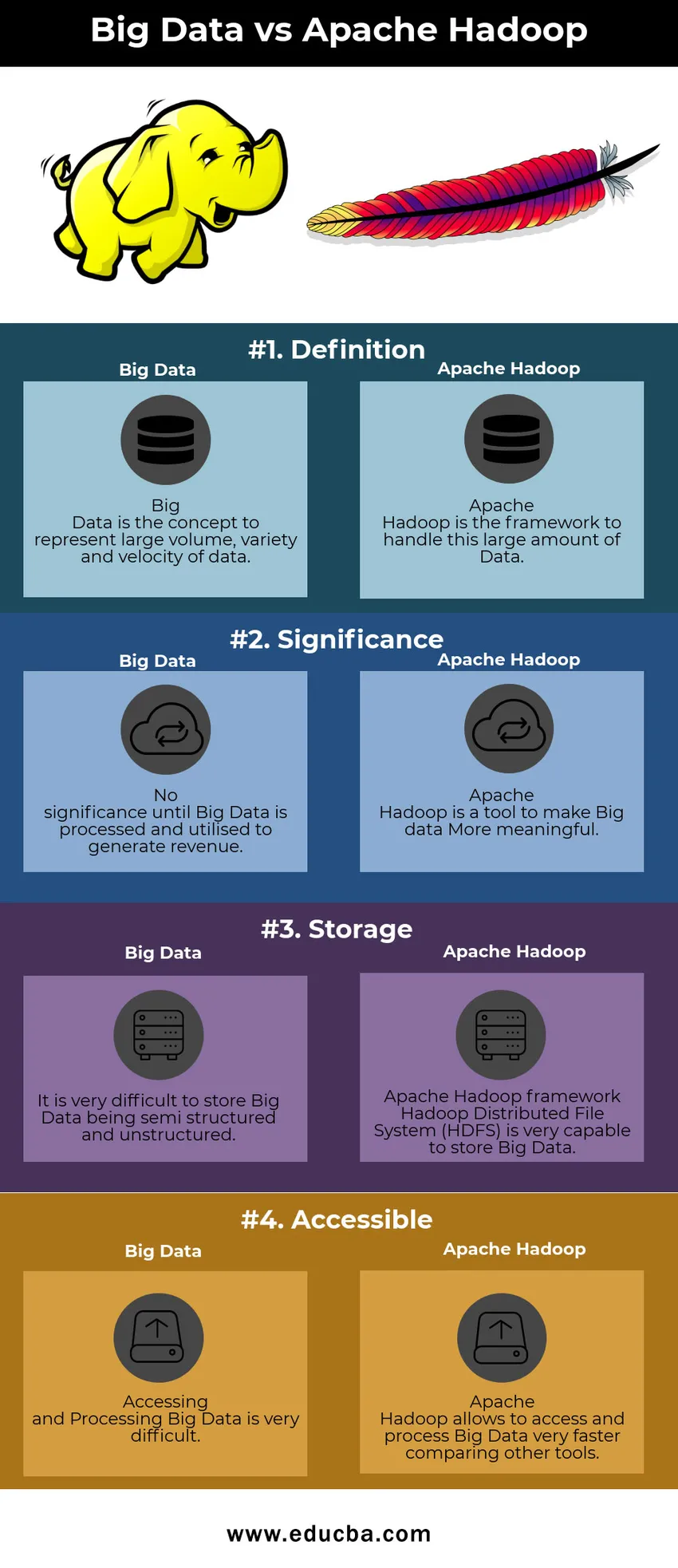
Big Data vs Apache Hadoop sammenligningstabel
Jeg diskuterer større artefakter og skelner mellem Big Data vs Apache Hadoop
| Big Data | Apache Hadoop | |
| Definition | Big Data er konceptet, der repræsenterer store mængder, variation og hastighed af data | Apache Hadoop er rammen for at håndtere denne store mængde data |
| Betydning | Ingen betydning, før Big Data er behandlet og brugt til at generere indtægter | Apache Hadoop er et værktøj til at gøre Big data mere meningsfuld |
| Opbevaring | Det er meget vanskeligt at gemme Big Data som semi-struktureret og ustruktureret | Apache Hadoop-ramme Hadoop Distribuerede Filsystem (HDFS) er meget i stand til at gemme Big Data |
| Tilgængelig | Adgang til og behandling af Big Data er meget vanskeligt | Apache Hadoop giver adgang til og behandler Big Data meget hurtigere sammenligning af andre værktøjer |
Konklusion - Big Data vs Apache Hadoop
Du kan ikke sammenligne Big Data og Apache Hadoop. Det skyldes, at Big Data er et problem, mens Apache Hadoop er løsning. Da mængden af data øges eksponentielt i alle sektorer, så det er meget vanskeligt at gemme og behandle data fra et enkelt system. Så for at behandle denne store mængde data har vi brug for distribueret behandling og lagring af data. Derfor kommer Apache Hadoop op med løsningen af at lagre og behandle en meget stor mængde data. Endelig vil jeg konkludere, at Big Data er en stor mængde komplekse data, hvorimod Apache Hadoop er en mekanisme til at lagre og behandle Big Data meget effektivt og glat.
Anbefalet artikel
Dette har været en guide til Big Data vs Apache Hadoop, deres betydning, sammenligning mellem hoved og hoved, nøgleforskelle, sammenligningstabel og konklusion. denne artikel består af al nyttig forskel mellem Big Data og Apache Hadoop. Du kan også se på de følgende artikler for at lære mere -
- Big Data vs Data Science - Hvordan er de forskellige?
- Top 5 Big Data-tendenser, som virksomheder bliver nødt til at mestre
- Hadoop vs Apache Spark - Interessante ting, du har brug for at vide
- Apache Hadoop vs Apache Spark | Top 10 sammenligninger, du skal vide!