

Sådan installeres Apache
Før vi går ind på, hvordan man installerer Apache-delen, ville vi først have et generelt overblik over Apache, og hvordan det bruges i datavidenskab.
Hvad er Apache?

Apache Web Server er en HTTP-server, der præsenterer websteder for besøgende, der kommer til din server. Så hvis du vil implementere et websted til en virksomhed eller din organisation, vil du sandsynligvis bruge Apache til det.
Der er andre HTTP-servere derude, såsom IIS, men Apache er den standard, som de fleste mennesker bruger, uanset om de er på Linux, Windows eller Mac. Apache er den standard, som de fleste mennesker går til, fordi det er velkendt, det er meget pålideligt, og det er gratis.
En ting at indse med Apache er imidlertid, at det, som det er en HTTP-server, så hvis du installerer dette på Linux eller Windows eller Mac, alt det, du vil gøre, er at præsentere statiske websteder for besøgende, der kommer til din server. Derfor, hvis du kode ud et HTML-websted uden andre programmeringssprog end JavaScript, kan du bruge det med bare en Apache-server. Du kan tilslutte alle dine tags til Apache-serveren og præsentere dem for dine besøgende.
Hvordan brugte Apache i Data Science?
Data Science er det mest efterspurgte studieområde i den moderne verden. Data Scientist betragtes som det mest sexy job i det 21. århundrede med fagfolk fra forskellige discipliner, der ønsker at lære og blive en Data Scientist. Apache spiller en afgørende rolle i enhver datavidenskabelig entusiast, da de har brug for tilstrækkelig viden om Apache Hadoop-økosystemet.
Apache Hadoop økosystem
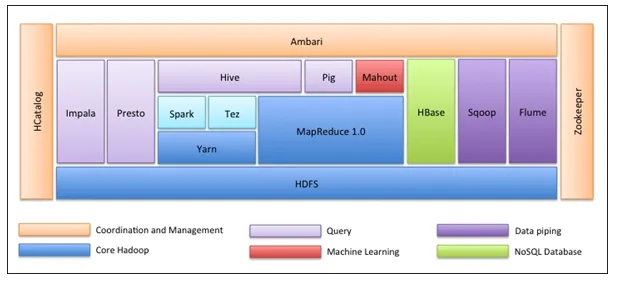
Den allerførste ting er, at Hadoop økosystem ikke er et værktøj. Det er ikke et programmeringssprog eller en enkelt ramme. Det er en gruppe værktøjer, der bruges sammen af forskellige virksomheder i forskellige domæner til flere opgaver. Vi vil gennemgå hvert værktøj en efter en nedenfor: -
- Apache HDFS (Hadoop Distribueret filsystem) er lagringsenheden i Hadoop, der kunne gemme strukturerede, semistrukturerede og ustrukturerede data. HDFS har metadata, som vedligeholder logfilen om de lagrede data. Det har to komponenter - NameNode og DataNode.
- Apache Yarn er ressourceforhandleren, der udfører alle behandlingsaktiviteter som planlægningsopgaver, allokering af ressourcer osv. Det har to tjenester - For det første er Resource Manager, der planlægger applikationer, der kører oven på Garnet. For det andet er Node Manager, der overvåger ressourceudnyttelse .
- Apache Map Reduce er dataprocessorkomponenten i Hadoop, der behandler store datasæt ved hjælp af distribueret og parallel computing baseret på Map, Sort and Shuffle og Reduce-funktioner. Kortfunktion filtrerer dataene, derefter sorteres og blandes ud og til sidst Reducer funktionsaggregater og opsummerer resultatet.
- Apache Pig bruges mest i ETL. Det har to dele - Gris Latin og Grisen runtime. Gris-latin er det sprog, der bruges til databehandling ved hjælp af en forespørgsel, mens svinekørsel er eksekveringsmiljøet. En linje af svin Latin er næsten lig med 100 linjer af kort reducere kode. Processen involverer først at indlæse dataene og derefter gruppere, sortere, filtrere og gemme dem i HDFS.
- Apache Hive bruger en SQL-lignende forespørgsel til at analysere data i et distribueret miljø. Det har to komponenter - Hive-kommandolinjen og JDBC / ODBC-serveren, og det anvendte sprog kaldes HiveQL.
- Apache Mahout er biblioteket Machine Learning, der er skrevet i Java og bruges til at oprette applikationer til maskinindlæring såsom klynger, klassificering eller regression. Det har forskellige algoritmer indbygget til forskellige brugssager.
- Apache HBase er en NoSQL-database skrevet i Java, der løber over Hadoop. Det er bygget baseret på Googles BigTable og er i stand til at håndtere alle typer data.
- Apache Sqoop er et værktøj til indtagelse af data, der bruges til bulkstruktureret dataoverførsel mellem RDBMS og Hadoop.
- Apache Flume er et andet dataindtagelsesværktøj, der bruges til semistruktureret og ustruktureret dataoverførsel mellem Hadoop og andre datakilder.
- ZooKeeper er koordinatoren, der sikrer koordinering mellem forskellige værktøjer i Hadoop-økosystemet.
- Apache Ambari er en Cluster Manager, der leverer, administrerer Hadoop-klynger og overvåger også deres helbred og status.
- Apache Tez er et nyt værktøj i Hadoop-økosystemet, der accelererer Hadoop's Query-behandling.
- Apache Presto er en open source distribueret SQL-forespørgselsmotor, der muliggør forespørgselfunktion på tværs af platforme.
- Apache HCatalog er et metadata- og tabelstyringssystem til Hadoop, der muliggør interoperabilitet på tværs af databehandlingsværktøjer. Det hjælper også brugere med at vælge de bedste værktøjer til deres miljøer.
- Apache Spark er den mest anvendte og populære ramme blandt Data Scientist. Det er et højhastighedscomputersystem, der optimerer ressourceudnyttelsen i tilfælde af mange iterative opgaver. Det giver fleksibilitet til både batchbehandling og realtidsdataanalyse.
Nedenfor er trinnene til installation af Apache
Indtil videre har vi lært om Apache, og hvordan det er nyttigt for alle, der vil lære Data Science eller Big Data Analytics. Nu vil vi dykke ned og installere apache på windows baseret på nedenstående trin.
- Gå til https://httpd.apache.org/ og klik på Download-linket under afsnittet Apache httpd 2.4.38 Udgivet.

- Det fører dig til følgende side, og klik derefter på Filer til Microsoft Windows.
- Klik på Apache Lounge.

- Du kan downloade 32-bit eller 64-bit af zip-filen baseret på dit Windows-operativsystem. Vi vil downloade 64-bit version her. Klik på det tilsvarende .zip-link for at downloade.

- Nu kræver det C ++ Redistributable Visual Studio 2017. Så vi henter det fra det tilsvarende 32-bit eller 64-bit link

- Når begge filerne er blevet downloadet, går vi den downloadede placering og installerer C ++ Redistributable Visual Studio 2017 først. Dobbeltklik på .exe-filen.

- Marker 'Jeg er enig', og klik på Installer.

- Installation af Apache er i gang.
- Når den er færdig, får du en meddelelse som denne. Klik på Luk for at afslutte installationen.
- Gå nu til den mappe, hvor du downloader Apache zip-filen. Højreklik på det og vælg uddrag her.
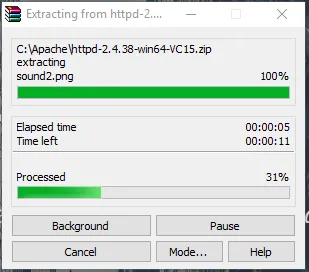
- Nu får vi en Apache24-mappe oprettet. Kopier denne mappe til C-drev, og så tilføjer vi en sti til systemmiljøvariabler.
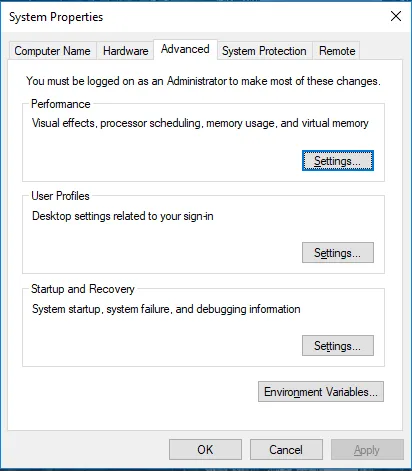
Gå til Systemegenskaber -> fanen Avanceret -> Klik på knappen Miljøvariabler nedenfor.
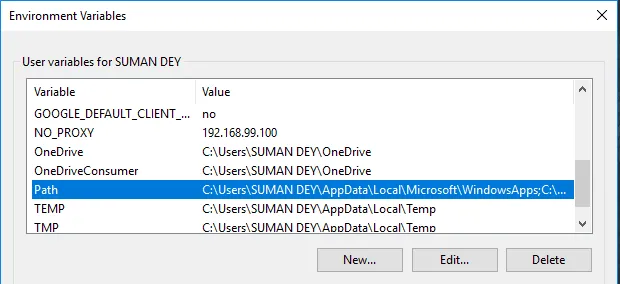
- Find sti i variabler og klik på Rediger.
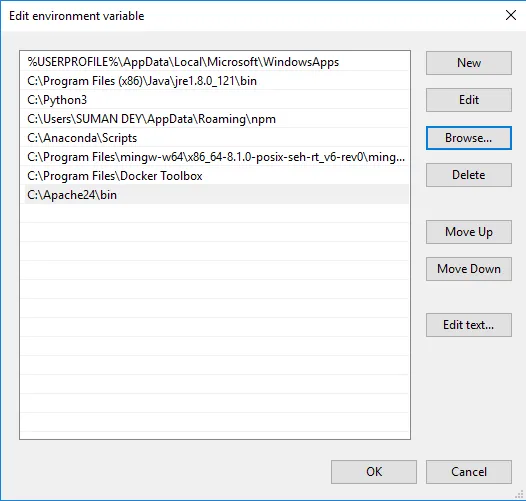
- Klik på Gennemse -> Gå til C-drev Apache24-mappen -> Vælg bin-mappe -> Klik på OK.
- Vi installerer Apache som en Windows-service. Kør Kommandopromp som administrator. Skriv httpd –k installation, og tryk på Enter.
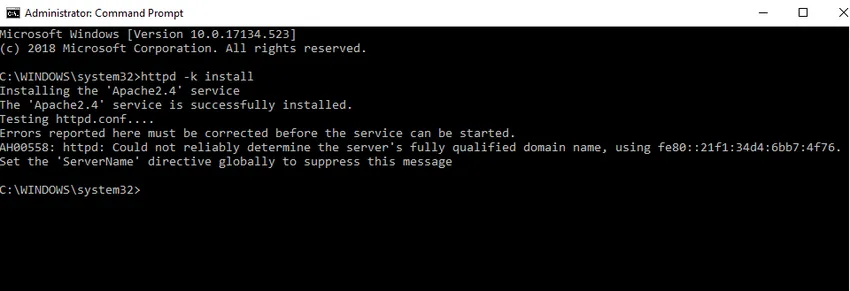
- Vi tjekker installationen af Apache-tjenesten. Klik på Windows-ikonet, og skriv tjenester. Klik på appen Tjenester og find service med navnet Apache24.

- For at starte Apache-serveren skal du højreklikke på den og klikke på start. Status skifter til 'Kører'.
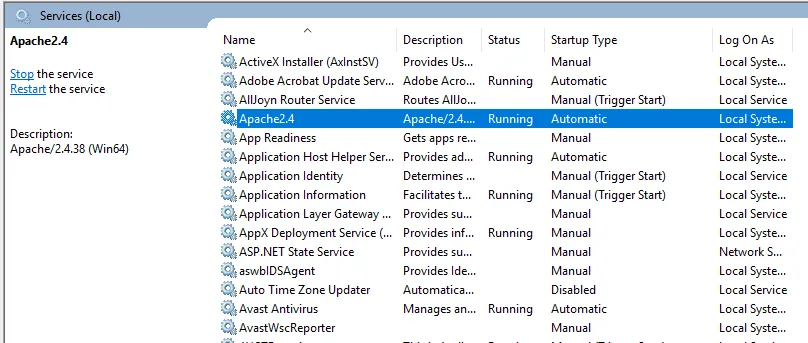
- Vi kan teste med en browser. Åbn en browser, og gå til http: // localhost, og tryk på Enter. En meddelelse om "Det fungerer!" vises for at bekræfte vellykket installation af Apache.
Anbefalede artikler
Dette har været en guide til, hvordan man installerer Apache. Her har vi drøftet instruktionerne og forskellige trin til installation af Apache. Du kan også se på den følgende artikel for at lære mere -
- Spørgsmål om Apache-interview
- Apache Spark vs Apache Flink
- Apache Hadoop vs Apache Spark
- Apache Kafka vs Flume
- Kafka vs Kinesis | Topforskelle