
Introduktion til ensembleteknikker
Ensemblæring er en teknik i maskinlæring, der tager hjælp af flere basismodeller og kombinerer deres output for at producere en optimeret model. Denne type maskinlæringsalgoritme hjælper med at forbedre modellens samlede ydeevne. Her er den basismodel, der er mest almindeligt anvendt, beslutnings træklassificeren. Et beslutningstræ arbejder dybest set på flere regler og giver et forudsigeligt output, hvor reglerne er knudepunkter og deres beslutninger vil være deres børn, og bladknudepunkterne udgør den ultimative beslutning. Som vist i eksemplet på et beslutningstræ.
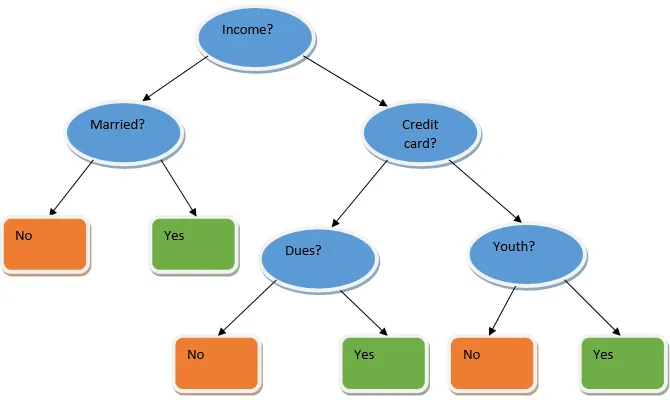
Ovenstående beslutningstræ taler dybest set om, hvorvidt en person / kunde kan få et lån eller ej. En af reglerne for låneberettigelse ja er, at hvis (indkomst = Ja && Gift = Nej) Så lån = Ja, så det er sådan en beslutning træ klassificerer fungerer. Vi vil inkorporere disse klassifikatorer som en multiple basismodel og kombinere deres output for at opbygge en optimal forudsigelsesmodel. Figur 1.b viser det samlede billede af en ensemble-indlæringsalgoritme.
Typer af ensembleteknikker
Forskellige typer ensembler, men vores hovedfokus vil være på de to følgende typer:
- afsækningskapacitet
- Øget
Disse metoder hjælper med at reducere variansen og biasen i en maskinlæringsmodel. Lad os nu prøve at forstå, hvad der er bias og varians. Bias er en fejl, der opstår på grund af forkerte antagelser i vores algoritme; en høj bias indikerer, at vores model er for enkel / underfit. Variance er den fejl, der er forårsaget på grund af modelens følsomhed over for meget små udsving i datasættet; en høj varians indikerer, at vores model er meget kompleks / overfit. En ideel ML-model skal have en ordentlig balance mellem bias og varians.
Bootstrap Aggregating / Bagging
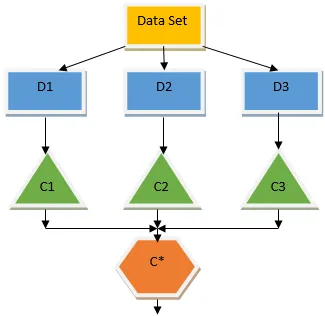
Bagging er en ensembleteknik, der hjælper med at reducere variansen i vores model og dermed undgår overmontering. Bagging er et eksempel på den parallelle indlæringsalgoritme. Sækkeværker baseret på to principper.
- Bootstrapping: Fra det originale datasæt betragtes forskellige prøvepopulationer med udskiftning.
- Sammenlægning: Gennemsnittet af resultaterne fra alle klassificeringsmaskiner og tilvejebringelse af en enkelt output, for dette bruger den flertalsafstemning i tilfælde af klassificering og gennemsnit i tilfælde af regressionsproblemet. En af de berømte maskinlæringsalgoritmer, der bruger begrebet bagging er en tilfældig skov.
Tilfældig skov
I tilfældig skov fra den tilfældige prøve, der trækkes tilbage fra befolkningen med udskiftning, og en undergruppe af funktioner vælges fra sættet med alle de funktioner, et beslutnings træ er bygget. Fra disse undergrupper af funktioner, uanset hvilken funktion der giver den bedste opdeling, vælges som roden til beslutningstræet. Funktionsundersættet skal vælges tilfældigt for enhver pris, ellers vil vi ende med at producere kun korreleret lokk, og variansen af modellen forbedres ikke.
Nu har vi bygget vores model med de prøver, der er taget fra populationen, spørgsmålet er, hvordan validerer vi modellen? Da vi overvejer prøverne med udskiftning, vil alle prøver derfor ikke blive taget i betragtning, og noget af det vil ikke blive inkluderet i nogen pose, disse kaldes ud af poseprøver. Vi kan validere vores model med denne OOB (ud af taske) prøver. De vigtige parametre, der skal overvejes i en tilfældig skov, er antallet af prøver og antallet af træer. Lad os betragte 'm' som en del af funktioner, og 'p' er det komplette sæt funktioner, nu som en tommelfingerregel, er det altid ideelt at vælge
- m som √ og en minimum nodestørrelse som 1 for et klassificeringsproblem.
- m som P / 3 og minimum nodestørrelse til at være 5 for et regressionsproblem.
M og p skal behandles som indstillingsparametre, når vi håndterer et praktisk problem. Træningen kan afsluttes, når OOB-fejlen stabiliseres. En ulempe ved den tilfældige skov er, at når vi har 100 funktioner i vores datasæt, og kun et par funktioner er vigtige, vil denne algoritme fungere dårligt.
Øget
Boosting er en sekventiel læringsalgoritme, der hjælper med at reducere bias i vores model og varians i nogle tilfælde af overvåget læring. Det hjælper også med at konvertere svage elever til stærke elever. Boosting fungerer efter princippet om at placere de svage elever i rækkefølge, og det tildeler en vægt til hvert datapunkt efter hver runde; mere vægt tildeles det misklassificerede datapunkt i den foregående runde. Denne sekventielt vægtede metode til træning af vores datasæt er den nøgleforskel, der gælder for bagging.
Fig. 3 viser den generelle tilgang til boosting
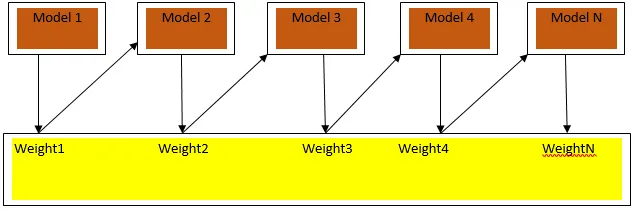
De endelige forudsigelser kombineres baseret på vægtet flertal for afstemning i tilfælde af klassificering og vægtet sum i tilfælde af regression. Den mest udbredte boostingalgoritme er adaptiv boosting (Adaboost).
Adaptiv boosting
Trinene involveret i Adaboost-algoritmen er som følger:
- For de givne n datapunkter definerer vi målgruppen og initialiserer alle vægte til 1 / n.
- Vi passer klassificatorerne til datasættet, og vi vælger klassificeringen med den mindst vægtede klassificeringsfejl
- Vi tildeler vægte til klassificeren ved hjælp af en tommelfingerregel baseret på nøjagtighed, hvis nøjagtigheden er mere end 50%, så er vægten positiv og vice versa.
- Vi opdaterer klassificeringernes vægt ved slutningen af iterationen; opdaterer vi mere vægt for det misklassificerede punkt, så vi i den næste iteration klassificerer det korrekt.
- Efter al iteration får vi det endelige forudsigelsesresultat baseret på flertalets afstemning / det vejede gennemsnit.
Adaboosting fungerer effektivt med svage (mindre komplekse) elever og med klassiske klassificeringshøjder. De største fordele ved Adaboosting er, at det er hurtigt, der er ingen indstillingsparametre, der ligner tilfældet med bagging, og vi gør ingen antagelser for svage elever. Denne teknik undlader at give et nøjagtigt resultat, når
- Der er flere outliers i vores data.
- Datasættet er utilstrækkeligt.
- De svage elever er meget komplekse.
De er også følsomme over for støj. De beslutningstræer, der produceres som et resultat af boosting, vil have begrænset dybde og høj nøjagtighed.
Konklusion
Ensemble-læringsteknikker er vidt brugt til at forbedre modelnøjagtigheden; vi er nødt til at beslutte, hvilken teknik vi skal bruge baseret på vores datasæt. Men disse teknikker foretrækkes ikke i nogle tilfælde, hvor tolkbarhed er vigtig, da vi mister tolkbarhed på bekostning af præstationsforbedring. Disse har en enorm betydning i sundhedsvæsenet, hvor en lille forbedring af ydeevnen er meget værdifuld.
Anbefalede artikler
Dette er en guide til Ensembleteknikker. Her diskuterer vi introduktionen og to hovedtyper af ensembleteknikker. Du kan også gennemgå vores andre relaterede artikler for at lære mere-
- Steganografiteknikker
- Maskinindlæringsteknikker
- Teambuilding-teknikker
- Data Science algoritmer
- Mest anvendte teknikker til ensemblæring