

Hvad er Kafka?
For at forstå Kafka er det bedre at forstå, hvad 'Streambehandling'-teknologi er. 'Streambehandling er en teknologi, som en bruger kan spørge om en kontinuerlig datastrøm i en mikrotidsramme for bedre at forstå de underliggende forhold, der er ansvarlige.
Et realtidsscenarie - forestil dig, om din temperatursensor sender data, som du kan forespørge og modtage en advarsel efter at et frysepunkt er modtaget. Denne dataforespørgsel kan udføres i mikrosekunder.
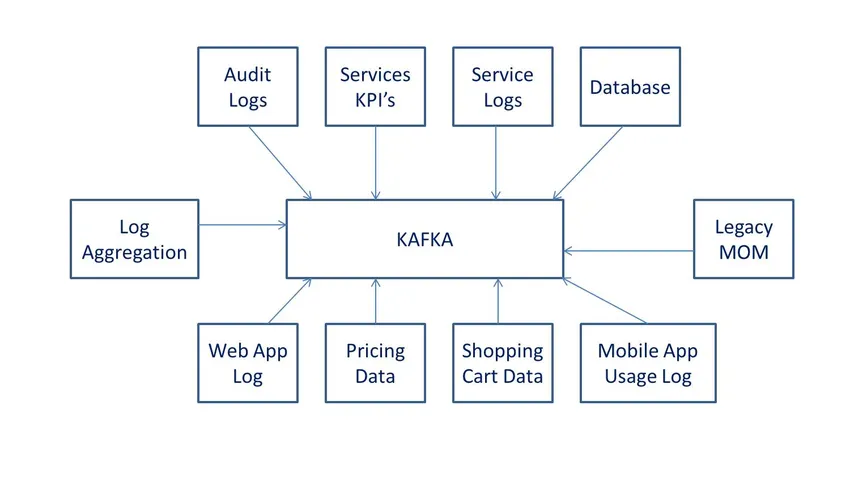
Definitioner
ifølge Wiki er det open source-databehandlingssoftware. Det blev udviklet af LinkedIn og senere doneret til Apache-software.
Forståelse af Kafka
Dens vækst eksploderer eksponentielt. Lad os se nogle fakta og statistikker for bedre at understrege vores tanke. Det nyder godt af mere end en tredjedel af Fortune 500 over hele kloden. Denne distribution deles af rejsefirmaer, telekommunikagiganter, banker og flere andre. LinkedIn, Microsoft og Netflix behandler fire komma-meddelelser om dagen med Kafka (næsten svarer til 1.000.000.000.000).
Det bruges til realtidsstrømme af data, til at indsamle big data eller til at udføre realtidsanalyse (eller begge dele). Kafka bruges med mikroservices i hukommelsen for at give holdbarhed, og det kan bruges til at fodre begivenheder til CEP (komplekse begivenhedsstrømningssystemer) og IoT / IFTTT-automatiseringssystemer.
Hvordan fungerer Kafka så let?
Drevet af enkelhed ville være den rigtige måde at definere ydelsen på. Det er nemt at finde ud af, hvordan Kafka fungerer så let fra opsætning og brug. Denne øgede ydeevne i adfærd er dedikeret til dens stabilitet, dens levering til pålidelig holdbarhed med sin fleksible indbyggede evne til at offentliggøre eller abonnere eller vedligeholde kø. Dette er meget vigtigt at have, hvis du er nødt til at håndtere N - antal klientgrupper, hvis du skal vise en robust replikation på markedet med det formål at give dine kunder en ensartet tilgang (dvs. Kafka-emnepartition). En afgørende opførsel af Kafka, der adskiller den fra sine konkurrenter, er dens kompatibilitet med systemer med datastrømme - dens proces og gør det muligt for disse systemer for at aggregere, transformere og indlæse andre butikker til bekvemmelighedsarbejde. ”Alle ovennævnte fakta ville ikke være mulige, hvis Kafka var langsom”. Dets ekstraordinære ydelse gør dette muligt.
Med yderligere tilføjelse til Kafka-lethedets arbejde skal vi gå til “OS-niveau”. Lad os finde ud af, hvordan ting fungerer for Kafka på OS-niveau -
- Det er afhængig af OS-kerner for at flytte data hurtigere og fungerer på princippet om nulkopi.
- Det tillader dataposter at batches i bunker, der kan ses fra filsystemet (alias Kafka-emnelog) til forbrugerne.
- Faciliteten til batchdata giver en effektiv datakomprimering med I / O-latenstidsreduktion.
- Det har evnen til at skalere vandret via afskærmning. Det kan skære en titellog ind i hundreder af partitioner til tusinder. Dette gør det nemt at håndtere den enorme arbejdsbyrde.
Hvad kan du gøre med Kafka?
Hvis din virksomhed spiller med enorme datasæt regelmæssigt, har du brug for Kafka. Der er en lang liste over virksomheder, der bruger den.
- LinkedIn bruger til at spore data og operationelle målinger.
- Twitter til levering af strømforarbejdningsinfrastrukturer.
Der er en lang liste over virksomheder fra Uber til Spotify og Goldman Sachs til Cisco.
Fordele
- Høj kapacitet: Det kan nemt håndtere en stor datamængde, når generering med høj hastighed er en ekstraordinær fordel til fordel for Kafka. Denne applikation mangler enorm hardware. Med kapacitet til at understøtte beskedgennemstrømning med en frekvens på tusinder af meddelelser pr.
- Lav latens : Lav latenshåndtering af denne generering af højvolumenmeddelelser.
- Fejltolerance: Denne funktion er meget nyttig, den har en iboende evne til at blive begrænset af knudepunkt indbygget i en klynge.
- Holdbar: den er meget holdbar i sin drift, og det er derfor, mange MNC'er foretrækker at bruge Kafka. Når vi taler om holdbarhed under operationer, kan beskederne ikke gå tabt på lang sigt.
Nødvendige færdigheder
Der er ikke noget særligt krav for at være professionel i Kafka. Men vi har understreget nogle streams og fagfolk -
- Udviklere, der villigt ønsker at gøre en karriere i Big Data-strømmen og ønsker at fremskynde karrieren der.
- Testning af professionelle har et godt omfang i Kafka med hensyn til kø- og meddelelsessystemer
- Arkitekter - da alt har brug for nogle rammer, og denne ramme kan opdateres fra tid til anden. Big Data arkitekter ville finde Kafka som en god karriereinvestering.
- Projektleder er nødvendig, hvis ovenstående professionelle er der for bedre styring af ressourcerne. Så der er også højere positioner til rådighed for management-fagfolk inden for Kafka.
Hvorfor bruge Kafka?
Med det formål at spore og manipulere dem i henhold til forretningsbehovet foretrækkes Kafka verden over. Det giver mulighed for at streame data i realtid med realtidsanalyse. Det er hurtigt, skalerbart og holdbart og designet som fejltolerance. Der er tilfælde med flere brug på nettet, hvor du kan se, hvorfor JMS, RabbitMQ og AMQP ikke engang anses for at arbejde med, da behovet er at betjene enormt volumen og lydhørhed.
Det har en høj gennemstrømning, pålidelig opsætning med replikeringsegenskaber, hvilket gør det til et foretrukket valg at arbejde på IoT-sensorer.
Kompatibilitet er en anden grund til at bruge det og gjort det acceptabelt overalt i verden. Det kan let konfigureres til at arbejde med nedenstående program. Denne kombination er meget vigtig for mange virksomheder at vokse forretning og overleve (da det sparer tid og penge).
- Flume
- Gnist streaming
- HBase
- Gnist til indtagelse, behandling og analyse af data i realtid.
- Det er vant til at fodre Hadoop BigData
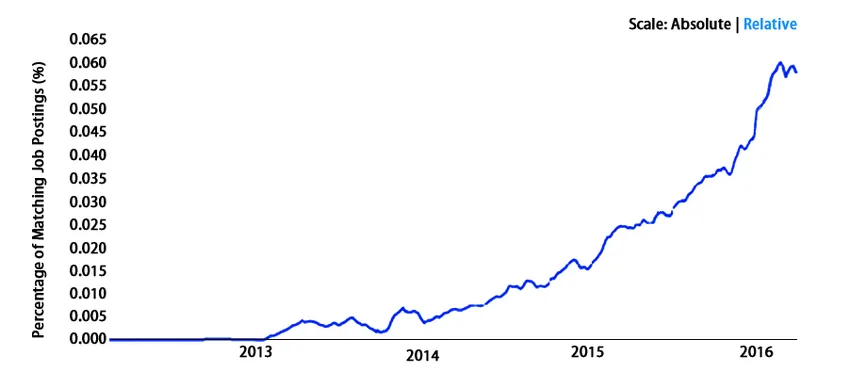
Anvendelsesområde
Det klarer sig godt over hele kloden. Vi siger ikke snarere statistikker. Lad os kigge på det -
Lønstatistikker for Kafka-fagfolk - PayScale
- Software Engineer - $ 109.825
- Data Engineer - $ 109.580
- Udviklere - $ 81.182
- Senior Data Engineer - $ 127, 836
Konklusion
På nuværende tidspunkt er Kafka blevet de-facto-standarden, når det kommer til realtidsdataanalyse med den højeste præcision i mikrosekunder. Vi har præsenteret vores indsigt med hensyn til data og detaljer til støtte for Kafka-teknologier. Der er flere store virksomheder, der udnytter data dagligt, ved at gøre dette har de brug for fagfolk til at udnytte disse enorme datasæt. Med Kafka kan man være sikker på at lede deres karriere i en BigData-analyse
Anbefalede artikler
Dette har været en guide til Hvad er Kafka. Her drøftede vi Kafka's arbejde, omfang, karrierevækst og fordele. Du kan også gennemgå vores andre foreslåede artikler for at lære mere -
- Hvad er Apache?
- Hvad er Big data og Hadoop?
- Hvad er Azure?
- Hvad er Big Data Technology?
- Kafka vs gnist | Top 5 forskelle
- Oversigt og top applikationer af Kafka
- Kafka vs Kinesis | 5 Forskelle med infografik