
Introduktion til hierarkisk klynge
- For nylig bad en af vores kunder vores team om at få frem en liste over segmenter med en rækkefølge af betydning inden for deres kunder for at målrette dem til at franchise et af deres nyligt lancerede produkter. Det er klart, at bare segmentering af kunderne ved hjælp af delvis klynge (k-middel, c-fuzzy) ikke fremlægger rækkefølgen af betydning, det er her, hierarkisk klynge indgår i billedet.
- Hierarkisk klynge er at opdele dataene i forskellige grupper baseret på nogle lighedstiltag kendt som klynger, som i det væsentlige er mål at opbygge hierarkiet blandt klynger. Det er dybest set uovervåget læring, og valg af attributter til måling af lighed er applikationsspecifik.
Klyngen af datahierarki
- Agglomerativ klynge
- Opdelende klynger
Lad os tage et eksempel på data, karakterer opnået af 5 studerende for at gruppere dem til en kommende konkurrence.
| Studerende | Marks |
| EN | 10 |
| B | 7 |
| C | 28 |
| D | 20 |
| E | 35s |
1. Agglomerativ klynge
- Til at begynde med betragter vi hvert enkelt punkt / element her vægt som klynger og fortsætter med at fusionere de lignende punkter / elementer for at danne en ny klynge på det nye niveau, indtil vi sidder tilbage med den enkelte klynge, er en bottom-up tilgang.
- Enkelt kobling og komplet kobling er to populære eksempler på agglomerativ gruppering. Bortset fra den gennemsnitlige kobling og Centroid-linking. I enkelt kobling fletter vi i hvert trin de to klynger, hvis to nærmeste medlemmer har den mindste afstand. I komplet kobling flettes vi sammen medlemmerne af den mindste afstand, der giver den mindste maksimale parvise afstand.
- Nærhedsmatrix, det er kernen til udførelse af hierarkisk klynger, som giver afstanden mellem hvert af punkterne.
- Lad os lave nærhedsmatrix for vores data, der er angivet i tabellen, da vi beregner afstanden mellem hvert af punkterne med andre punkter, det vil være en asymmetrisk matrix med form n × n, i vores tilfælde 5 × 5 matrixer.
En populær metode til afstandberegning er:
- Euklidisk afstand (kvadrat)
dist((x, y), (a, b)) = √(x - a)² + (y - b)²
- Manhattan afstand
dist((x, y), (a, b)) =|x−c|+|y−d|
Euklidisk afstand er mest almindeligt anvendt, vi bruger den samme her, og vi går med kompleks sammenkobling.
| Studerende (Clusters) | EN | B | C | D | E |
| EN | 0 | 3 | 18 | 10 | 25 |
| B | 3 | 0 | 21 | 13 | 28 |
| C | 18 | 21 | 0 | 8 | 7 |
| D | 10 | 13 | 8 | 0 | 15 |
| E | 25 | 28 | 7 | 15 | 0 |
Diagonale elementer i nærhedsmatrix vil altid være 0, da afstanden mellem punktet med det samme punkt altid vil være 0, hvorfor diagonale elementer er fritaget for hensyntagen til gruppering.
Her, i iteration 1, er den mindste afstand 3, så vi fletter A og B til dannelse af en klynge, danner igen en ny nærhedsmatrix med klynge (A, B) ved at tage (A, B) klyngepunkt som 10, dvs. maksimalt ( 7, 10) så nyligt dannet nærhedsmatrix ville være
| Klynger | (A, B) | C | D | E |
| (A, B) | 0 | 18 | 10 | 25 |
| C | 18 | 0 | 8 | 7 |
| D | 10 | 8 | 0 | 15 |
| E | 25 | 7 | 15 | 0 |
I iteration 2, 7 er den minimale afstand, derfor fletter vi C og E og danner en ny klynge (C, E), vi gentager processen, der blev fulgt i iteration 1, indtil vi ender med den enkelte klynge, her stopper vi ved iteration 4.
Hele processen er afbildet i nedenstående figur:
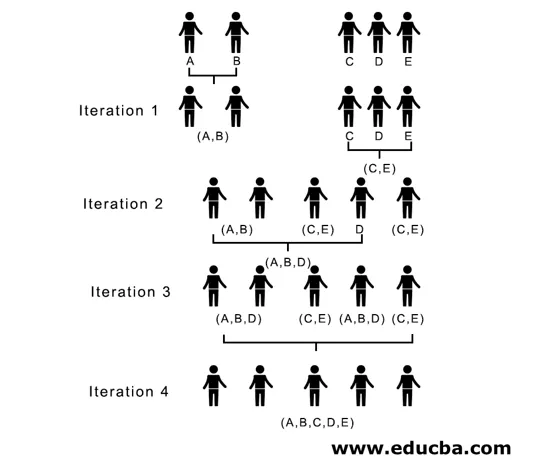
(A, B, D) og (D, E) er de 2 klynger, der er dannet ved iteration 3, ved den sidste iteration kan vi se, at vi står tilbage med en enkelt klynge.
2. Opdelende klynger
Til at begynde med betragter vi alle punkter som en enkelt klynge og adskiller dem med den fjerneste afstand, indtil vi ender med individuelle punkter som individuelle klynger (ikke nødvendigvis kan vi stoppe i midten, afhænger af det minimale antal elementer, vi ønsker i hver klynge) på hvert trin. Det er bare det modsatte af agglomerativ klynge, og det er en top-down tilgang. Opdelende klynger er en måde, som gentagne k betyder klynge på.
Valg mellem agglomerativ og splittende klynge er igen applikationsafhængig, men alligevel er der få punkter, der skal overvejes:
- Opdelende er mere kompleks end agglomerativ gruppering.
- Opdelende klynger er mere effektiv, hvis vi ikke genererer et komplet hierarki ned til individuelle datapunkter.
- Agglomerativ klynge træffer en beslutning ved at overveje de lokale klappere uden at tage højde for globale mønstre, der oprindeligt ikke kan vendes.
Visualisering af hierarkisk klynge
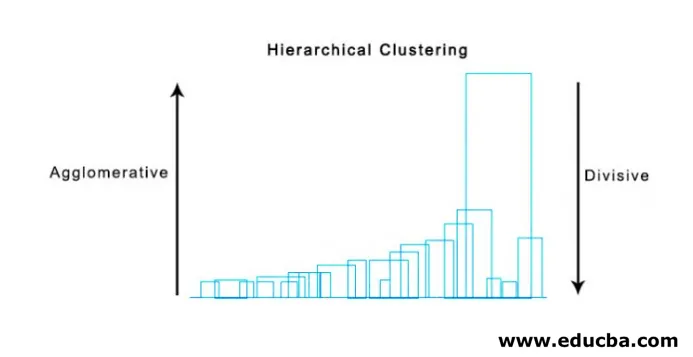
En super nyttig metode til at visualisere hierarkisk klynge, som hjælper i erhvervslivet, er Dendogram. Dendogrammer er trælignende strukturer, der registrerer sekvensen af sammenlægninger og opdelinger, i hvilke den lodrette linje repræsenterer afstanden mellem klyngerne, afstanden mellem lodrette linjer og afstanden mellem klyngerne er direkte proportional, dvs. mere afstanden mere klyngerne er sandsynligvis ikke forskellig.
Vi kan bruge dendogrammet til at bestemme antallet af klynger, bare tegne en linje, der krydser med en længste lodrette linje på dendogrammet, et antal lodrette linjer, der krydses, vil være antallet af klynger, der skal overvejes.
Nedenfor er eksemplet Dendogram.
Der er temmelig enkle og direkte pythonpakker, og det er funktioner til at udføre hierarkisk klynger og plot dendogrammer.
- Hierarkiet fra scipy.
- Cluster.hierarchy.dendogram til visualisering.
Almindelige scenarier, hvor hierarkisk klynge anvendes
- Kundesegmentering til markedsføring af produkter eller tjenester.
- Byplanlægning til at identificere steder at bygge strukturer / tjenester / bygning.
- Social netværksanalyse, for eksempel identificere alle MS Dhoni fans for at annoncere hans biopic.
Fordele ved hierarkisk klynge
Fordelene er givet nedenfor:
- I tilfælde af delvis klynge som k-middel, skal antallet af klynger være kendt forud for klynger, hvilket ikke er muligt i praktiske anvendelser, medens der i hierarkisk klynge ikke kræves forudgående viden om antallet af klynger.
- Hierarkisk klynge udsender et hierarki, dvs. en struktur mere informativ end det ustrukturerede sæt af de flade klynger, der er returneret ved delvis klynge.
- Hierarkisk klynger er let at implementere.
- Viser resultater i de fleste af scenarierne.
Konklusion
Type klynge gør den store forskel, når data præsenteres, hvor hierarkisk klynge er mere informativ og let at analysere er mere foretrukket end delvis klynge. Og det er ofte forbundet med varmekort. Ikke at glemme attributter, der er valgt til at beregne lighed eller forskellighed, overvejende påvirker både klynger og hierarki.
Anbefalede artikler
Dette er en guide til hierarkisk klynge. Her diskuterer vi introduktionen, fordelene ved Hierarkisk Clustering og Common Scenarios, hvor Hierarchical Clustering bruges. Du kan også gennemgå vores andre foreslåede artikler for at lære mere–
- Clustering algoritme
- Klynge i maskinlæring
- Hierarkisk klynge i R
- Clustering Methods
- Sådan fjernes hierarki i Tableau?