

Introduktion til RDBMS-interviewspørgsmål og svar
Så hvis du forbereder dig på et jobsamtale i RDBMS. Jeg er sikker på, at du vil vide de mest almindelige 2019 RDBMS-interview Spørgsmål og svar, der vil hjælpe dig med at knække RDBMS-interviewet med lethed. Nedenfor er listen over top RDBMS Interview Spørgsmål og svar til din redning.
Derfor har vi en tendens til at tilføje top 2019 RDBMS Interview Spørgsmål, der hovedsageligt stilles i et interview
1.Hvad er forskellige funktioner i en RDBMS?
Svar:
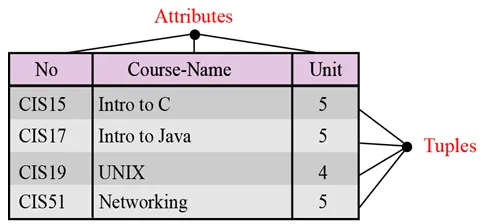
Navn. Hver relation i en relationel database skal have et navn, der er unikt blandt alle andre relationer.
Egenskaber. Hver kolonne i en relation kaldes en attribut.
Tupler. Hver række i en relation kaldes en tuple. En tuple definerer en samling af attributværdier.
2.Forklar ER-model?
Svar:
ER-model er en entitetsforholdsmodel. ER-modellen er baseret på en reel verden, der består af enheder og relationsobjekter. Enheder er illustreret i en database med et sæt attributter.
3. Definer objektorienteret model?
Svar:
Objektorienteret model er baseret på samlinger af objekter. Et objekt rummer værdier, der er gemt i forekomstvariabler inde i objektet. Objekter med en identisk type værdier og nøjagtigt de samme metoder er samlet i klasser.
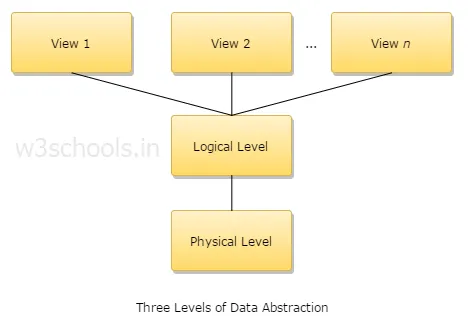
4. Forklar tre niveauer af dataabstraktion?
Svar:
1. Fysisk niveau: Dette er det laveste niveau for abstraktion, og det beskriver, hvordan data gemmes.
2. Logisk niveau: Det næste abstraktionsniveau er logisk, det beskriver, hvilken type data, der er gemt i en database, og hvad der er forholdet mellem disse data.
3. Visningsniveau: Det højeste abstraktionsniveau, og det beskriver den eneste hele database.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5.Hvad er forskellige Codds 12 regler for relationel database?
Svar:
Codds 12 regler er et sæt af tretten regler (nummereret nul til tolv) foreslået af Edgar F. Codd.
Codd's regler: -
Regel 0: Systemet skal kvalificeres som relationelt, som en database og også som et styringssystem.
Regel 1: Informationsreglen: Hver eneste information i databasen skal repræsenteres unikt, navnlig navneværdier i kolonnepositioner inden for en anden række i en tabel.
Regel 2: Den garanterede adgangsregel: Alle data skal være indgribende. Det siger, at enhver skalærværdi i databasen skal være korrekt / logisk adresserbar.
Regel 3: Systematisk behandling af nulværdier: DBMS skal tillade, at hver tuple forbliver nul.
Regel 4: Aktiv online katalog (databasens struktur) baseret på den relationelle model: Systemet skal understøtte en online, relationel osv. Struktur, som er indtrængende for tilladte brugere ved hjælp af deres almindelige forespørgsel.
Regel 5: Den omfattende datainterflåge: Systemet skal hjælpe mindst et relationelt sprog, der:
1.Har en lineær syntaks
2.Hvad kan bruges som både interaktivt og inden for applikationsprogrammer,
3.Det understøtter data definition operationer (DDL), data manipulation operations (DML), sikkerheds- og integritetsbegrænsninger og transaktionsstyring operationer (begynde, forpligte og rollback).
Regel 6: Reglen om opdatering af visningen : Alle visninger, der teoretisk forbedres, skal kunne opgraderes af systemet.
Regel 7: Indsæt, opdater og slet på højt niveau: Systemet skal understøtte indsætte, opdatere og slette operatører.
Regel 8: Fysisk datauafhængighed: Ændre det fysiske niveau (hvordan dataene gemmes, ved hjælp af arrays eller sammenkædede lister osv.) Skal ikke kræve en ændring af en applikation.
Regel 9: Uafhængighed af logiske data: Ændring af det logiske niveau (tabeller, kolonner, rækker osv.) Må ikke kræve en ændring af et program.
Regel 10: Integritetsuafhængighed: Integritetsbegrænsninger skal identificeres individuelt fra applikationsprogrammer og gemmes i kataloget.
Regel 11: Distributionsuafhængighed: Distributionen af dele af en database til forskellige placeringer skal ikke være synlig for brugere af databasen.
Regel 12: Nonsubversionsreglen: Hvis systemet leverer et lavt niveau (dvs. poster) -interface, kan denne grænseflade ikke bruges til at undergrave systemet.
6. Hvad er normalisering? og hvad der forklarer forskellige normaliseringsformer.
Svar:
Normalisering af databaser er en proces til organisering af data for at minimere dataredundans. Hvilket igen sikrer datakonsistens. Der er mange problemer forbundet med dataredundans, såsom spild af diskplads, datakonsistens, DML (Data Manipulation Language) forespørgsler bliver langsomme. Der er forskellige normaliseringsformer: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Dataene i hver søjle skal være flere atomværdier adskilt af et komma. Tabellen indeholder ikke gentagne kolonnegrupper. Identificer hver post unikt ved hjælp af den primære nøgle.
2. 2NF: - Tabellen skal matche alle betingelserne for 1NF og flytte overflødige data til en separat tabel. Desuden skaber det et forhold mellem disse tabeller ved hjælp af fremmede nøgler.
3. 3NF: - for en 3NF-tabel skal opfylde alle betingelserne for 1NF og 2NF. 3NF indeholder ikke attributter, der delvist er afhængige af den primære nøgle.
7. Definer primærnøgle, fremmed nøgle, kandidatnøgle, supernøgle?
Svar:
Primær nøgle: primær nøgle er den nøgle, der ikke tillader duplikatværdier og nulværdier. En primær nøgle kan defineres på kolonniveau eller tabelleniveau. Kun en primær nøgle pr. Tabel er tilladt.
Fremmed nøgle: Fremmed nøgle tillader kun de værdier, der findes i den refererede kolonne. Det tillader duplikat- eller nullværdier. Det kan defineres som kolonniveau eller tabelleniveau. Det kan henvise til en kolonne med en unik / primær nøgle.
Kandidatnøgle: En kandidatnøgle er minimum supernøgle, der er ingen ordentlig undergruppe af kandidatnøgleegenskaber kan være en supernøgle.
Supernøgle : En supernøgle er et sæt attributter i et relationsskema, som alle attributter for skemaet er delvist afhængige af. Ingen to rækker kan have den samme værdi af supernøgleattributter.
8.Hvad er en anden type indeks?
Svar:
Indekser er: -
Clustered index: - Det er det indeks, hvorpå data fysisk gemmes på disken. Derfor kan der kun oprettes et samlet indeks til en databasetabel.
Ikke-klynget indeks: - Det definerer ikke fysiske data, men det definerer en logisk rækkefølge. Typisk oprettes B-træ eller B + -træ til dette formål.
9.Hvad er fordelene ved RDBMS?
Svar:
• Kontrol af redundans.
• Integritet kan håndhæves.
• Inkonsekvens kan undgås.
• Data kan deles.
• Standard kan håndhæves.
10.Navn nogle undersystemer af RDBMS?
Svar:
Input-output, sikkerhed, sprogbehandling, lagerstyring, logning og gendannelse, distributionskontrol, transaktionskontrol, hukommelsesstyring.
11.Hvad er Buffer Manager?
Svar:
Buffer Manager formår at indsamle data fra disklagring til hovedhukommelse og beslutte, hvilke data der skal være i cachehukommelse for hurtigere behandling.
Anbefalet artikel
Dette har været en guide til Liste over RDBMS-interviewspørgsmål og svar, så kandidaten nemt kan nedbryde disse RDBMS-interviewspørgsmål. Du kan også se på de følgende artikler for at lære mere -
- De vigtigste spørgsmål om dataanalysesamtaler
- 13 Fantastiske databasetestintervjuespørgsmål og svar
- Top 10 Designmønster Interviewspørgsmål og svar
- 5 Nyttige SSIS-interviewspørgsmål og svar