
Introduktion til Hive Group af
Grupper efter som navnet antyder, vil den gruppere posten, der opfylder visse kriterier. I denne artikel skal vi se på gruppen efter HIVE. I ældre RDBMS som MySQL, SQL osv. Er gruppe efter en af de ældste klausuler, der bruges. Nu har den fundet sin plads på en lignende måde i filbaseret datalagring, der kendt er HIVE.
Vi ved, at Hive har overgået mange ældre RDBMS i håndtering af enorme data, uden at der er brugt en krone på leverandører til at vedligeholde databaserne og serverne. Vi har bare brug for at konfigurere HDFS til at håndtere bikub. Generelt flytter vi til tabeller, fordi slutbrugeren kan fortolke fra dens struktur og kan forespørge, da filer vil være klodsede for dem. Men vi måtte gøre dette ved at betale leverandørerne for at levere servere og vedligeholde vores data i form af tabeller. Så Hive tilvejebringer den omkostningseffektive mekanisme, hvor den drager fordel af filbaserede systemer (den måde, hvor bikuben gemmer sine data) såvel som tabeller (tabelstruktur for slutbrugerne at spørge efter).
Gruppér efter
Grupper ved hjælp af de definerede kolonner fra Hive-tabellen til at gruppere dataene. Overvej ligesom at du har en tabel med folketællingsdata fra hver by i alle de stater, hvor bynavn og statsnavn er en af kolonnerne. Nu i forespørgslen, hvis vi grupperer efter stater, vil alle data fra forskellige byer i en bestemt stat blive grupperet sammen, og man kan let visualisere dataene bedre nu inden den måde, gruppen blev anvendt på.
Syntaks for Hive Group af
Den generelle syntaks for gruppen efter klausul er som nedenfor:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
eller for enklere forespørgsler,
from Group By
Select department, count(*) from the university.college Group By department;
Her henviser afdelingen til en af kolonnerne i kollegitabellen, der findes i universitetsdatabasen, og dens værdi er forskellige inden for afdelinger som kunst, matematik, ingeniørarbejde osv. Lad os nu se et eksempel for at demonstrere gruppe efter.
Jeg har oprettet et eksempel på tabel deck_of_cards for at demonstrere gruppen efter. Dens oprettelse af tabelopgørelse er som følger:
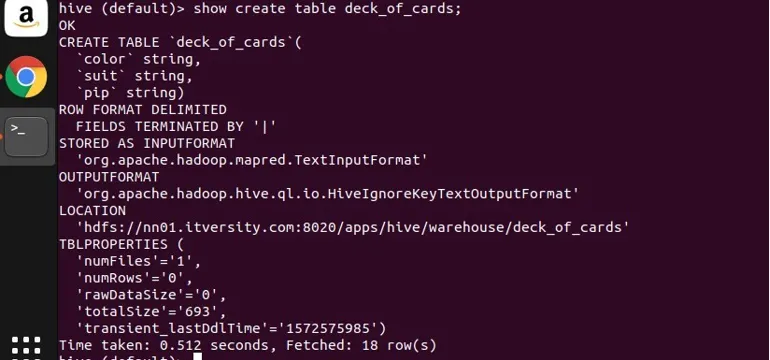
du kan se ovenfra, at det har tre strengskolonner farve, dragt og pip. Lad mig skrive en forespørgsel for at gruppere dataene efter deres farve og få antallet.
select color, count(*) from deck_of_cards group by color;
Hive tager dybest set ovenstående forespørgsel for at konvertere den til kortreduktionsprogrammet ved at generere tilsvarende java-kode og jar-fil og derefter køre. Denne proces kan tage lidt tid, men den kan bestemt håndtere store data sammenlignet med traditionel RDBMS. Se nedenstående skærmbillede med den detaljerede log for udførelse af ovenstående forespørgsel.
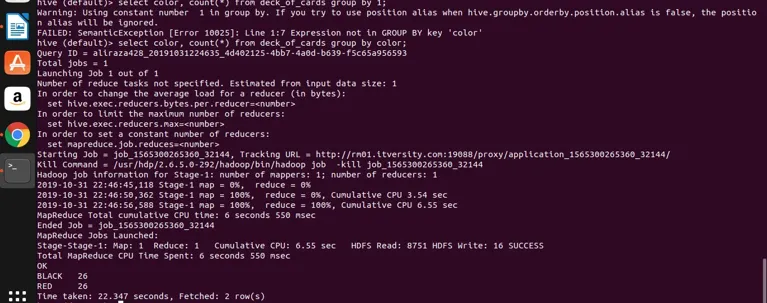
du kan se, at BLACK er 26 og RED er 26.
Lad os nu anvende gruppering på to kolonner (farve og sort og få gruppetælling) og se resultatet nedenfor.
Select color, suit, count(*) from deck_of_cards group by color, suit
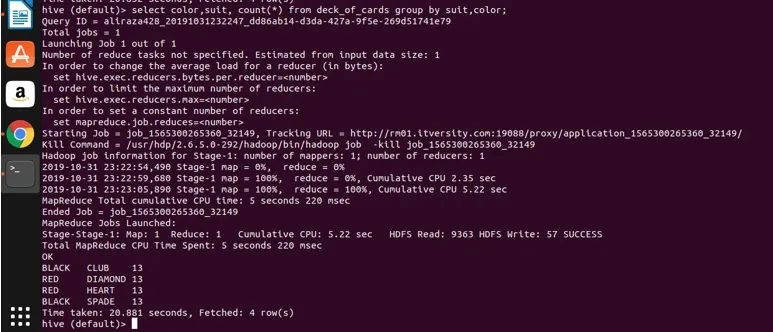
Grundlæggende er der fire forskellige grupper over Club, Spade, der har farve sort og Diamond og hjerte, der er farverøde.
Gemme resultatet fra gruppe efter årsag i en anden tabel
Hive også som enhver anden RDBMS giver funktionen til at indsætte dataene med oprette tabelopgørelser. Lad os se på at gemme resultatet fra et udvalgt udtryk ved hjælp af en gruppe ved i en anden tabel. Lad mig bruge ovenstående forespørgsel, hvor jeg har brugt to kolonner i gruppe efter.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
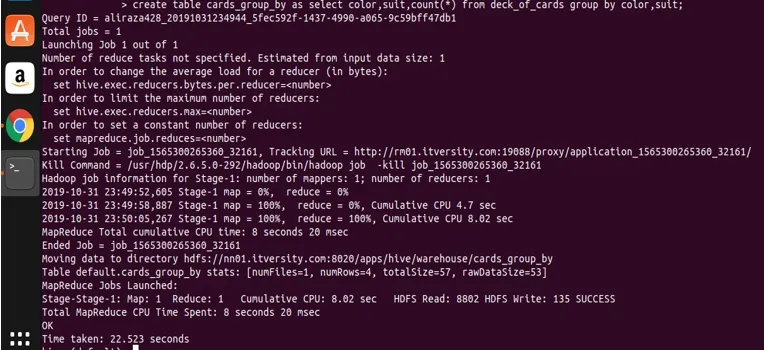
Lad os nu forespørge på den oprettede tabel for at se og validere dataene.

Lad os nu begrænse resultatet af gruppen ved at bruge klausul. Som vist i den generiske syntaks kan vi anvende en begrænsning på gruppen ved at bruge. Her bruger jeg tabellen ordser_items, og dens struktur er som følger af beskrivelsen.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
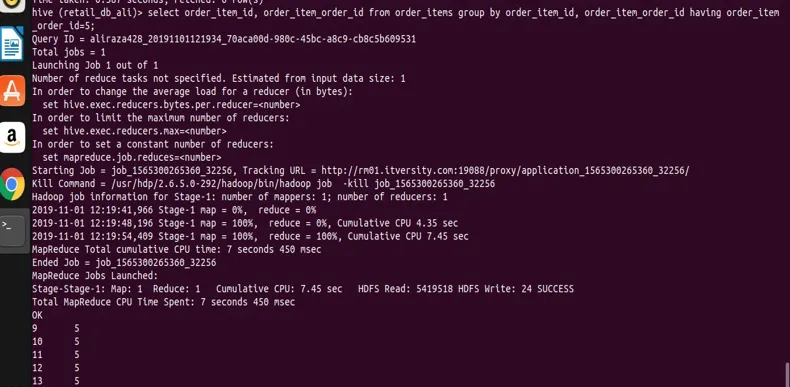
fra resultatet kan du se skærmbilledet, at vi kun har poster med order_item_order_id værdi 5.
Gruppe efter Sammenfatning med sag
Lad os nu se på lidt komplekse forespørgsler, der involverer CASE-erklæringer med gruppen af. Vi anvender dette på order_items-tabellen. Vi vil se nedenfor, at vi kan kategorisere de ikke-samlede kolonner, som vi ikke kan anvende gruppen direkte på.
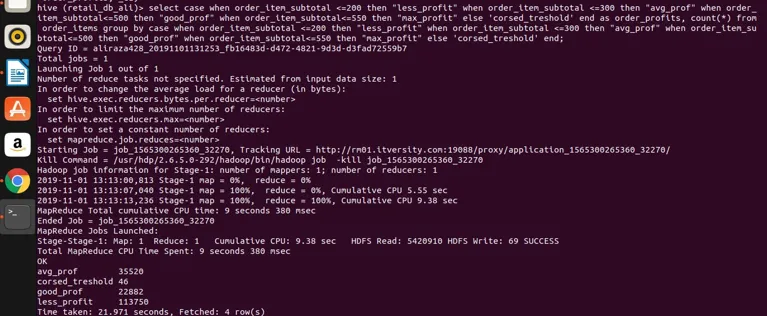
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
lad os køre det i bikuben for at få resultater
Konklusion - Hive Group af
så vi kan se, at vi har grupperet order_item_subtotal i fire forskellige kategorier (hvis du bemærker, at order_item_subtotal er en ikke-samlet kolonne og direkte gruppe ved ikke kan anvendes på den), og vi har grupperet dem sammen og fået deres antal også de værdier, der tilfredsstiller området som defineret i det valgte udtryk. Her er den enkle regel, hvis kolonnen ikke er samlet, og vores udvalgsudtryk er komplekst, uanset hvad der er i det valgte udtryk, der også skal være til stede i gruppen ved udtryk. Så vi har set, hvordan en berømt klausul RDBMS klausulgruppe af også kan anvendes på Hive uden nogen begrænsninger. Det kan anvendes på enkle udvalgte udtryk. Samle og filtrere udtryk, slutte også til udtryk og komplekse CASE-udtryk.
Anbefalede artikler
Dette er en guide til Hive Group By. Her diskuterer vi gruppen efter, syntaks, eksempler på bikubegruppen med forskellige betingelser og implementering. Du kan også se på de følgende artikler for at lære mere -
- Deltager i Hive
- Hvad er en bikube?
- Hive Arkitektur
- Hive-funktion
- Hive ordre af
- Hive installation
- Top 6 typer sammenføjninger i MySQL med eksempler