
Introduktion til AWS-datapipeline
Data vokser eksponentielt dag for dag og bliver vanskelige at håndtere sammenlignet med fortiden. Vi har brug for værktøjer og tjenester til at administrere vores data effektivt og til en billigere pris, der er hvor AWS Data Pipeline kommer i tankerne. Det handler ikke kun om at gemme data, men du er nødt til at analysere, behandle, omdanne dataene til den ønskede form på samme sted, alt dette kan opnås med AWS Data Pipeline.
Behov for datapipeline
Lad os prøve at forstå behovet for datapipeline med eksemplet:
Eksempel 1
Vi har et websted, der viser billeder og gifs på grundlag af brugersøgninger eller filtre. Vores primære fokus er på visning af indhold. Der er visse mål at nå, som er som følger:
- Forbedring af indholdslevering: Serverer det, som brugerne ønsker effektivt og hurtigt nok.
- Håndter applikationen effektivt: Lagring af brugerdata samt webstedslogfiler til senere analyseformål.
- Forbedre forretningen: Brug af lagrede data og analyser tager beslutningen om at gøre forretningen bedre til en billigere pris.
Eksempel 2
Der er visse flaskehalse, der skal tages hånd om for at nå målene:
- Den enorme mængde data i forskellige formater og forskellige steder, hvilket gør behandling, lagring og migrering af data kompleks.
Forskellige datalagringskomponenter til forskellige datatyper:
- Mulige realtidsdata for de registrerede brugere: Dynamo DB .
- Web-serverlogfiler for potentielle brugere: Amazon S3 .
- Demografidata og loginoplysninger: Amazon RDS.
- Sensordata og tredjeparts datasæt: Amazon S3.
Løsninger
- Gennemførbar løsning: Vi kan se, at vi er nødt til at håndtere forskellige typer værktøjer til at konvertere data fra ustruktureret til struktureret til analyse. Her skal vi bruge forskellige værktøjer til at gemme data og igen til at konvertere, analysere og gemme behandlede data. Ikke en omkostningseffektiv løsning.
- Optimal løsning: Brug en datapipeline, der håndterer behandling, visualisering og migrering. Datapipeline kan være nyttig ved migrering af data fra forskellige steder, også analysere data og behandling på samme sted på dine vegne.
Hvad er AWS-datapipeline?
AWS Data Pipeline er dybest set en webtjeneste, der tilbydes af Amazon, som hjælper dig med at transformere, behandle og analysere dine data på en skalerbar og pålidelig måde samt lagring af behandlede data i S3, DynamoDb eller din lokale database.
- Med AWS-datapipeline kan du nemt få adgang til data fra forskellige kilder.
- Transformere og behandle disse data på skala.
- Effektiv overførsel af resultater til andre tjenester såsom S3, DynamoDb-tabel eller lokal datalager.
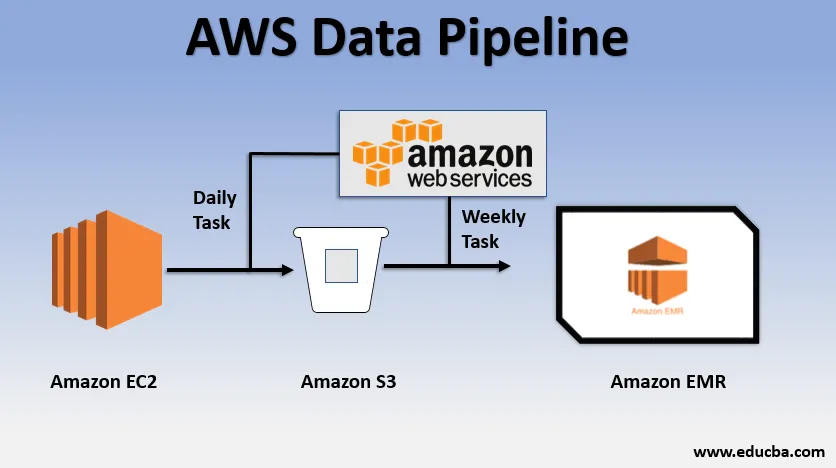
Grundlæggende anvendelseseksempel på datapipeline
- Vi kunne have et websted implementeret over EC2, som genererer logfiler hver dag.
- En simpel daglig opgave kunne kopieres logfiler fra E2 og opnå dem til S3-spanden.
- En ugentlig opgave kunne være at behandle dataene og starte dataanalyse over Amazon EMR for at generere ugentlige rapporter på grundlag af alle indsamlede data.
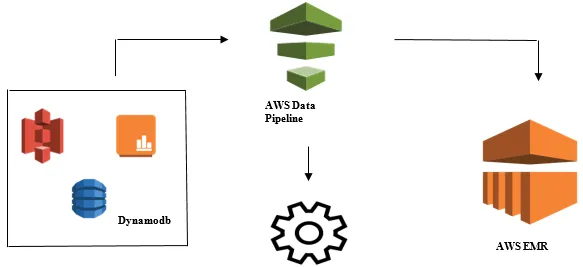
Lancering af dataanalyse med AWS-datapipeline
- Indsamling af data fra forskellige datakilder som - S3, Dynamodb, On-site, sensordata osv.
- Udførelse af transformation, behandling og analyse på AWS EMR for at generere ugentlige rapporter.
- Ugentlig rapport gemt i Redshift, S3 eller på stedet-databasen.
Fordele ved AWS-datapipeline
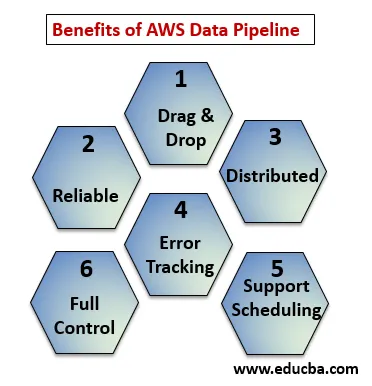
Nedenfor punkterne forklarer fordelene ved AWS Data Pipeline:
- Træk og slip konsol, som er let at forstå og bruge.
- Distribueret og pålidelig infrastruktur: Datarørledninger kører på skalerbare tjenester og er pålidelige, hvis en fejl eller opgave mislykkes, det kan indstilles til at prøve igen.
- Understøtter planlægning og fejlsporing: Du kan planlægge dine opgaver og spore dem, hvad der blev mislykket og succes.
- Distribueret: Kan køres parallelt på flere maskiner eller på en lineær måde.
- Fuld kontrol over beregningsressourcer som EC2, EMR-klynger.
AWS-datapipelinekomponenter
Nedenfor er komponenterne i AWS Data Pipeline:
1. Definition af rørledning
Konverter din forretningslogik til AWS-datapipeline.
- Datanoder : Indeholder navn, placering, format for datakilde, det kan være (S3, dynamodb, lokalt)
- Aktiviteter : Flyt, transformer eller udfør forespørgsler på dine data.
- Planlæg : Planlæg dine daglige eller ugentlige aktiviteter.
- Forudsætning : Betingelser som for at starte planlægning kontrollere datatilgængelighed ved kilden.
- Ressourcer : Beregn ressourcer EC2, EMR.
- Handlinger : Opdatering om datapipeline, afsendelsesmeddelelser, triggeralarm.
2. Rørledninger
Her planlægger og kører du opgaverne til at udføre definerede aktiviteter.
- Omponenter til rørledning C : Rørledningskomponenter er de samme som komponenterne i rørledningsdefinitionen.
- Forekomster: Under kørsel af opgaver samler AWS alle komponenterne for at oprette visse handlinger, der kan håndteres. Sådanne tilfælde har al information om specifikke opgaver.
- Forsøg: Vi har allerede drøftet, hvor pålidelig datapipeline er med dens forsøgsmekanismer. Her indstiller du, hvor mange gange du vil prøve igen på opgaven, hvis den mislykkes.
3. Task Runner
Beder eller afstemmer om opgaver fra AWS-datapipeline og udfører derefter disse opgaver.
AWS-datapipelinipriser
Nedenfor punkterne forklarer AWS Data-pipeline-prissætning:
1. Gratis niveau
Du kan komme i gang med AWS Data Pipeline gratis som en del af AWS gratis brugsniveau. Nye tilmeldingskunder får hver måned nogle gratis fordele i et år:
- 3 Forudsætninger for lavfrekvens, der kører på AWS uden nogen opladning.
- 5 Aktiviteter med lav frekvens, der kører på AWS uden beregning.
2. Lav frekvens
Lavfrekvens menes at køre en gang på en dag eller mindre. Datapipeline følger den samme faktureringsstrategi som andre AWS-webtjenester, dvs. faktureret for din brug. Det faktureres hvor ofte dine opgaver, aktiviteter og forudsætninger kører hver dag, og hvor de kører (AWS eller på stedet). Højfrekvente aktiviteter er planlagt til at køre mere end en gang om dagen.
Eksempel: Vi kan planlægge en aktivitet, der skal køres hver time og behandle webstedets logfiler, eller det kan være hver 12. time. Der henviser til, at lavfrekvente aktiviteter er de, der kører en gang om dagen eller mindre, hvis forudsætningerne ikke er opfyldt. Inaktive rørledninger har enten inaktive, ventende og afsluttede tilstande.
3. Prisfastsættelse af AWS-datapipeline vist Regionvis
Region nr. 1: US East (N.Virginia), US West (Oregon), Asia Pacific (Sydney), EU (Irland)
| Høj frekvens | Lav frekvens | |
| Aktiviteter eller forudsætninger, der løber over AWS | $ 1, 00 per måned | $ 0, 06 pr. Måned |
| Aktiviteter eller forudsætninger, der kører på stedet | $ 2, 50 per måned | $ 1, 50 per måned |
| Inaktive rørledninger: $ 1, 00 pr. Måned |
Region nr. 2: Asien og Stillehavet (Tokyo)
| Høj frekvens | Lav frekvens | |
| Aktiviteter eller forudsætninger, der løber over AWS | $ 0.9524 pr. Måned | $ 0, 5715 per måned |
| Aktiviteter eller forudsætninger, der kører på stedet | $ 2.381 pr. Måned | $ 1, 4286 pr. Måned |
| Inaktive rørledninger: $ 0.9524 pr. Måned |
Rørledningen, som et dagligt job, dvs. en lavfrekvensaktivitet på AWS til at flytte data fra DynamoDB-tabel til Amazon S3, vil koste $ 0, 60 pr. Måned. Hvis vi tilføjer EC2 til at producere en rapport baseret på Amazon S3-data, ville de samlede rørledningsomkostninger være $ 1, 20 pr. Måned. Hvis vi kører denne aktivitet hver 6. time, koster det $ 2, 00 pr. Måned, for det ville være en højfrekvensaktivitet.
Konklusion
AWS Data Pipeline er en meget praktisk løsning til styring af de eksponentielt voksende data til en billigere pris. Det er meget pålideligt såvel som skalerbart i henhold til din brug. For ethvert forretningsbehov, hvor det handler med en stor datamængde, er AWS Data Pipeline et meget godt valg at nå alle vores forretningsmæssige mål.
Anbefalede artikler
Dette er en guide til AWS-datapipeline. Her diskuterer vi behovene for datapipeline, hvad er AWS-datapipeline, dets komponent og prisoplysninger. Du kan også gennemgå vores andre relaterede artikler for at lære mere -
- AWS EBS
- AWS-databaser
- Hvad er AWS EC2?
- Fordele ved datavisualisering
- Top 7 konkurrenter af AWS med funktioner
- Lær listen over Amazon Web Services-funktioner