

Forskellen mellem Apache Hive og Apache HBase -
Apache Hive-historien begynder i 2007, hvor ikke Java-programmør er nødt til at kæmpe, mens han bruger Hadoop MapReduce. Forskere og udvikler forudsagde, at i morgen er en æra af Big Data. Allerede forskellige dataformater som strukturerede, semistrukturerede og ustrukturerede opstod. Selv Facebook kæmpede med den større mængde databehandling. Forskere på Facebook introducerede Apache Hive til databehandling på Hadoop Cluster. Facebook var det første firma, der kom med Apache Hive.
Apache HBase-historien begynder i 2006, da den San Francisco-baserede opstart Powerset forsøgte at opbygge en naturlig sprogsøgemaskine til internettet. HBase er en implementering af Googles Bigtable. Har vi nogensinde indset, hvorfor der var behov for at komme med endnu en lagerarkitektur? Relational Database Management System har eksisteret siden begyndelsen af 1970'erne. Der er mange anvendelsessager, hvor relationelle databaser perfekt giver mening, men for nogle specifikke problemer passer den relationelle model ikke særlig godt.
Lad mig forklare mere om Apache Hive og Apache HBase.
Forskelle mellem Apache Hive og Apache HBase
Apache Hive er et Apache open-source-projekt bygget oven på Hadoop til forespørgsel, opsummering og analyse af store datasæt ved hjælp af en SQL-lignende interface. Apache Hive leverer et SQL-lignende sprog kaldet HiveQL, som transparent konverterer forespørgsler til MapReduce til udførelse på store datasæt, der er gemt i Hadoop Distribueret filsystem (HDFS). Apache Hive er en Hadoop-klynkomponent, der normalt distribueres af dataanalytikere. Apache hive bruges til batchbehandling af store ETL-job. Apache Hive understøtter også batch-SQL-forespørgsler på meget store datasæt. Apache Hive øger skemaets designfleksibilitet og også dataserialisering og deserialisering. Apache Hive understøtter ikke Online Transaction Processing (OLTP), fordi hive ikke understøtter forespørgsler i realtid og opdateringer på rækkeniveau.
Apache HBase er en open source NoSQL-database, der giver realtid, læse- og skriveadgang til store datasæt. NoSQL er ikke-relationel database. Apache HBase er distribueret søjleorienteret database, der kører oven på Hadoop Distribueret filsystem (HDFS). Så HBase bringer fordelene ved NoSQL til Hadoop. Apache HBase giver mulighed for tilfældig adgang til data, der findes i HDFS. Det udnytter den fejltolerance, der leveres af HDFS. Brugeren kan gemme dataene i HDFS enten direkte eller gennem HBase.
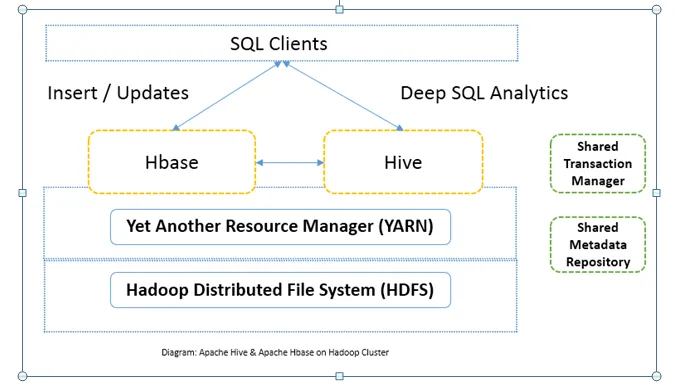
Sammenligning mellem hoved og hoved mellem Apache Hive vs Apache HBase (Infografik)
Nedenfor er top 12-forskellen mellem Apache Hive og Apache HBase

Nøgleforskelle - Apache Hive vs Apache HBase
Nedenfor er lister over punkter, der beskriver de vigtigste forskelle mellem Apache Hive og Apache HBase:
- Apache HBase er en database, mens Apache Hive er en databasemotor.
- Apache Hive bruges hovedsageligt til batchbehandling (OLAP), mens Apache HBase hovedsageligt bruges til transaktionsbehandling (OLTP).
- Apache Hive udfører de fleste af SQL-forespørgsler, mens Apache HBase ikke tillader SQL-forespørgsler direkte.
- Apache Hive understøtter ikke operationer på postniveau som opdatering, indsættelse og sletning, mens Apache HBase understøtter postniveauoperationer som opdatering, indsættelse og sletning.
- Apache Hive kører på toppen af MapReduce, mens Apache HBase kører oven på Hadoop Distribueret filsystem (HDFS).
Apache Hive forespørger filerne ved at definere en virtuel tabel og køre HQL-forespørgsler oven på den. Det er en proces, hvor filer praktisk talt er forbundet til en tabel som struktur og bruger kan udføre Hive Query Language (HQL) og disse forespørgsler konverteres til MapReduce Job by Hive. Brugeren behøver ikke at skrive MapReduce-job, HQL-forespørgsler konverteres internt til jar-filer, og disse jar-filer bliver implementeret på datasæt.
Mens der er i Apache HBase, er tabeller opdelt i regioner og serveres af regionens servere. Yderligere regioner er lodret opdelt af kolonnefamilier i butikker, og butikker gemmes som filer i HDFS.
Hvornår skal du bruge Apache Hive:
- Krav til datalagring
- Analytiske forespørgsler
- Dataanalyse, der er bekendt med SQL
Hvornår skal du bruge Apache HBase:
- Hurtig og interaktiv databehandling
- Forespørgsler i realtid
- Hurtige opslag
- Behandling af serversiden
- Tilfældig læse / skriveadgang til Big Data
- Applikationens skalerbarhed
Apache Hive kan bruges til at beregne tendenser og logfiler på e-handelswebsiden for en bestemt varighed, region eller tidszone. Det kan bruges til at behandle batchforespørgsel over historiske data, mens Apache HBase kan bruges af Facebook eller LinkedIn til meddelelser og realtidsanalyse. Det kan også bruges til at tælle likes.
Apache Hive vs Apache HBase sammenligningstabel
Jeg diskuterer større artefakter og skelner mellem Apache Hive og Apache HBase.
| Apache Hive | Apache HBase | |
| Databehandling | Apache Hive bruges til
batchbehandling dvs. Online Analytical Processing (OLAP) | Apache HBase bruges til transaktionsbehandling, dvs. Online Transactionional Processing (OLTP) |
| Behandlingshastighed | Apache Hive har højere latenstid på grund af at udføre MapReduce-job i baggrunden | Apache HBase fungerer på realtidspørgsmål og meget hurtigere end Apache Hive |
| Kompatibilitet med Hadoop | Apache Hive kører oven på MapReduce | Apache HBase kører på toppen af HDFS |
| Definition | Apache Hive er open source og ligner SQL brugt til analytiske forespørgsler | Apache HBase er open source NoSQL-database, der bruges til realtidspørgsmål |
| Delt metadata | Data oprettet i Apache Hive er automatisk synlige for Apache HBase | Data oprettet i Apache HBase er automatisk synlige for Apache Hive |
| Schema | Apache hive understøtter skema til indsættelse af data i tabeller | Apache HBase er skemafri database. |
| Opdateringsfunktion | Opdateringsfunktionen er kompliceret i Apache Hive | Brugeren kan meget let opdatere dataene i Apache HBase |
| operationer | Operationer i Apache Hive kører ikke i realtid | Operationer i Apache HBase kører i realtid |
| Datatyper | Apache Hive er beregnet til strukturerede og semistrukturerede data | Apache HBase er til ustrukturerede data. |
| Konsistensniveau | Apache hive understøtter en eventuel konsistens | Apache HBase understøtter øjeblikkelig konsistens |
| Partitionsmetoder | Apache Hive understøtter afskærmningsfunktioner | Apache HBase understøtter også afskærmningsfunktioner |
| Data opbevaring | Datoen gemmes i Hive Metastore, Partitioner og Skovle i Apache Hive | Data gemmes i kolonne og rækkevis af tabeller i Apache HBase |
Konklusion - Apache Hive vs Apache HBase
Almindeligvis bruges Apache Hive vs Apache HBase sammen i den samme klynge. Begge kan bruges sammen for at forbedre processorkraften. Da hive forbedrer de analytiske sider af HDFS, mens HBase forbedrer transaktioner i realtid. Brugeren kan bruge Hive som et ETL-værktøj til batchindlæg med dataene i HBase og derefter til at udføre forespørgsler, som yderligere kan sammenføje data, der findes i HBase-tabeller med de data, der allerede er til stede på HDFS. Data kan læses og skrives fra Apache Hive til HBase og tilbage igen. Grænsefladen mellem Apache Hive og Apache HBase er stadig modningsfase. Der er meget mere der kommer. Jeg kan stadig sige, at begge Apache Hive vs Apache HBase gør Hadoop-klyngen mere robust og kraftfuld.
Relaterede artikler:
Dette har været en guide til Apache Hive vs Apache HBase, deres betydning, sammenligning mellem hoved og hoved, nøgleforskelle, sammenligningstabel og konklusion. Du kan også se på de følgende artikler for at lære mere -
- Top 5 Big Data Trends
- 5 udfordringer med Big Data Analytics
- Hvordan knækker Hadoop-udviklerintervjuet?
- 5 udfordringer med Big Data Analytics