
Forskellen mellem BFS VS DFS
Breadth-First Search (BFS) og Deepth First Search (DFS) er to vigtige algoritmer, der bruges til søgning. Breadth-First Search starter sin søgning fra den første knude og bevæger sig derefter over de niveauer, der er tættere på rodnoden, mens Dybde First Search-algoritmen starter med den første knude og derefter afslutter sin sti til slutknudepunktet for den respektive sti. Begge algoritmer kører gennem hver knude under søgningen. Der er skrevet forskellige koder for de to algoritmer for at udføre gennemgangen. De betragtes også som vigtige søgealgoritmer i kunstig intelligens.
I dette emne skal vi lære om BFS VS DFS.
Hvordan fungerer BFS og DFS?
Arbejdsmekanismen for begge algoritmer forklares nedenfor med eksempler. Henvis til dem for en bedre forståelse af den anvendte tilgang.
Eksempel på bredde-første søgning
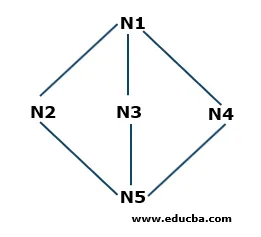
- Trin 1: N1 er rodnoden, så det starter herfra. N1 er forbundet med tre noder N2, N3 og N4. Alle tre noder er ikke besøgt endnu. Så vi starter fra N2 og gemmer det i køen. Så køen, der hedder Q, indeholder kun N2.
Q: N2
- Trin 2: Dernæst er den node, der er forbundet til N1, N3. Da vi gik over eller besøgte noden, gemmer vi den i køen. Så den opdaterede kø er
Q: N3, N2
- Trin 3: Dernæst er noden, der er forbundet til rodnoden, N4. Vi gemmer det i køen.
Q: N4, N3, N2
- Trin 4: Alle de noder, der er forbundet til N1, gemmes i køen. Nu fjerner vi N2 fra køen som pr. First in First Out-princip (FIFO) og finder de noder, der er forbundet til N2, dvs. N5. N5 besøges ikke en gang, så vi opbevarer den i køen.
Q: N5, N4, N3
- Trin 5: Alle knudepunkter besøges, så vi fortsætter med at fjerne knudepunkterne fra køen, indtil den er tom.
Eksempel på dybde Første søgning
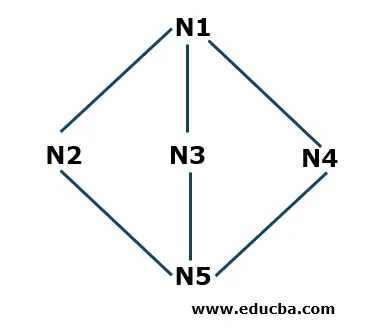
- Trin 1: Vi starter med N1 som startknudepunkt og gemmer den i en stabel S. N1 er forbundet med tre tilstødende knudepunkter N2, N3 og N4. Fra N2 (du kan starte alfabetisk eller numerisk), sætter vi dette i stakken.
S: N2 (øverst), N1
- Trin 2: Nu er de nærliggende knudepunkter til N2 N1 og N5. Da N1 allerede er til stede i stakken, betyder det, at den besøges, så vi tager N5 og lægger den i stakken S.
S: N5 (øverst), N2, N1
- Trin 3: Nu er de nærliggende knudepunkter til N5 N3 og N4. Vi starter vil N3 og sætte den i stakken.
S: N3 (øverst), N5, N2, N1
Nu er N3 forbundet til N5 og N1, som allerede er til stede i stakken, hvilket betyder, at de bliver besøgt, så vi fjerner N3 fra stakken som pr. Last in First Out-princip (LIFO) -princippet.
S: N5 (øverst), N2, N1
- Trin 4: Nu lægger vi den sidste knude, som vi ikke stødte på i hele krydsningen i N4 og lægger den i stakken.
S: N4 (øverst), N5, N2, N1
- Trin 5: Vi overlader nu ikke andre knudepunkter, så vi tjekker i stakken, om der er nogen knudepunkter, der er forbundet med de respektive knudepunkter der findes i den, som ikke er besøgt. Hvis alle de tilsluttede noder besøges, fjerner vi de noder, der findes i stakken. For eksempel har N4 ingen forbindelsesnoder, som vi ikke har kontrolleret, så vi fjerner det fra stakken. Tilsvarende kan vi tjekke for andre noder. Algoritmen stopper, når stakken er tom.
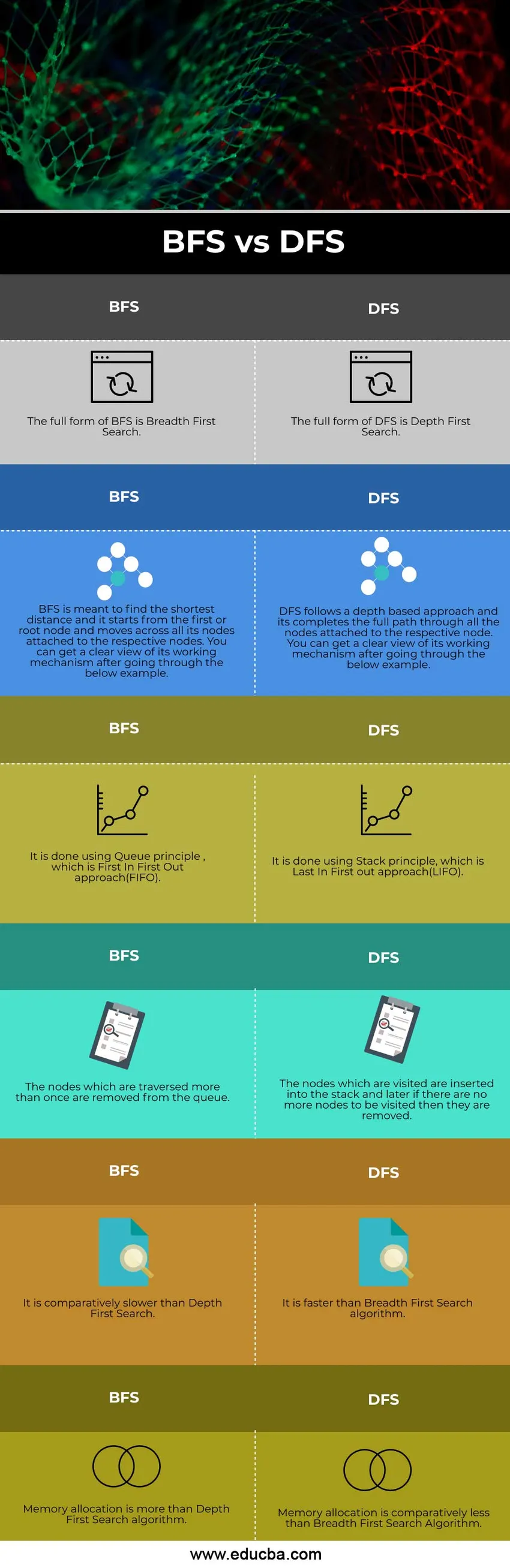
Sammenligning fra head to head mellem BFS VS DFS (Infographics)
Nedenfor er de øverste 6 forskelle mellem BFS VS DFS
Vigtige forskelle mellem BFS og DFS
Lad os diskutere nogle af de vigtigste centrale forskelle mellem BFS vs DFS
- Breadth-First Search (BFS) starter fra rodnoden og besøger alle de respektive noder, der er knyttet til det, mens DFS starter fra rodnoden og afslutter den fulde sti, der er knyttet til noden.
- BFS følger fremgangsmåden til kø, mens DFS følger fremgangsmåden fra Stack.
- Den fremgangsmåde, der bruges i BFS, er optimal, mens processen, der bruges i DFS, ikke er optimal.
- Hvis vores mål er at finde den korteste vej, end BFS foretrækkes frem for DFS.
BFS- og DFS-sammenligningstabel
Lad os diskutere den bedste sammenligning mellem BFS vs DFS
| BFS | DFS |
| Den fulde form af BFS er Breadth-First Search. | Den fulde form af DFS er Depth First Search |
| BFS er beregnet til at finde den korteste afstand, og det starter fra den første eller rodnode og bevæger sig over alle dets knudepunkter, der er knyttet til de respektive knudepunkter. Du kan få et klart overblik over dens arbejdsmekanisme efter at have gennemgået nedenstående eksempel. | DFS følger en dybdebaseret tilgang, og den afslutter den fulde sti gennem alle knudepunkter, der er knyttet til den respektive knude. Du kan få et klart overblik over dens arbejdsmekanisme efter at have gennemgået nedenstående eksempel. |
| Det gøres ved hjælp af køprincippet, som er First In First Out-metoden (FIFO). | Det gøres ved hjælp af Stack-princippet, som er Last In First out-metoden (LIFO). |
| De noder, der gennemskæres mere end én gang, fjernes fra køen. | De noder, der besøges, indsættes i stakken, og senere, hvis der ikke er flere noder, der skal besøges, fjernes de. |
| Det er forholdsvis langsommere end dybde første søgning. | Det er hurtigere end algoritmen Breadth-First Search. |
| Hukommelsesallokering er mere end dybden første søgning algoritme. | Hukommelsesallokering er relativt mindre end algoritmen for bredde-første søgning |
Konklusion
Der er mange applikationer, hvor de ovennævnte algoritmer bruges som maskinlæring eller til at finde kunstige intelligensrelaterede løsninger osv. De bruges hovedsageligt i grafer til at finde ud af, om det er bipartit eller ej, til at detektere cykler eller komponenter, der er forbundet. De betragtes også som vigtige algoritmer til at finde stien eller finde den korteste afstand. Afhængig af virksomhedens krav kan vi bruge to algoritmer. Imidlertid betragtes Breadth-First Search som en optimal måde snarere end Deepth First Search-algoritmen.
Anbefalede artikler
Dette er en guide til BFS VS DFS. Her diskuterer vi BFS VS DFS nøgleforskelle med infografik og sammenligningstabel. Du kan også se på de følgende artikler for at lære mere -
- BFS-algoritme
- TeraData vs Oracle
- Big Data vs Data Warehouse
- Big Data vs Apache Hadoop: Top 4 sammenligning, du skal lære