
Introduktion til R CSV-filer
CSV-filer er vidt brugt til at gemme oplysningerne i tabelformat, hver linje er datapost. For at læse, skrive eller manipulere data i R, skal vi have nogle data tilgængelige hos os. Data kan findes på internettet eller kan indsamles fra forskellige kilder såsom undersøgelser. Ved hjælp af R kan man læse, skrive og redigere de data, der er gemt i et eksternt miljø. R kan læse og skrive data fra forskellige formater som XML, CSV og Excel. I denne artikel vil vi se, hvordan R kan bruges til at læse, skrive og udføre forskellige handlinger på CSV-filer.
Oprettelse af CSV-fil i R
I dette afsnit vil vi se, hvordan en dataramme kan oprettes og eksporteres til CSV-filen i R. I det første opretter vi en dataramme, der består af variabler medarbejder og respektive løn.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
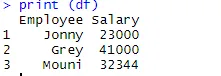
Når datarammen er oprettet, er det tid for at bruge R's eksportfunktion til at oprette CSV-fil i R. For at eksportere datarammen til CSV kan vi bruge nedenstående kode.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
I ovennævnte kodelinje har vi leveret en sti-mappe til vores datarame og gemt dataframe i CSV-format. I ovenstående tilfælde blev CSV-filen gemt på mit personlige skrivebord. Denne særlige fil vil blive brugt i vores tutorial til udførelse af flere operationer.
Læsning af CSV-filer i R
Mens vi udfører analyser med R, er vi i mange tilfælde forpligtet til at læse dataene fra CSV-filen. R er meget pålidelig, mens du læser CSV-filer. I ovenstående eksempel har vi oprettet filen, som vi vil bruge til at læse ved hjælp af kommandoen read.csv. Nedenfor er eksemplet til at gøre det i R.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

Ovenstående kommando læser filen Employee.csv, som er tilgængelig på skrivebordet og viser den i R studio. Header-kommando indebærer, at overskriften stilles til rådighed for datasættet, og sep-kommando indebærer, at dataene adskilles af kommaer.
Skriv CSV-filer i R
Skrivning til CSV-fil er en af de mest nyttige funktionaliteter, der er tilgængelige i R for en dataanalytiker. Dette kan bruges til at skrive en redigeret CSV-fil til en ny CSV-fil for at analysere dataene. Skriv.csv-kommandoen bruges til at skrive filen til CSV.
I nedenstående kode df i den dataramme, som vores data er tilgængelige i, bruges append til at specificere, at den nye fil oprettes i stedet for at tilføje eller overskrive den gamle fil. Tilføj falske antyder, at der oprettes en ny CSV-fil. Sep repræsenterer feltet adskilt med et komma.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
CSV-operationer
CSV-operationer er forpligtet til at inspicere dataene, når de er indlæst i systemet. R har flere indbyggede funktioner til at verificere og inspicere dataene. Disse operationer giver komplette oplysninger om datasættet.
En af de mest anvendte kommandoer er et resume.
> summary(df)
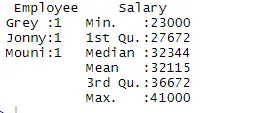
Sammendragskommandoen giver os kolonnevis statistik. Den numeriske variabel er beskrevet på en statistisk måde, der inkluderer statistiske resultater såsom middel, min, median og maks. I ovenstående eksempel er to variabler, der er medarbejder og løn, adskilt, og statistikker for den numeriske variabel, der er løn, vises for os.
Kommando View () bruges til at åbne datasættet i en anden fane og verificere det manuelt.
> View(df)

Str-funktionen giver brugerne flere detaljer angående kolonnen på datasættet. I eksemplet nedenfor kan vi se, at medarbejdervariablen har faktor som datatype og lønnsvariablen har int (heltal) som datatype.
> str(df)

I mange tilfælde bliver vi nødt til at se det samlede antal tilgængelige rækker i tilfælde af det store datasæt, som vi kan bruge kommandoen nrow () til. Se eksemplet nedenfor.
> # to show the total number of rows in the dataset
> nrow(df)

På en lignende måde til at vise det samlede antal kolonner, kan vi bruge kommandoen ncol ()
> ncol(df)

R giver os mulighed for at vise det ønskede antal rækker ved hjælp af kommandoen nedenfor. Når deres antal rækker er tilgængelige i datasættet, kan vi specificere række rækker, der skal vises.
> # to display first 2 rows of the data
> df(1:2, )

Datadrift udføres på det store datasæt. Til illustration har jeg downloadet NI postnummer-open source-datasæt fra internettet.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
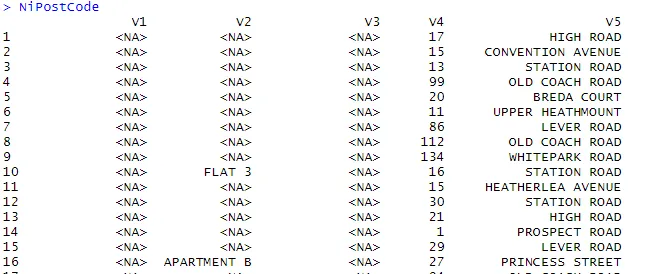
I ovennævnte datasæt kan vi se overskriftenavne mangler, og der er mange nulværdier til stede. Datasættet skal rengøres for at være klar til analyse. I det næste trin får overskrifterne navne i overensstemmelse hermed.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Lad os nu tælle antallet af manglende værdier i dataframmen og derefter fjerne dem i overensstemmelse hermed.
> # count of all missing values
> table(is.na (NiPostCode))

Fra ovennævnte kommando kan vi se det samlede antal emner eller NA i dataframmen er tæt på 5445148. Fjernelse af alle nul-værdier vil resultere i tab af den enorme mængde data, hvorfor det er klogt at fjerne kolonnerne, hvor mere end halvdelen af 50% af data mangler.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Konklusion
I denne tutorial har vi set, hvordan CSV-filer kan oprettes, læses og tilføjes ved hjælp af operationer i R. Vi har lært, hvordan man opretter et nyt datasæt i R og derefter importerer det til CSV-format. Vi har yderligere set flere operationer, såsom at omdøbe header og tælle antallet af rækker og kolonner.
Anbefalede artikler
Dette er en guide til R CSV-filer. Her diskuterer vi oprettelse, læsning og skrivning af CSV-fil i R med CSV-operationer. Du kan også se på den følgende artikel for at lære mere -
- JSON vs CSV
- Data Mining Process
- Karrierer inden for dataanalyse
- Excel vs CSV