

Introduktion til Kafka Tools
Kafka Tools er en samling af forskellige værktøjer, som vi kan administrere vores Kafka Cluster. Værktøjerne er for det meste kommandolinjebaseret, men der findes også UI-baserede værktøjer, som kan downloades og installeres.
Vi kan bruge Kafka-værktøjer til udførelse af forskellige operationer som:
- Liste over de tilgængelige Kafka Clusters og deres mæglere, emner og forbrugere.
- Kan udskrive meddelelserne fra forskellige emner i standardoutput. UI-baserede værktøjer kan bestemt give bedre læsbarhed.
- Tilføj og slip emner fra mæglerne.
- Tilføj nye meddelelser i partitionerne.
- Se alle forskydninger fra vores forbrugere.
- Opret partitioner af vores emner.
- Liste over alle forbrugergrupper, beskriv forbrugergrupperne, slet forbrugergruppeinfo og nulstil forbrugsgruppeforskydninger.
Hvis vi vil bruge et UI-baseret værktøj, kan vi bruge Kafka Tool, som kan downloades fra følgende webside:
http://www.kafkatool.com/download.html
Denne applikation er gratis tilgængelig til personlig brug, men vi er nødt til at købe en licens til kommerciel brug. Den gode ting ved det er dens tilgængelighed til Mac-, Windows- og Linux-systemer.
Top 3 typer Kafka-værktøjer
Kafka-værktøjer er kategoriseret i systemværktøjer og applikationsværktøjer.
1. Systemværktøjer
Systemværktøjer kan køres ved hjælp af følgende syntaks.
Syntaks:
bin/kafka-run-class.sh package.class - - options
Nogle af systemværktøjerne er som følger:
- Kafka Migration Tool: Dette værktøj bruges til at migrere Kafka Broker fra en version til en anden.
- Forbrugeroffsetchecker: Dette værktøj kan vise forbrugergruppe, emne, partitioner, off-set, logSize, ejer for det angivne sæt emner og forbrugergruppe.
- Mirror Maker: Dette værktøj bruges til spejling af en Kafka Cluster til en anden.
2. Replikeringsværktøjer
Dette er dybest set designværktøjer på højt niveau, der leveres til holdbarhed og tilgængelighed.
Nogle af replikeringsværktøjerne er:
- Opret emneværktøj: Dette værktøj bruges til at oprette emner med standardantal partitioner og replikationsfaktor.
- Listemådeværktøj: Dette bruges til at liste informationen til en given liste over emner. Den gode ting ved dette værktøj er, at hvis intet emne allerede er tilgængeligt på kommandolinjen, vil den spørge Zookeeper om at hente listen over emner først og derefter udskrive oplysningerne om dem. Det viser forskellige felter som emne navn, partitioner, leder, kopier osv.
- Tilføj partitionsværktøj: Dette værktøj bruges til at føje partitioner til et emne, der er nødvendigt for at håndtere væksten i datavolumen i emnet. Men bemærk, at vi er nødt til at specificere partitionerne, mens vi opretter emnet. Dette værktøj giver os mulighed for at tilføje manuelle replikker til de tilføjede partitioner.
3. Diverse værktøjer
Lad os nu diskutere nogle diverse værktøjer:
en. Kafka-emner værktøj
Dette værktøj bruges til at oprette, liste, ændre og beskrive emner.
Eksempel: Oprettelse af emne: bin/kafka-topics.sh --zookeeper zk_host:port/chroot --create --topic topic_name --partitions 30 --replication-factor 3 --config x=y
b. Kafka-konsol-forbrugerværktøj
Dette værktøj kan bruges til at læse data fra Kafka-emner og skrive dem til standardoutput
Eksempel: bin/kafka-console-consumer --zookeeper zk01.example.com:8080 --topic topic_name>/code>
c. Kafka-konsol-producent værktøj
Dette værktøj kan bruges til at skrive data til et Kafka-emne fra standardoutput.
Eksempel: bin/kafka-console-producer --broker-list kafka03.example.com:9091 --topic topic_name
d. Kafka-forbruger-grupper værktøj
Dette værktøj kan bruges til at liste alle forbrugergrupper, beskrive en forbrugergruppe, slette forbrugergruppeinfo eller nulstille forbrugsgruppeforskydninger. Dette værktøj bruges hovedsageligt til at beskrive forbrugergrupper og fejlsøge eventuelle problemer med forbrugers offset.
Eksempel: Visning af forskud på en usikret klynge: bin/kafka-consumer-groups --new-consumer --bootstrap-server broker01.example.com:9092 --describe --group group_name
Kafka Arkitektur
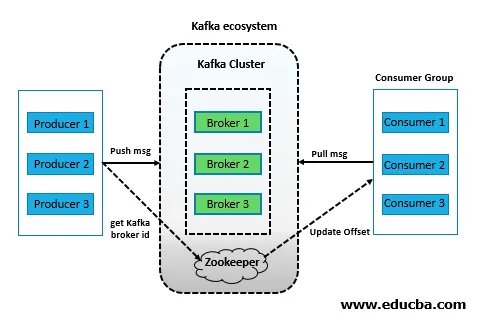
Forskellige komponenter til Kafka-værktøjer
De vigtigste komponenter i Kafka er som følger:
1. Mægler
Hver knude i en Kafka Cluster er en mægler, der gemmer dataene. Der er typisk flere mæglere for at afbalancere belastningen korrekt. En mægler gemmer beskeder i form af emner, som producenter (til skrivning) og forbrugere (til læsning) kan få adgang til. Emner oprettes for at adskille en applikations data fra en anden. Da mæglere er statsløse, har de brug for Zookepers hjælp til at bevare deres klyngestatus. En mægler kan håndtere TBs af meddelelser uden nogen indflydelse på ydelsen. Kafka mægler leder valg er udført af Zookeeper.
2. Producent
Det er enheden, der skubber meddelelser ind i mæglerne. Der kan være flere producenter, der genererer data i en meget høj hastighed og uafhængigt af hinanden. Producenterne modtager ikke en bekræftelse fra mæglerne og sender data til en sats, der kan håndteres af mæglerne. De er i stand til at søge mæglere og begynde at sende meddelelser, så snart mæglerne starter. Producenten er ansvarlig for at vælge, hvilken meddelelse der skal tildeles til hvilken partition inden for emnet. Dette kan gøres på en rund-robin-måde blot for at afbalancere belastning, eller det kan gøres i henhold til en eller anden semantisk partitionsfunktion (sige baseret på en eller anden nøgle i meddelelsen).
3. Zookeeper
Det er enheden, der administrerer og koordinerer mæglerne. Zookeeper giver besked til en producent eller en forbruger i tilfælde af en mæglers tilføjelse eller fiasko. Hver mægler sender hjerteslagsanmodninger til dyreholderen med regelmæssige intervaller, så længe den er i live. Zookeeper opretholder også information om emnerne og forbrugers modregninger.
4. Forbruger
Det er enheden, der læser meddelelserne fra emnerne. En forbruger kan abonnere på og læse fra mere end et emne. En forbruger kan arbejde parallelt med andre forbrugere (i dette tilfælde læses hver partition kun af en forbruger) og danner forbrugergruppe. Det fungerer ikke i synkronisering med producenterne. Forbrugeren skal vedligeholde, hvor mange meddelelser den har læst ved hjælp af partitionsforskydning. Hvis en forbruger accepterer en bestemt partitionsforskydning, indebærer det, at den allerede har fortæret de forudgående meddelelser i partitionen.
Konklusion
I denne artikel har vi lært, hvordan vi kan bruge forskellige Kafka-værktøjer til at styre vores Kafka-klynge effektivt. Vi har også lært om de forskellige komponenter i Kafka økosystem, og hvordan de interagerer med hinanden.
Anbefalede artikler
Dette er en guide til Kafka-værktøjer. Her diskuterer vi typer af Kafka-værktøjer, forskellige komponenter af Kafka sammen med Kafka-arkitektur. Du kan også se på den følgende artikel for at lære mere -
- Top Kafka-applikationer
- Forklaring af Big Data Architecture
- Top Data Science værktøjer
- Forskelle mellem Kafka vs Spark